24 Października 2024 Miała miejsce konferencja Kongres Cyfrowa Transformacja w Biznesie 2024. Zaproszono mnie do wygłoszenia referatu merytorycznego na temat:
Różne podejście do transformacji cyfrowej w obliczu długu technologicznego i systemów legacy. Jak przygotować organizację i jakie zmiany kultury organizacyjnej są niezbędne, aby transformacja cyfrowa mogła zakończyć się sukcesem.
pojęcie długu technologicznego,
czym jest dług informacyjny,
migracja “do nowego” i jak sie do niej przygotować,
zmiany kultury organizacyjnej czyli co to jest “deployment be design” jako metoda wdrażania,
czym tu jest sukces czyli jak go zdefiniować.
Poniżej slajdy z prezentacji i krótkie komentarze do kluczowych omówionych tez. Zapraszam na kolejne moje wystąpienia.
Od lat spotykam się w literaturze z zakresu zarządzania, z krytyką poczty elektronicznej jako narzędziem zarządzania czymkolwiek (patrz: Sabotaż…2013). Poczta elektroniczna (podobnie jak pakiety biurowe w ogóle) jest typowym przykładem maksymy: ułatwienie nie zawsze jest ulepszeniem. W kliencie poczty elektronicznej zarówno treść jak i sposób adresowania (co i do kogo, kopia, itp.) nie podlega żadnej standaryzacji ani restrykcji (poczta elektroniczna często służy do wyprowadzania danych z firmy). Jak dodać do tego fakt, że załączniki są niewidoczne w narzędziach do lokalnego wyszukiwania, że mamy na serwerach filtry antyspamowe których reguły nie poddają się kontroli użytkowników, że nie panujemy nad tym co inni mają w swoich skrzynkach pocztowych, to mamy obraz absolutnego braku panowania nad informacją w organizacji i chaosu.
Komunikacja czyli napisać, zapamiętać i doręczyć
Swego czasu dr Paweł Litwiński, prawnik, napisał krytyczny artykuł o zastosowaniu poczty elektronicznej przez adwokatów. Jego tekst był szeroko cytowany przez wielu autorów, tu jeden z takich artykułów. Wybrałem kilka ważnych kwestii:
Praktyka pokazuje, że wielu adwokatów i radców prawnych korzysta z darmowych skrzynek, także tych wprost zastrzegających sobie prawo do skanowania korespondencji. […]
Konflikt pomiędzy obowiązkiem ochrony informacji a warunkami narzuconymi w regulaminach darmowych usług to jedno. Czym innym są kwestie bezpieczeństwa.[…]
? Na logikę, lepiej żeby o materiałach objętych tajemnicą adwokacką nie dowiedział się żaden dostawca, ale z drugiej strony, rzadko której kancelarii prawnej uda się samodzielnie skonfigurować serwer pocztowy tak, aby był równie bezpieczny i nieawaryjny, jak infrastruktura np. Gmaila. Oczywiście, można zlecić to zewnętrznej polskiej firmie, ale wtedy mamy ten sam problem z zaufaniem, co w przypadku korzystania z serwerów np. Google ? zwraca uwagę Piotr Konieczny, ekspert ds. cyberbezpieczeństwa z serwisu Niebezpiecznik.pl. ? Abstrahując więc od aspektów prawnych, rozpatrując problem wyłącznie na płaszczyźnie bezpieczeństwa, tj. ochrony skrzynki przed atakami, moim zdaniem prawnikom niedysponującym budżetem na bezpieczeństwo takim, jaki posiadają profesjonalni dostawcy usług pocztowych, lepiej i prościej byłoby wykorzystać infrastrukturę np. Google?a ? dodaje. Jego zdaniem prawnicy powinni przede wszystkim rozważyć możliwość szyfrowania korespondencji. Wtedy zarówno darmowy, jak i płatny dostawca usług nie będzie w stanie jej podejrzeć. Szyfrowanie jest bez wątpienia najbezpieczniejszym sposobem, ale wiąże się z koniecznością dostarczenia klucza czy hasła odbiorcy, a ten nie zawsze godzi się na takie niedogodności. Co więcej, klienci kancelarii sami często korzystają z darmowych skrzynek. ? I nie rozumieją, dlaczego poufne informacje nie powinny być na nie przesyłane. Moim obowiązkiem jest wówczas poinformować takiego klienta o zagrożeniach z tym związanych. Oczywiście jeśli mimo tego będzie chciał używać takiej skrzynki do korespondencji ze mną, to nie mogę mu tego zabronić ? zwraca uwagę dr Paweł Litwiński. ? Z drugiej strony są również klienci, którzy wręcz wymagają, by w korespondencji z nimi używać jedynie skrzynek założonych na ich serwerach. Tak restrykcyjną mają politykę bezpieczeństwa. Chcąc dla nich pracować, adwokat czy radca musi przystać na te warunki ? dodaje ekspert.
