Ten często aktualizowany przeze mnie wpis, stał się niemalże kompletnym opisem metodyki projektowania oprogramowania. Nie jest to moja metodyka, to metodyka z której ja także korzystam. Artykuł zaopatrzyłem w bogaty spis literatury źródłowej i kilka ciekawych referatów konferencyjnych. Polecam szczególnie moim studentom oraz obecnym i potencjalnym klientom, bo to opis produktu jaki ode mnie dostaną (polecam także wpis: Moja rola w projektach).
Programming is not solely about constructing software—programming is about designing software.
[Programowanie nie polega wyłącznie na tworzeniu oprogramowania – programowanie polega na projektowaniu oprogramowania.]
[zotpressInText item=”{5085975:NZCQDD79}”]
Wprowadzenie
Opisany tu proces modelowania stara sie odpowiedzieć na powyższe pytania.
Często spotykana nazwa: ICONIX, przylgnęła do metod zorientowanych na przypadki użycia za sprawą publikacji Use Case Driven Object Modeling with UML [zotpressInText item=”{5085975:7NUD7FFT}”]. Nie jest to jednak ani patent ani jedyna metoda z użyciem UML. Wielu innych autorów opisuje to standardowe podejście po prostu jako “metody komponentowe projektowania zorientowane na przypadki użycia” [zotpressInText item=”{5085975:IENSXKK5},{5085975:GMJDZZJ4}”] oraz [zotpressInText item=”{5085975:6GN76ZK6}”]. Będę używał nazwy ICONIX w dalszej części tylko dla wygody.
Głównym wyróżnikiem procesów takich jak ICONIX jest wypełnienie luki pomiędzy analizą potrzeb a implementacją. Lukę tę wypełniamy od razu modelując mechanizm realizacji przypadków użycia.

O podobnej porze roku, w 2015 roku pisałem:
W ICONIX można z powodzeniem stosować “czysty” UML
źr.: : ICONIX and Use Case Driven Object Modeling with UML – Jarosław Żeliński IT-Consulting
“The Unified Modeling Language User Guide” autorstwa Grady’ego Boocha, Jamesa Rumbaugha i Ivara Jacobsona (Addison-Wesley, 1998) mówi nam, że “możesz wykonać 80% modelowania za pomocą 20% UML” gdzieś po stronie 400. Zaoszczędziliby branży wiele milionów (miliardów?) dolarów i przerażających przypadków paraliżu analitycznego [?], gdyby powiedzieli to we Wstępie, ale tego nie zrobili. Aby spotęgować przestępstwo, nigdy nie mówią nam, które 20% UML jest użyteczną częścią”.
[zotpressInText item=”{5085975:KID8ZABH}”]
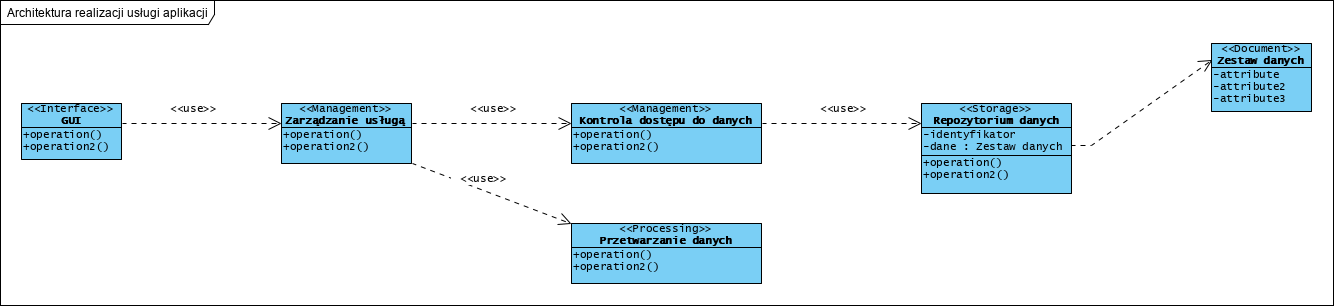
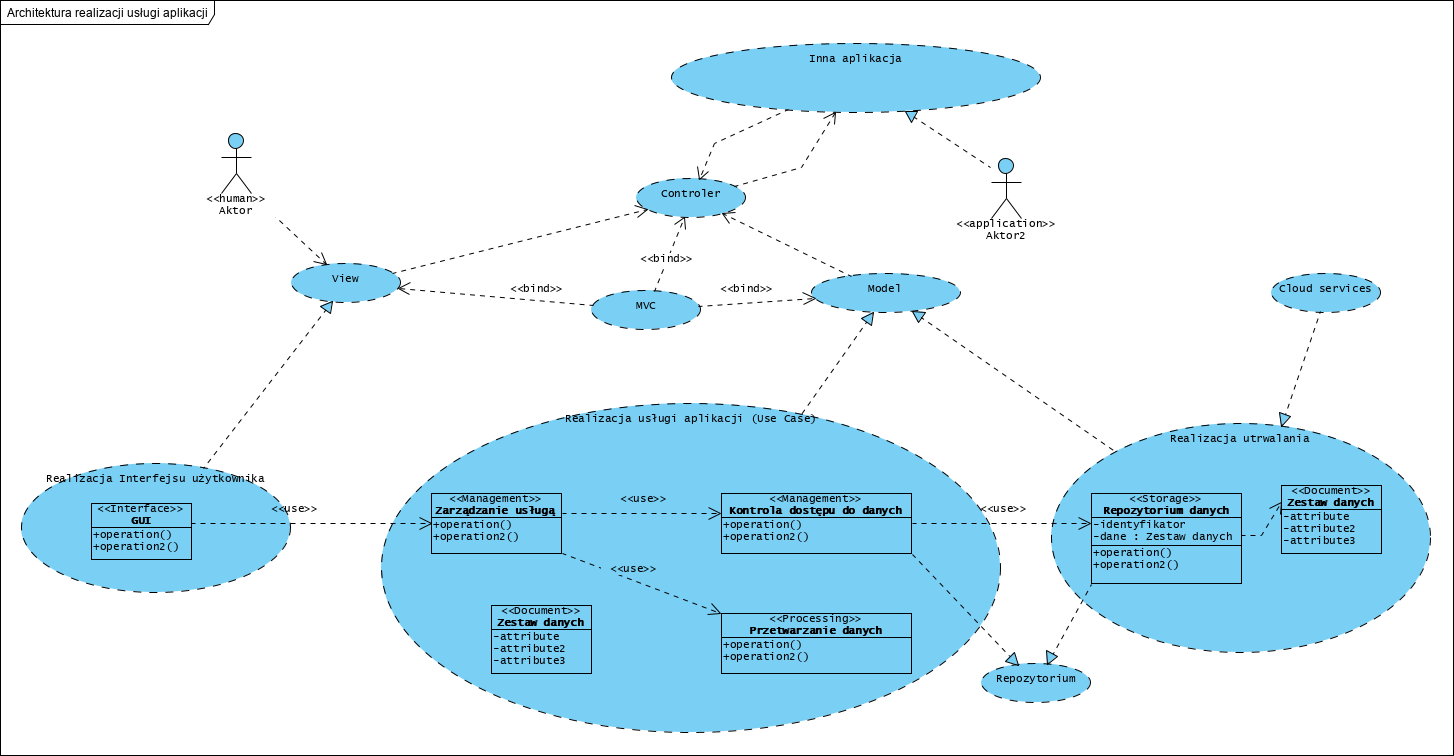
