Wprowadzenie
Niedawno miała miejsce kolejna moja dyskusja na LinkedIn, która pokazała że prawo własności intelektualnej jest bardzo trudne do przyswojenia, głównie dlatego że – z uwagi na swoją „niematerialność” – wymyka się intuicyjnej i materialnej manierze postrzegania świata przez człowieka. Na to nakłada się przeświadczenie koderów, że z zasady są samodzielnymi twórcami, i niestety wielu prawników także tak uważa. Rzecz w tym, że koder zawsze jest twórcą, ale nie zawsze jest projektantem. Gdy koder nie jest projektantem, jego utwory (kod źródłowy) to utwory zależne od utworów pierwotnych, jakimi są projekty techniczne wyrażone np. z pomocą UML, wzorów matematycznych, algorytmów. Wtedy oczekujemy od koderów, że jako deweloperzy, wykonają świetnie swoje rzemiosło.
Z uwagi na to, że w ekspertyzach, które piszę, często korzystam z celowościowego i systemowego interpretowania umów i prawa, postanowiłem opisać tu analizę ontologiczną tego obszaru inżynierii. Celem jest określenie znaczenia i zasięgu definicji pojęć powszechnie stosowanych w dziedzinie własności intelektualnej. Mam także nadzieję, że pomogę tym Państwu zawierać lepsze umowy na dostawy oprogramowania.
Metoda
Artykuł ma charakter analityczny. Wykorzystano w nim elementy analizy systemowej i ontologię i pojęcie modelowania w nauce.
Rezultaty
Efektem prac jest taksonomia pojęcia własności intelektualnej, model pojęciowy obszaru praw autorskich i opisu projektu lub wynalazku, wyjaśnienie związku między modelem i jego implementacją, oraz wykazanie ścisłego związku między opisem (modelem) mechanizmu a oprogramowaniem, które go realizuje w komputerze. Dla obszaru prawa autorskiego oznacza to ścisły związek między modele jako utworem pierwotnym a implementacją jako utworem zależnym.
Prawo autorskie w inżynierii oprogramowania
Artykuł Prawo autorskie w projektach IT, zakończyłem słowami:
Podsumowując: możliwe jest opracowanie dokumentacji oprogramowania opisującej (wymagany) mechanizm jego działania i architekturę. Oprogramowanie powstałe na bazie takiej dokumentacji to implementacja projektu i stanowi ono odwzorowaniem projektu w specyfikacji. Prawo autorskie jest tu wręcz doskonałym mechanizmem kontrolnym nad wykonawcą oprogramowania: mając prawa majątkowe do projektu technicznego, z zasady dysponujemy w pełni oprogramowaniem wykonanym na nasze zamówienie i na podstawie takiej dokumentacji. Jeżeli dostawca stworzy zamówione oprogramowanie inaczej bo po swojemu, to znaczy tylko tyle, że nie zrealizował zawartej umowy i nie należy mu płacić.
źr.: Prawo autorskie w projektach IT – Jarosław Żeliński IT-Consulting (polecam przeczytanie tego tekstu przed lekturą dalszej części)
Kluczowa dla inżynierii oprogramowania jest ontologiczna definicja mówiąca, że “komputer to uniwersalny mechanizm” [zotpressInText item=”{5085975:ZCXJ2S7U}”] oraz fakt, że działający, czyli przydatny do czegokolwiek, komputer to: procesor, pamięć i program [zotpressInText item=”{5085975:FY9XT4Q3}”].
Program (oprogramowanie) to obecnie potężny zestaw oprogramowania, podzielonego na komponenty. Są to osobno system operacyjny, standardowe oprogramowanie, środowisko wykonawcze, biblioteki programistyczne, oraz to co ewentualnie powstanie jako dedykowane oprogramowanie realizujące oczekiwany (wymagany) “mechanizm”, zwany potocznie “aplikacją” [zotpressInText item=”{5085975:IQ3YKX86}”]:
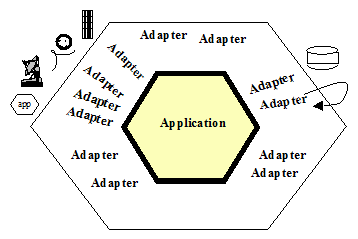
Powyższe jest bardzo ważne, gdy chcemy “coś” nazwać oprogramowaniem czy wręcz kodem źródłowym: w projektach programistycznych najczęściej jest to jedynie kod źródłowy ww. dedykowanej aplikacji, reszta to gotowe, standardowe produkty.