ICONIX to w zasadzie standard komponentowego, zorientowanego obiektowo, na przypadki użycia i interfejsy komponentów, procesu projektowania oprogramowania [zotpressInText item=”{5085975:KID8ZABH},{5085975:7NUD7FFT},{5085975:NARCC3BJ},{5085975:P7WIX63W}”]. Jest to od samego początku swojego istnienia, metoda klasyfikowana jako zwinna [zotpressInText item=”{5085975:BVNB2XAR},{5085975:AK85VTS2}”]. Orientacja na Przypadki Użycia (use case driven) to obecnie kanon projektowania [zotpressInText item=”{5085975:XSXM2FP8},{5085975:CBDVJZQB},{5085975:CG4K6N4J}”]. Coraz popularniejszy wzorzec jakim są mikroserwisy staje się “normą” w projektowaniu architektury [zotpressInText item=”{5085975:ECD9XUND},{5085975:LBWZRGBD},{5085975:ADM6A5A3}”].
Bardzo istotne jest tu także zrozumienie różnicy między inżynierem oprogramowania (systemu) a deweloperem (koderem): zainteresowanym najpierw polecam lekturę artykułu: Software Engineer Vs. Programmer: What?s the Difference? To co robi inżynier bywa nazywane “Diagrams as Code” bo:
Programming is not solely about constructing software?programming is about designing software.
[zotpressInText item=”{5085975:NZCQDD79}”]
UWAGA! Identyczny efekt (diagramy) da projekt udokumentowania istniejącej aplikacji! Taka “rewers-inżynieria” wymaga jedynie ścisłej współpracy zespołu, który napisał/zna kod.
ICONIX
Modelowanie polega na abstrahowaniu od szczegółów i stworzeniu idealizacji tak, by skupić się na istocie danej rzeczy. Dobry model opisuje wyłącznie mechanizm.(Craver & Tabery, 2019)
Nie jest żaden nowy czy inny system notacyjny. ICONIX to, użyta pierwszy raz w latach 90-tych, nazwa usystematyzowanego procesu analizy i projektowania obiektowego z użyciem “czystej” notacji UML. Od samego początku ICONIX jest promowany jako “Zwinność bez skrajności“. Ten, opisany tu, proces analizy i projektowania jest szeroko opisywany w podręcznikach także bez nazwy własnej ICONIX [zotpressInText item=”{5085975:GMJDZZJ4}”].
Na stronie autorów ICONIX Proces:
This website is a collaboration between Matt Stephens and Doug Rosenberg, authors of Use Case Driven Object Modeling with UML ? Theory and Practice, Agile Development with ICONIX Process, and Extreme Programming Refactored: The Case Against XP.
https://iconixprocess.wordpress.com/about/
Zwięzły opis, na podstawie źródeł, podaje także anglojęzyczna WIKI (wpis oparty na publikacjach Rosenberg‘a [zotpressInText item=”{5085975:KID8ZABH},{5085975:P7WIX63W}”]):
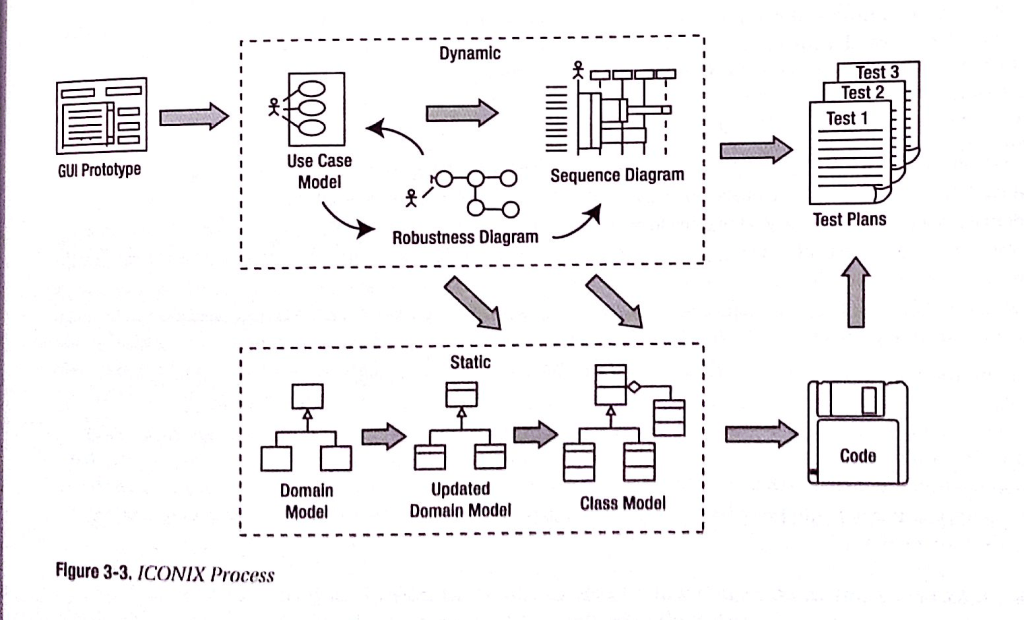
Podobnie jak RUP, proces ICONIX jest oparty na przypadkach użycia UML, ale jest bardziej lekki niż RUP. ICONIX dostarcza więcej dokumentacji niż XP i ma na celu uniknięcie paraliżu analitycznego. Proces ICONIX wykorzystuje tylko cztery diagramy oparte na UML w czterostopniowym procesie, który prowadzi od przypadków użycia do działającego kodu.