Całość systemu informatycznego organizacji może się składać z wielu takich zintegrowanych (połączonych) programów. Istotne jest to, że zarówno projekt techniczny aplikacji, jak i projekt techniczny integracji aplikacji, to projekty inżynierskie. Projekty jednakowo chronione prawem autorskim.
Z uwagi na to, że prawo autorskie ma “wydzieloną część” dla utworów takich jak utwory literackie, muzyczne, fotografia czy filmowe, a także projekty budowlane, nie ma osobnej “części” dla inżynierii oprogramowania, stosujemy tu analogie do ww. elementów prawa autorskiego, z czym nie ma żadnego problemu. Kluczowe jest poprawne dedukcyjnie formułowanie celu działania oraz budowanie tych analogii. W prawie mówimy wtedy o wykładni celowościowej i systemowej:
W prawie, miedzy innymi, stosowana jest wykładnia systemowa i celowościowa (Koszowski, 2019). Obie są podstawowymi narzędziami „naprawiającymi” to co nazywamy „złym prawem”. Tam gdzie ścieramy sie z dogmatyzmem (i dogmatykiem) prawa, możemy (i mamy prawo) stosować te wykładnie. To właśnie te dwa narzędzia pozwalają mi „wygrywać” sprawy dla moich klientów, ale nie dlatego że „jestem lepszym prawnikiem”, bo nim nie jestem. Dlatego, że te dwie metody pozwalają – w uzasadnionych przypadkach i kontekstach – sprowadzać zapisy prawa do absurdu, co z nie raz kończy się w Sądzie wyborem wykładni systemowej i celowościowej w miejsce dogmatycznej.
źr.: Ekspertyza, opinia prywatna, recenzja, opinia biegłego sądowego – Jarosław Żeliński IT-Consulting
Własność intelektualna
Na rządowej stronie promującej wiedzę z tego zakresu znajdziemy:
Własność intelektualna to wytwory ludzkiego umysłu, przedstawione w materialnej postaci, jak utwory literackie, oznaczenia towarów czy wynalazki. Nazywane są dobrami niematerialnymi i stanowią niematerialne składniki majątku firmy. Są to oryginalne i nowatorskie efekty twórczej działalności człowieka.
źr.: https://www.biznes.gov.pl/pl/portal/00367
Kluczem jest tu “materialność”. Ustawowa definicja utworu:
Przedmiotem prawa autorskiego jest każdy przejaw działalności twórczej o indywidualnym charakterze, ustalony w jakiejkolwiek postaci, niezależnie od wartości, przeznaczenia i sposobu wyrażenia (utwór).
U S TAWA z dnia 4 lutego 1994 r. o prawie autorskim i prawach pokrewnych1) Rozdział 1 Przedmiot prawa autorskiego Art. 1. 1.
Tu jest mowa o tym, że utwór – by nim być – musi zostać “ustalony” co jest niczym innym jak jego utrwaleniem. Czyli jeżeli coś jest utworem to:
- Musi to być rezultat pracy człowieka (twórcy).
- Musi to być przejaw działalności twórczej (utwór musi być oryginalny).
- Musi mieć indywidualny charakter (czyli trzeba sobie postawić pytanie, czy takie dzieło już powstało, czy byłoby możliwe, że przypadkiem stworzy je inna osoba).
Słowo projekt ma kilka znaczeń, tu skupimy się na:
projekt: dokument zawierający obliczenia, rysunki itp. dotyczące wykonania jakiegoś obiektu lub urządzenia.
(słownik języka polskiego)
Kluczowe dla całości tego artykułu są:
znak: kształt, któremu przypisuje się określone znaczenie
https://sjp.pwn.pl/
znaczenie: treść, której znakiem jest wyraz lub wyrażenie
Powyższe można zobrazować jako model pojęciowy wraz z językowymi związkami pojęciowymi (predykaty) na podstawie ww. definicji:
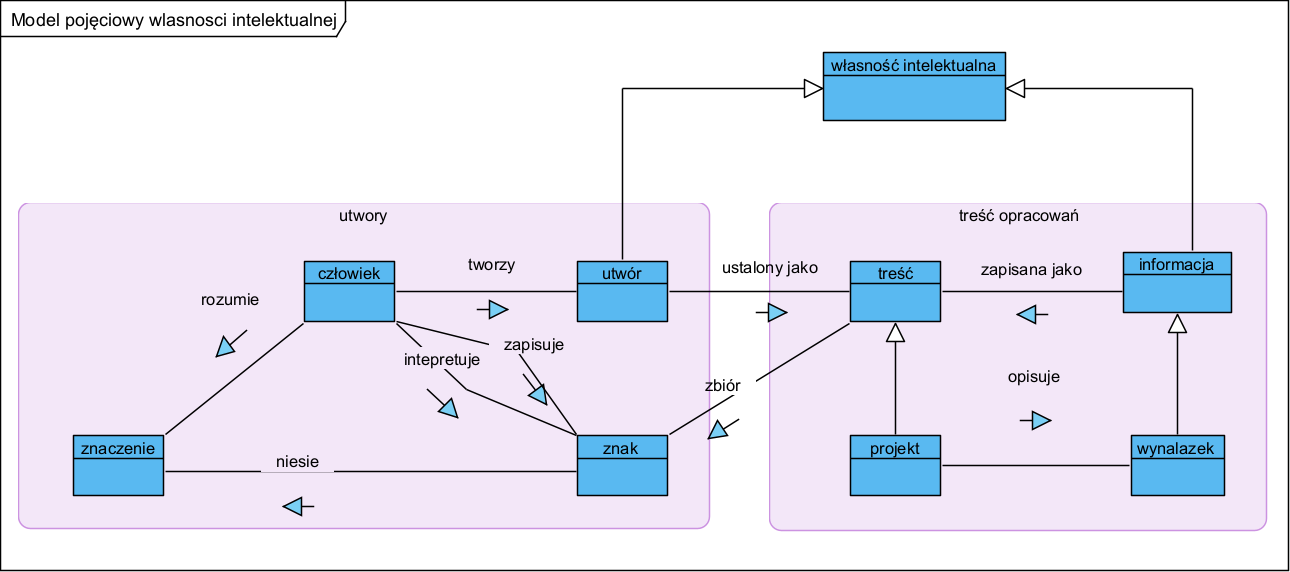
Tak więc: Dzieło człowieka: utwór, będąc treścią czyli utrwaloną informacją, może stanowić sobą projekt, a także opis wynalazku.
Projekt a utwór
Wynalazki są bardzo dobrym przykładem i zarazem analogią do opisu komputera, gdyż cytowana wyżej definicja: “komputer to uniwersalny mechanizm”, na pewnym poziomie opisu, zrównuje komputer z materialnym mechanizmem.
Wniosek patentowy musi zawierać między innymi opis wynalazku ujawniający jego istotę. Opis wynalazku powinien gwarantować, że zgłoszenie zawiera wystarczające informacje, pozwalające znawcy w danej dziedzinie na odtworzenie rozwiązania w praktyce i pozwalać czytelnikowi zrozumieć wkład, jaki daje wynalazek do dziedziny techniki. Dlatego opis wynalazku i rysunki powinny być spójne, szczególnie, gdy chodzi o wyjaśnienia do elementów rysunków. Opis wynalazku powinien być zredagowany jednoznacznie. Nie podaje się technicznych określeń żargonowych, a jedynie określenia techniczne stosowane w danej dziedzinie techniki.
[zotpressInText item=”{5085975:Y86V5TMQ}”]
Biorąc zaś pod uwagę fakt, że funkcjonalność komputera jest determinowana przez jego oprogramowanie, można powiedzieć, że o tym czym jest komputer decyduje jego oprogramowanie. Mamy więc abstrakcyjny mechanizm i jego implementacje np. w postaci komputera (program jest jego częścią). Ten mechanizm jest realizowany przez oprogramowanie, a ono jest ciągiem procedur. Tak więc najpierw powstaje opis (model) tego mechanizmu, a na jego podstawie urządzenie mechaniczne (elektro-mechaniczne) lub komputer.