Głównym wyróżnikiem ICONIX jest wypełnienie luki pomiędzy analizą a implementacją. Lukę tę wypełniamy od razu modelując mechanizm realizacji przypadków użycia. Proces ten sprawia, że przypadki użycia są znacznie szybciej projektowane, testowane i implementowane.
Zasadniczo Proces ICONIX opisuje podstawowy, “logiczny” proces analizy i modelowania zorientowanego na projektowanie.
na podstawie: https://en.wikipedia.org/wiki/ICONIX
Wyżej wymieniona literatura tak prezentuje pierwotną wersję tego procesu:
ICONIX dzisiaj
Mamy rok 2022, nie ma żadnej rewolucji, “robustness diagram” to diagram komunikacji (lub klas), jest mniej prozy na rzecz diagramów UML:
Poprzedzamy wszystko analizą biznesową: opracowujemy modele procesów biznesowych. Z ich pomocą zbieramy wymagania, jako potrzeby Zamawiającego. Stają się one kanwą projektowanego systemu.
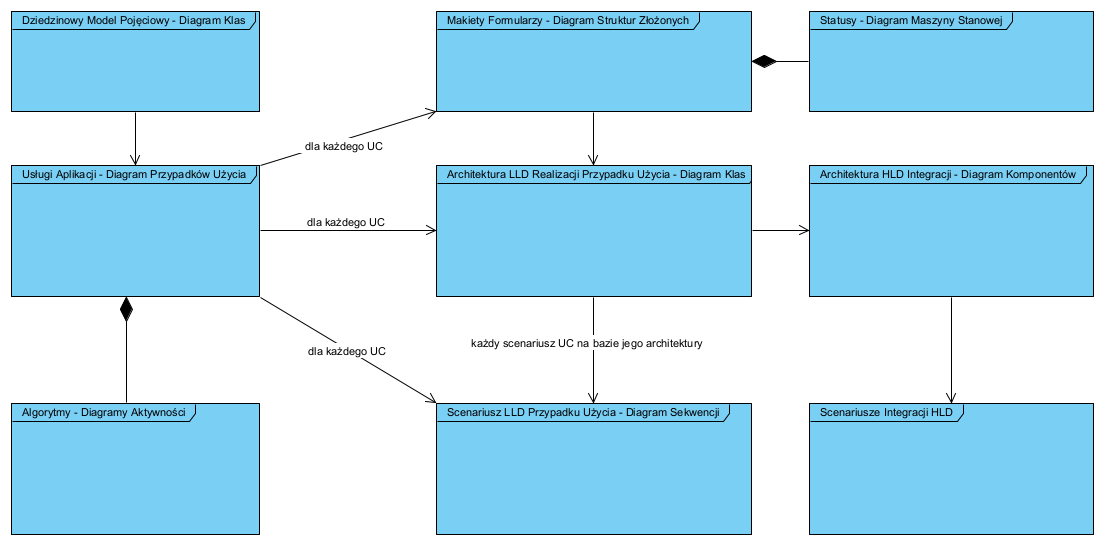
Biorąc pod uwagę aktualny stan notacji na OMG.org “kamienie milowe” procesu to odpowiednio etapy i ich produkty:
- Mając wynik analizy biznesowej w postaci map procesów biznesowych, modeli pojęciowych i listy reguł biznesowych oraz potrzeby biznesowe (cele projektu), opracowujemy listę przypadków użycia (UC) oraz wstępne szablony (makiety) formularzy na bazie dokumentów opisanych w procesach biznesowych.
- Mając przypadki użycia i makiety formularzy, projektujemy scenariusze opisujące planowane/wymagane interakcje aktor-system. Omawiamy je z Zamawiającym. Na tym etapie można dodatkowo udokumentować algorytmy (metody) przetwarzania/walidacji treści formularzy (szczególnie, gdy początkowo zakładamy zakup standardowego oprogramowania spełniającego tak opisane wymagania). Jeżeli nie, projektowane jest oprogramowanie dedykowane.
- Kolejny etap to zaprojektowanie architektury HLD aplikacji, czyli układu komponentów realizujących poszczególne UC oraz diagramy sekwencji opisujące współdziałanie tych komponentów w toku realizacji scenariuszy UC.
- Od tego momentu, iteracyjnie-przyrostowo, projektowane są realizacje UC jako ich architektury LLD i diagramy sekwencji opisujące ich wewnętrzne działanie, tak opisane realizacje przekazywane są kolejno do implementacji.
Kluczowy jest pkt.1. gdyż to formularze (dokumenty) są kluczowym nośnikiem informacji czyli danych i ich kontekstu. Ten etap to korzystanie z wyników analizy biznesowej: identyfikacja dokumentów oraz ich formalizacja i standaryzacja:
Kluczowe reguły: (1) dokument jest klasyfikowany albo jako opis obiektu albo faktu, (2) opis faktu nie może być modyfikowany a obiektu tak (aktualizacja stanu faktycznego), (3) modyfikacja opisu obiektu jest faktem (który można dokumentować), (4) opis faktu musi dotyczyć co najmniej jednego obiektu.