To czy to urządzenie jest komputerem czy przedmiotem w 100% materialnym, praktycznie nie ma znaczenia, tak samo jak nie ma znaczenia to czy urządzenie odmierzające czas (lub sterujące pralką) to komputer czy zestaw kół zębatych. Oprogramowanie ma swoją abstrakcyjną strukturę wewnętrzną, to model mechanizmu jego działania [zotpressInText item=”{5085975:LKGQJ85W}”]. Możliwe jest więc stworzenie schematu blokowego (zestaw schematów) dokumentującego mechanizm realizowany przez stworzone pod jego dyktando oprogramowanie (więcej na ten temat w artykule Model dziedziny jako mechanizm). Taki zestaw diagramów to opis struktury elementów mechanizmu (jego architektura) oraz opis współdziałania tych elementów (zachowanie się systemu):
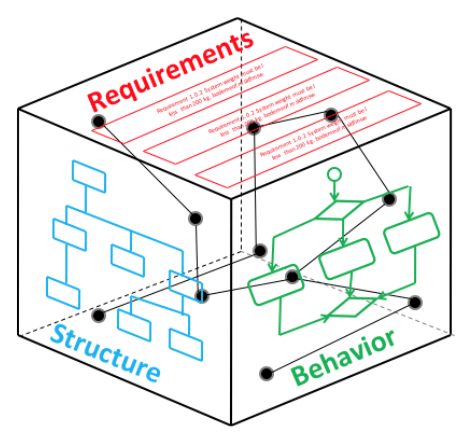
Przytoczmy jeszcze raz:
Własność intelektualna to wytwory ludzkiego umysłu, przedstawione w materialnej postaci, jak utwory literackie, oznaczenia towarów czy wynalazki. Nazywane są dobrami niematerialnymi i stanowią niematerialne składniki majątku firmy. Są to oryginalne i nowatorskie efekty twórczej działalności człowieka.
źr.: https://www.biznes.gov.pl/pl/portal/00367
Ważna rzecz: materializacja (postać materialna) jako warunek bycia wartością intelektualną. Innymi słowy można chronić tylko to istnieje, utrwalony opis to jego “istnienie”. Tym “utrwaleniem” jest treść czyli dokument (także elektroniczny). Materialność dokumentu to jest utrwalenie (patrz ustawowa definicja utwory: “ustalony w jakiejkolwiek postaci”). To czy będzie to nośnik papierowy czy elektroniczny nie ma znaczenia.
Tak więc to co wymyślimy i ma wartość jako informacja to wartość intelektualna. To co utrwalimy np. na papierze czy w pamięci stałej komputera jako plik pdf (lub inny) to dane, te niosą informację, jest nią np. opis konstrukcji. Jeżeli zapis spełnia określone warunki (wykonany przez człowieka i ma indywidualny charakter) to jest to także utwór:
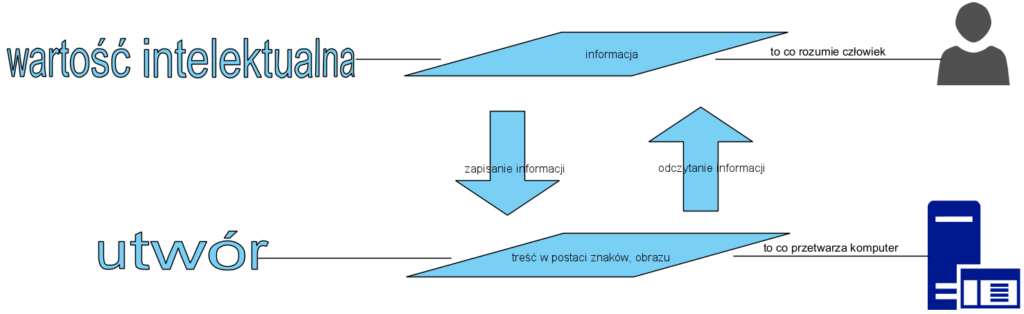
Tak więc treść wyrażona w postaci znaków i schematów to sposób wyrazu chroniony prawem autorskim. Informacja o mechanizmie działania to wartość intelektualna.
Prostym dowodem na to jest fakt, że stwierdzenie plagiatu polega na stwierdzeniu zgodności danych a nie jej pojmowania przez człowieka. Dlatego system antyplagiatowy to komputer a nie “ludzie którzy to czytają i rozumieją”.
Popatrzmy na mapę:

Powyższy obrazek to prosta ilustracja tego, że :
- jako unikalny obraz (grafika) ta mapa jest chroniona prawem autorskim,
- treść tego obrazu – mapy – po jej zrozumieniu przez człowieka, to informacja o tym jak dotrzeć do skarbu; gdyby był to rysunek techniczny urządzenia, pozwalający odtworzyć (wytworzyć) to urządzenie lub przedmiot, mógłby on być elementem np. wniosku patentowego.
Podsumowanie
Ciekawie podsumowuje to Kinsella [zotpressInText item=”{5085975:Y4W6IFZI},{5085975:QAHTAUZ4}”]:
Prawa autorskie, chociaż nie doprowadziły do tak wielu jawnie absurdalnych zgłoszeń, zostały mocno rozciągnięte przez sądy. Pojęcie, pierwotnie mające na celu ochronę prac literackich, zostało tak rozszerzone, iż zawiera takie pisarskie „prace” jak programy komputerowe czy nawet kod maszynowy i kod wynikowy, którym bliżej do elementów maszyn, takich jak krzywka, niż do prac literackich.
Program komputerowy to tekst i jest chroniony prawem autorskim. Wszelkie inne precyzyjne, w tym graficzne, opisy reprezentujące określony mechanizm, np. realizowany z użyciem komputera, to także treść chroniona prawem autorskim. Jeżeli treść zapisana na tych schematach i w tym kodzie źródłowym, opisuje taki sam mechanizm działania, to znaczy że obie te treści opisują ten sam mechanizm. I teksty i rysunki to dokumenty.
Możliwe jest zarówno napisanie kodu programu na podstawie jego precyzyjnego opisu, jak i wykonanie precyzyjnego opisu na podstawie istniejącego już kodu. Pierwsze nazywamy implementacją projektu, drugie dokumentowaniem istniejącego kodu. Określenie tego kto od kogo skopiował opis tego mechanizmu, jest proste: to dająca się dowieść data powstania każdego z tych utworów, bo oba te dokumenty będą utworami w świetle prawa autorskiego. Drugi będzie utworem zależnym pierwszego.
Dodatek
Cały powyższy wywód zasadza się na pojęciu syntaktyki i semantyki treści. Syntaktyka to reguły poprawności zapisu treści. Semantyka to jego rozumienie (interpretacja, odczytanie) przez człowieka.
Ciekawostką jest to, że sama zrozumiała dla człowieka treść nie niesie informacji o tym czy stworzył ją inny człowiek czy maszyna: komputer jako maszyna może generować treść zrozumiałą dla człowieka, wystarczy do tego słownik prawdziwych wyrazów oraz algorytm, który na podstawie reguł – jakimi jest syntaktyka języka – wygeneruje ciągi wyrazów, które dla człowieka stanowią poprawne zdania w jego języku. Analogicznie można generować obrazy. Dlatego właśnie prawo autorskie zawiera klauzulę mówiącą, że autorem w świetle prawa, może być jedynie człowiek.
A co z obrazem lub tekstem wygenerowanym przez maszynę? Nic, maszyna z zasady jest jedynie narzędziem w rękach człowieka.
Poniżej jeden z najsłynniejszych eksperymentów ilustrującym to co nazywamy “sztuczną inteligencją”: człowiek czytając treści dla niego zrozumiałe nie jest w stanie określić czy stworzył je inny człowiek czy maszyna:
Maszyna może wg ustalonych reguł zmienić (przeredagować) treść, ale nie jest w stanie wytworzyć nowych znaczeń. Jeżeli jakieś oprogramowanie wytworzy tekst, obraz lub dźwięk wykorzystując wzorce syntaktyczne i fragmenty treści wytworzonej wcześniej przez człowieka, autorstwo tych treści: człowiek czy maszyna, będą dla człowieka nieodróżnialne. To jest ChatGPT i podobne….
Tak pisze o tym Noam Chomsky:
Ludzki umysł nie jest, jak ChatGPT i jemu podobni, ociężałym silnikiem statystycznym do dopasowywania wzorców, pochłaniającym setki terabajtów danych i ekstrapolującym najbardziej prawdopodobną reakcję konwersacyjną lub najbardziej prawdopodobną odpowiedź na pytanie naukowe. Wręcz przeciwnie, ludzki umysł jest zaskakująco wydajnym, a nawet eleganckim systemem, który działa z niewielkimi ilościami informacji; nie stara się wnioskować o brutalnych korelacjach między punktami danych, ale tworzyć wyjaśnienia.
Noam Chomsky: The False Promise of ChatGPT (The Times, March 8, 2023)
Źródła
[zotpressInTextBib style=”apa” sortby=”author” sort=”ASC”]