źr.: Dokument jako nośnik danych i metoda zarządzania danymi ? agregat doskonały
Punkt 2. to projektowanie realizacji wymagań biznesowych i modelowanie systemu jako “czarnej skrzynki”, to umowa (zakres produktu) z zamawiającym.
Punkty 3. i 4. są realizowane w pętli aż do oddania do użytku całej aplikacji.
Diagramy UML
Całość dokumentowana jest z użyciem notacji UML.
Pierwszy diagram jaki powstaje to Diagram Przypadków Użycia. Jest to jeden diagram definiujący kontekst i zakres projektu oraz jego otoczenie: użytkowników i zewnętrzne, integrowane aplikacje.
Dla każdego przypadku użycia (UC) projektujemy bazowy formularz, na bazie odpowiadającego mu dokumentu z modelu procesów biznesowych. Najlepiej użyć do tego Diagramu Struktur Złożonych (jest to zorientowany na dokumenty model danych). Każdy UC należy opisać dialogiem aktor-system opisującym “co system ma robić”.
Jeżeli dane (formularze) cechują się stanowością lub, jako dokumenty mają statusy, to tworzymy dodatkowo Diagramy Maszyny Stanowej dla tych dokumentów. Wszędzie tam, gdzie logikę (mechanizm) działania należy udokumentować algorytmem lub scenariuszem opisującym współdziałania komponentów na wyższym poziomie abstrakcji, stosujemy Diagramy Aktywności.
Kolejny diagram to Diagram Komponentów, na którym opisujemy wewnętrzną, komponentową architekturą aplikacji (tu korzystamy głownie z wzorców: Mikro-serwisy i Saga) oraz adaptery integracyjne dla zewnętrznych aplikacji (patrz Diagram Przypadków Użycia jako kontekst).
Ostatecznie dla każdego komponentu (mikro-serwis) tworzymy jego architekturę LLD z użyciem Diagramu Klas i także Diagramu Sekwencji.
Diagram Przypadków Użycia to deklaracja zakresu systemu dla przyszłego użytkownika: “czarna skrzynka”. Diagramy komponentów i klas to statyczna architektura systemu, diagramy aktywności i sekwencji opisują jego zachowanie. Ten model nazywamy to “białą skrzynką”.
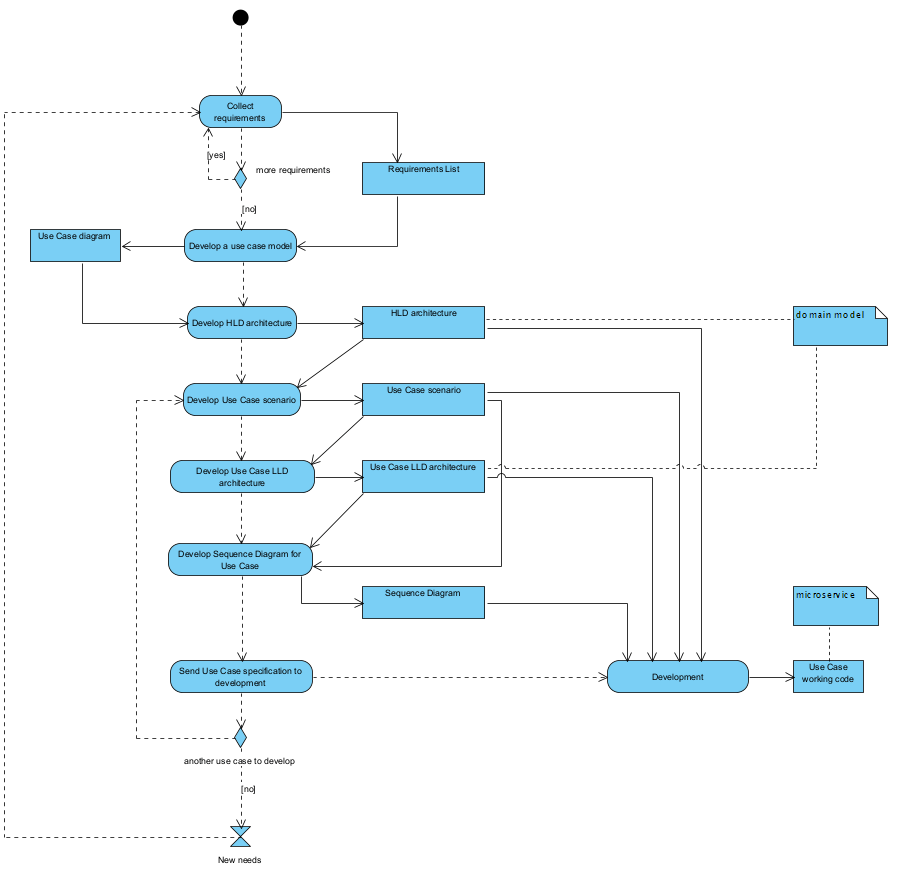
Scenariusz iteracyjnego wytwarzania w procesie ICONIX:
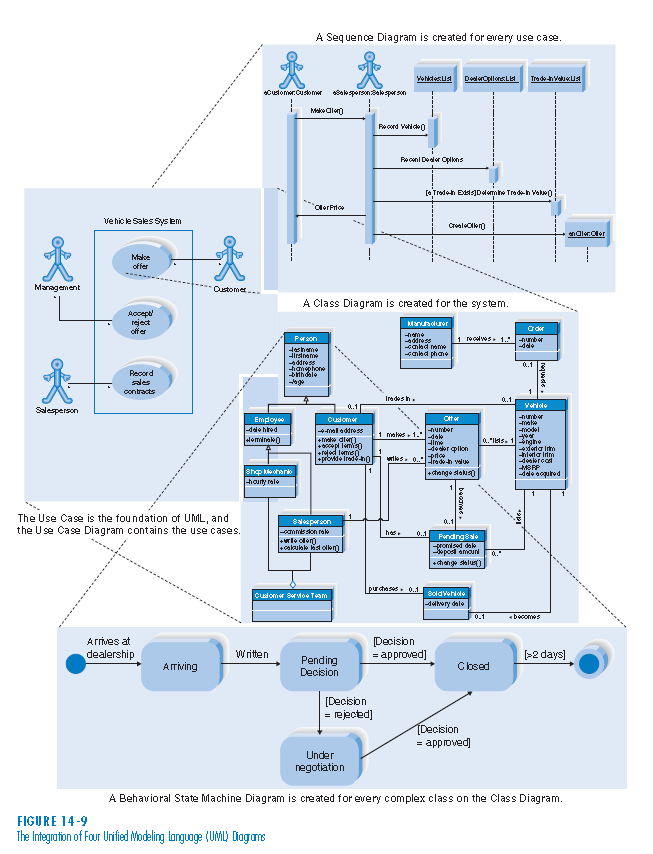
Idea procesu analizy i projektowania zorientowanego na przypadki użycia i ich realizacje jest aktualna i kultywowana, nie zawsze pod nazwą ICONIX. Dostępna jako Use CAse 2.0 [zotpressInText item=”{5085975:IENSXKK5},{5085975:XSXM2FP8}”] lub w wersji akademickiej bez własnej nazwy jako proces projektowania [zotpressInText item=”{5085975:GMJDZZJ4}”]:
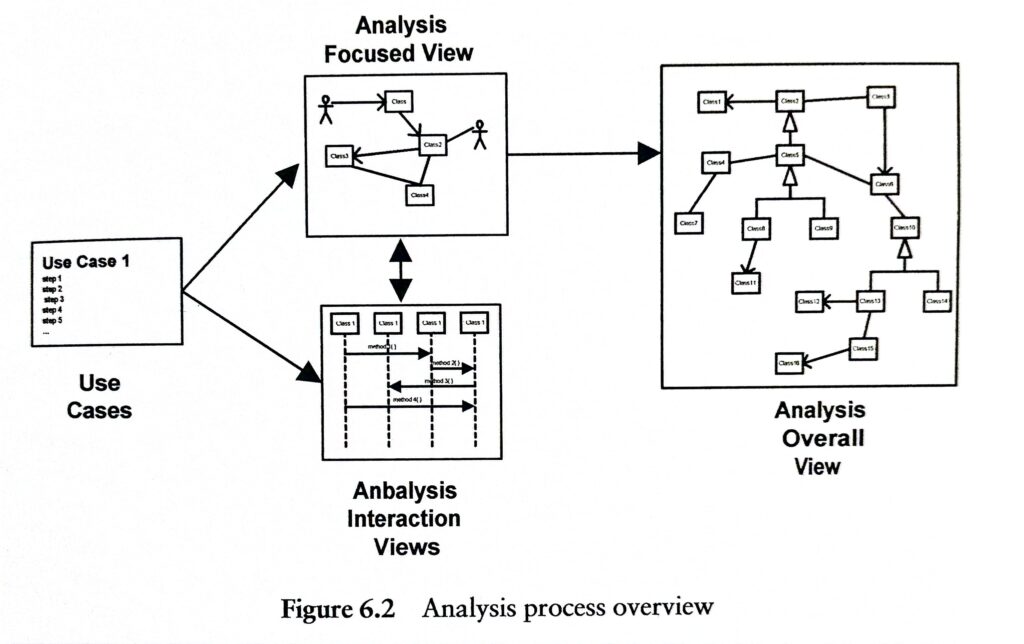
Powyższa struktura projektu obiektowo-zorientowanego (albo jak kto woli na komponenty i interfejsy) jest nadal aktualnym elementem wielu podręczników z zakresu inżynierii oprogramowania oraz opracowań i metod takich jak Use Case 2.0 [zotpressInText item=”{5085975:IENSXKK5},{5085975:XSXM2FP8}”].
Ciekawostką jest, że powyższy podręcznik ma 594 strony, nadal jest w użyciu na wielu uczelniach, a metody obiektowe zorientowane na przypadki użycia to nadal tylko jeden ostatni rozdział o objętości 30 stron. Praktycznie cały podręcznik traktuje o metodach strukturalnych i relacyjnym modelu danych. Taka struktura nauczania inżynierii oprogramowania nadal dominuje na uczelniach, co moim zdaniem tłumaczy nadal powszechne, strukturalne podejście deweloperów do tworzenia aplikacji (mimo, że używają tak zwanych obiektowo-zorientowanych języków programowania).
Inny przykład tej samej idei poniżej:
Dla porównania notacja SysML, jako profil UML, stosowana w MBSE (Model-Based System Engineering) oraz proces projektowania w SysML, są zbudowane na niemalże identycznych założeniach: wymagania, przypadki użycia i mechanizm ich realizacji oraz współpraca komponentów. SysML jako podejście do projektowania ogólnie systemów mechatronicznych, praktycznie wyklucza tworzenie monolitycznych systemów. Głównie dlatego, że z zasady są to duże i multi-dziedzinowe projekty (duże projekty inżynieryjne są interdyscyplinarne).
A gdzie są user story
User Story to wizja potrzeb wyrażona z perspektywy użytkownika. Mam nadzieję, że poniższy diagram odpowiada na to pytanie:
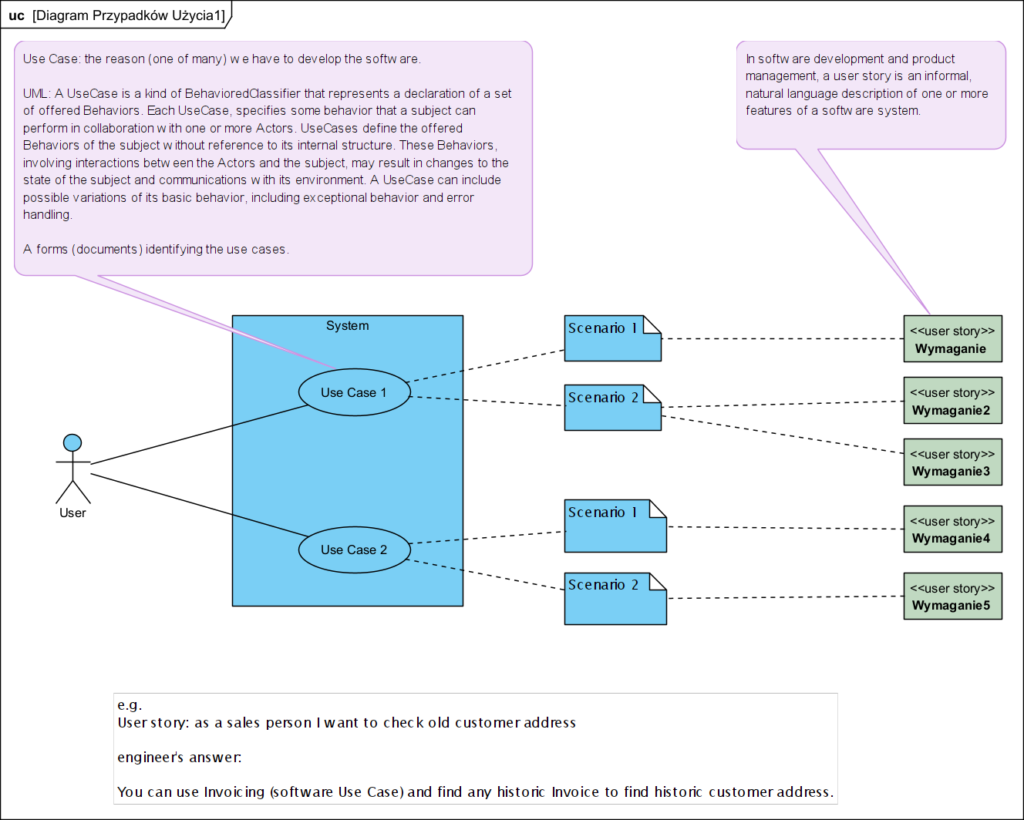
Struktura procesu wytwarzania oprogramowania
Całość tego procesu projektowania od ogółu do szczegółu można zobrazować tak:
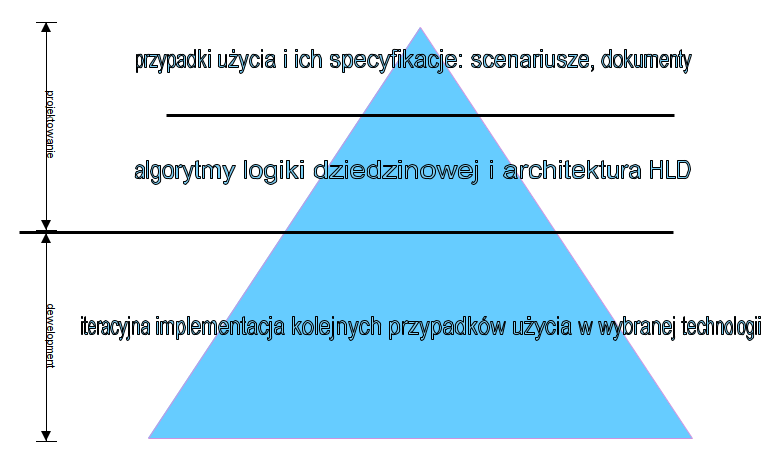
Sam proces ICONIX nie jest niczym specjalnym ani wyjątkowym, w sensie notacyjnym. Jak już wspomniano, tak zwany “robustness diagram” nie był nowym, innym diagramem UML.
Continuous delivery
Od ok. piętnastu lat mówi się, że “żaden system nie jest ukończony” lecz nie chodzi o to że ma błędy i stale je poprawiamy (jak czasami słyszę od niektórych deweloperów). Chodzi o iteracyjne aktualizowanie go o kolejne potrzebne nowe lub zaktualizowane usługi i funkcjonalności [zotpressInText item=”{5085975:C98LIU6F},{5085975:KSPQPHW7}”]. Proces ten chroni także co chroni także przed zaciąganiem długu technologicznego.
Continuous Delivery (Ciągłe Dostarczanie) jest podejściem do inżynierii oprogramowania, w którym oprogramowanie (system) jest budowane jako dostarczane, w relatywnie krótkich cyklach, nowe lub zaktualizowane komponenty. Aby było to możliwe cały system musi spełniać pewien zestaw wymagań architektonicznych, takich jak możliwość niezależnego wdrażania komponentów, ich modyfikowalność i testowalność (hermetyzacja). Wymagania architektoniczne są tu fundamentem, którego nie mozna pominąć.
Jednym z najczęściej wykorzystywanych tu wzorców architektonicznych są orientacja na interfejsy oraz mikroserwisy i adaptery integracyjne. Pozwalają na niezależność wdrażania komponentów, krótszy czas ich wdrażania, prostsze procedury wdrażania i wdrażanie bez przestojów. W efekcie uzyskujemy: krótszy czas cyklu dla małych przyrostowych zmian funkcjonalnych, łatwiejsze zmiany w wyborze technologii.
Na tle powyższego ICONIX wraz z Use Case 2.0 [zotpressInText item=”{5085975:IENSXKK5}”] oraz podejście zorientowane na komponenty [zotpressInText item=”{5085975:NI8AM7JP},{5085975:ZXMTN7WR},{5085975:ZT6SQRP6}”] wydaje się wręcz idealnym
O architekturze i paradygmatach
“A software system?s architecture is the set of principal design decisions made about the system.”
[zotpressInText item=”{5085975:WRM97AIW}”]
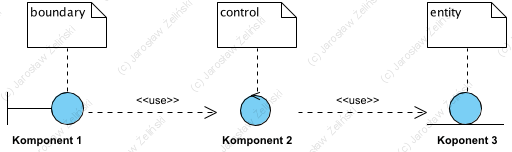
BCE: wzorzec projektowy zorientowany na odpowiedzialność klas

ICONIX to bardzo skuteczna, zwinna metoda projektowania oprogramowania zorientowana na modele (ang. MDD, Model Driven Development). Mimo stosowania UML, jest lekka, bo korzystamy z kilku podstawowych typów diagramów UML i ich prostych form.
ICONIX jest kojarzony często z ikonami stereotypów BCE (Boundary, Control, Entity). Stereotypy te w postaci graficznej są dostępne w wielu narzędziach CASE, w tym EA SPARX i Visual-Paradigm. Architektura LLD przypadków użycia jest tu budowana w oparciu o wzorzec “class responsibility” [zotpressInText item=”{5085975:CDZ44929},{5085975:VNQDV6CQ}”]. Inne polecane tu analityczne wzorce architektoniczne to: łańcuch odpowiedzialności, saga, mikroserwisy, repozytorium, koperta (envelope, DTO).
BCE to wzorzec zakładający, że komponent realizujący przypadek użycia, będzie architekturę LLD zbudowaną z odrębnych obiektów, odpowiedzialnych odpowiednio za: komunikację z otoczeniem (boundary), realizacje logiki dziedzinowej (control) i przechowywanie danych (entity), dane przechowujemy jako całe komunikaty (envelope). Poniżej ilustracja z 2002 roku:
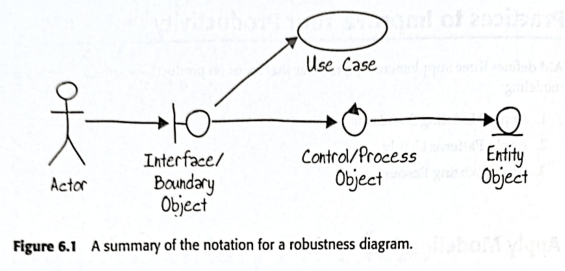
Powyższe dzisiaj narysowali byśmy to jak poniżej:
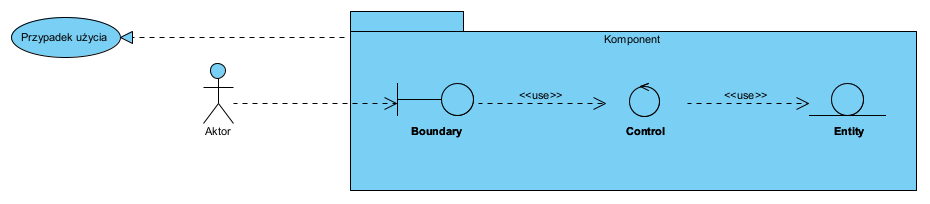
Element ‘Entity’ na powyższym diagramie reprezentuje obiekt przechowujący dowolnie złożony strukturalny dokument jako agregat (patrz opisany wyżej wzorzec envelope, więcej na ten temat w artykule: Dokument jako nośnik danych i metoda zarządzania danymi). Projektowanie na poziomie LLD bardzo dobrze opisuje Ousterhout [zotpressInText item=”{5085975:IWBHW8XL}”].
Architektura heksagonalna
Termin “Hexagonal Architecture” (Architektura Heksagonalna) pojawia się już od dawna. Na tyle długo, że podstawowe źródło na ten temat było przez jakiś czas offline i dopiero niedawno zostało uratowane z archiwów [zotpressInText item=”{5085975:IQ3YKX86}”]. Schematycznie autor przedstawia to tak:
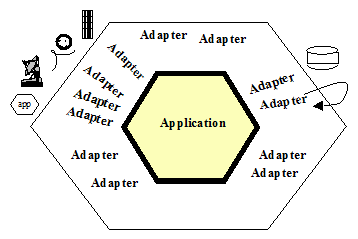
Autor powyższego pisze:
Jednym z wielkich błędów aplikacji przez lata było przenikanie logiki biznesowej do kodu interfejsu użytkownika. Problem, który to powoduje jest potrójny:
- Po pierwsze, system nie może być zgrabnie przetestowany za pomocą zautomatyzowanych pakietów testowych, ponieważ część logiki wymagającej przetestowania zależy od często zmieniających się szczegółów wizualnych, takich jak rozmiar pola i rozmieszczenie przycisków;
- Z tego samego powodu niemożliwe staje się przejście z systemu sterowanego przez człowieka na system działający w trybie wsadowym;
- Z tego samego powodu, trudne lub niemożliwe staje się umożliwienie prowadzenia programu przez inny program, gdy staje się to atrakcyjne.
Innymi słowy separujemy “motor logiki biznesowej” (PIM) od środowiska (framework) w jakim apliakcja powstaja i funkcjonuje. Poniższa prezentacja obrazuje to tak:
Dlatego to co opisano w tym artykule (model logiki dziedzinowej aplikacji), z perspektywy architektury heksagonalnej, nazwiemy Aplikacją (Application core). Z perspektywy MDA (patrz OMG.org/MDA) jest to właśnie Platform Independent Model (PIM) i komponent Model w MVC.
Architektura C4
Model w architekturze C4 opisuje statyczne struktury systemu oprogramowania w kategoriach kontenerów (aplikacje, składy z danymi, mikroserwisy, itp.), komponentów i kodu. Jest to perspektywa stosu technologicznego. Jest to bardzo dobry sposób na udokumentowanie środowiska w jakim wykonuje sie aplikacja (która tu będzie “klockiem na poziomie komponentów). Ta architektura i taka dokumentacja jest bardzo dobra metodą na projektowanie i dokumentowanie implementacji.
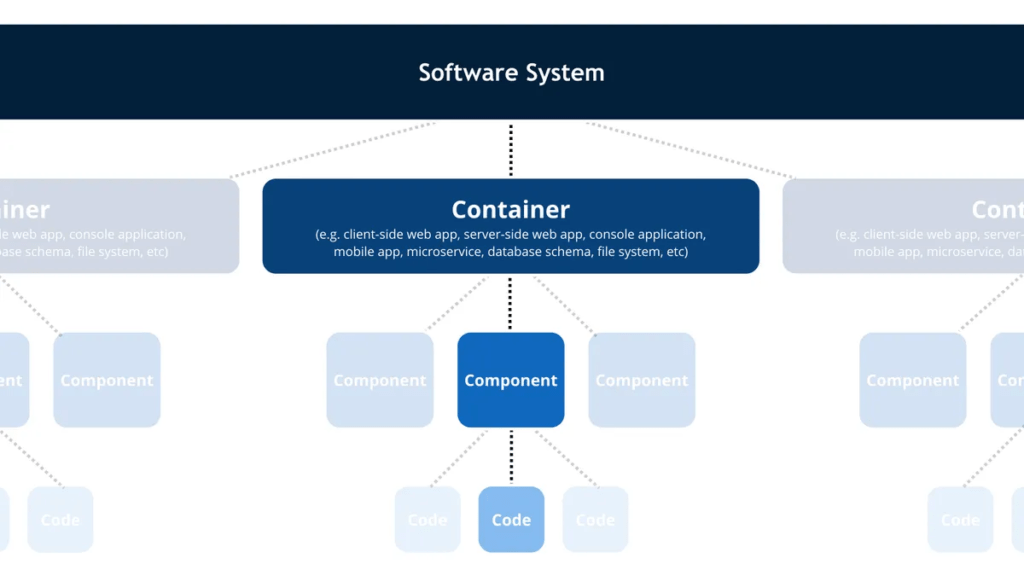
W WIKI można znaleźć komentarz:
Code diagrams (level 4): provide additional details about the design of the architectural elements that can be mapped to code. The C4 model relies at this level on existing notations such as Unified Modelling Language (UML), Entity Relation Diagrams (ERD) or diagrams generated by Integrated Development Environments (IDE).
https://en.wikipedia.org/wiki/C4_model
C4 to jednak tylko statyczna struktura, autor pomija kwestie zachowania sie systemu, dlatego C4 może stanowić opis architektury dla dewelopera, ale ani nie wyjaśnia ani nie weryfikuje dynamiki systemu.
Jeśli “agile” jest tak dobre, to dlaczego jest tak źle?
To parafraza tytułu referatu z 2012 roku. Bardzo często pod nazwą “agile” oferuje się formę tak zwanego programowania ekstremalnego, czyli szybkiego kodowania tylko na podstawie oczekiwań przyszłego użytkownika. Poniżej jeden z ogromnej liczby krytycznych referatów o tak pojmowanym agile. Projekty, do których jestem angażowany, to często projekty trudne, rozpoczynane po raz drugi po nieudanym pierwszym podejściu. Dlatego ich sponsorzy teraz dbają o podział na role i odpowiedzialność każdej strony projektu. Prelegentka poniżej zwraca na to uwagę tak:
never ask your users what they want, never ask your developer what they think the users want? [nigdy nie pytaj użytkowników, czego chcą, nigdy nie pytaj deweloperów, co myślą, że użytkownicy chcą?]
Tak więc zwinność owszem, ale agile rozumiane jako pospolite ruszenie bazujące na burzach mózgów na pewno nie!
Podsumowanie
To, że ICONIX, jako proces, jest stosunkowo rzadko używany (to się jednak zmienia od kilku lat), ma swoje podłoże w tym, że przede wszystkim wymaga zrozumienia procesu tworzenia komponentowo-zorientowanej architektury, wymaga też znajomości i zrozumienia pojęcia architektury heksagonalnej i powiązanego z nią wzorca MVC. Wymaga poznania i zrozumienia wielu innych obiektowych wzorców projektowych, wymaga przede wszystkim umiejętności abstrakcyjnego myślenia i modelowania (UML). Wymaga zrozumienia tego, że z kodowanie należy poprzedzać projektowaniem, bo “projektowanie” w kodzie jest najmniej efektywną formą projektowania [zotpressInText item=”{5085975:4XDEIZGV}”].
Proces ten wspiera także podział na etapy analizy i projektowania oraz implementacji (patrz powyższy schemat: Struktura ról i produktów projektu w procesie ICONIX). ICONIX bywa niesłusznie kojarzony z “ciężkim” procesem wytwarzania oprogramowania, jakim jest Rational Unified Process (o którym praktycznie nie pisałem na swoim blogu).
Powodem rzadkiego stosowania ICONIX, jest też to, że niestety świat został, już w latach 90-tych, mocno “zepsuty” przez C++ i Javę (architektury budowane na kaskadach dziedziczenia). Są to często ciężkie, monolityczne frameworki oparte na relacyjnym modelu danych, gdzie nie ma ścisłego podziału na logikę dziedzinową i środowisko (MVC). Java to nadal jedna z najkosztowniejszych i najmniej efektywnych metod tworzenia aplikacji. Framework EJB do dziś jest opisywany jako źródło obiektowego antywzorca projektowego o nazwie “anemiczny model dziedziny“. Jednak rosnące od kilku lat zainteresowanie deweloperów modelem C4 pokazuje, że analiza i modelowanie są potrzebne i cichutko wchodzą tylnymi drzwiami…
Osobom zainteresowanym architekturą kodu polecam artykuł: Projektowanie czyli architektura kodu aplikacji c.d..
Dodatek: Analiza obiektowa i projektowanie obiektowe czyli co?
Od dawna toczą sie dyskusje na temat tego czym jest OOP i OOAD. Definiowanie paradygmatu obiektowego jako dziedziczenia i łączenia danych i funkcji w obiekty zostały zdyskredytowane już pod koniec lat 90-tych przez samego “autora pomysłu” (Alan Kay), który podkreśla, że istotą obiektowości jest podział na samodzielne komponenty (obiekty) oraz ich wzajemna komunikacja (w tym polimorfizm).
ICONIX jest jedną z pierwszych obiektowych, zwinnych metod analizy i projektowania: całe oprogramowanie składa się z komunikujących się obiektów (komponenty i diagramy sekwencji). Do modelowania wykorzystywany jest minimalny zestaw diagramów UML w ich minimalnej postaci. Dalej już oddam głos deweloperom:
Zainteresowanych zapraszam na szkolenia i warsztaty, oferuje także mentoring.
Źródła
[zotpressInTextBib style=”apa” sortby=”author” sort=”ASC”]