W większości przypadków treść umieszczana jest w treści email??a lub w załączniku (załączone dokumenty). Jeżeli treść emaila nie jest szyfrowana (a generalnie nie jest, o ile sami o to nie zadbamy, co jednak, jak pokazuje cytowany Niebezpiecznik, nie jest trywialne) nasza korespondencja, przechodząc przez publiczne łącza sieci Internet, jest jawna i łatwa do podsłuchiwania. Jak uczynić naszą korespondencję (bardziej) niejawną?
Przypomnę kluczowe tezy powyższego artykułu. Generalnie ważnych dokumentów nie należy przesyłać jako załączniki z dwóch powodów: nie wiemy co sie z nimi dzieje po drodze, nie wiemy czy zostały dostarczone, i kiedy, gdyż bardzo wielu użytkowników email ma wyłączone automatyczne odesłanie potwierdzenia w swojej poczcie, co skutkuje tym, że po prostu jest to niewiarygodna forma potwierdzania. Poniżej schemat pokazujący drogę poczty email:
Droga poczty elektronicznej.
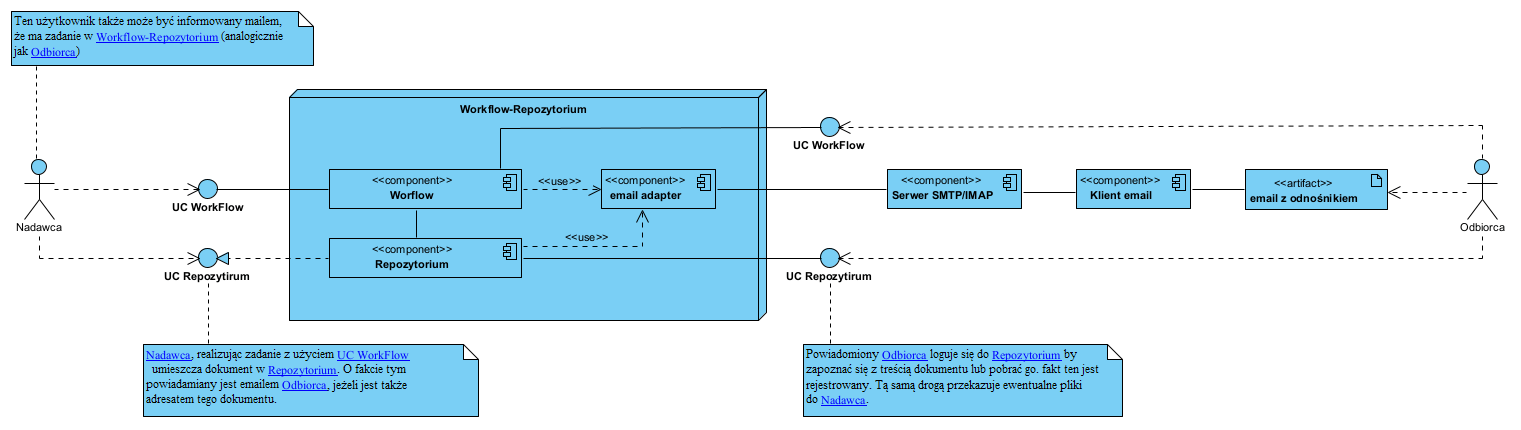
Środkowa część (Internet) to także potencjalne kolejne pośredniczące serwery, nie wiemy co sie na nich dzieje. Tak więc dwie kluczowe wady email to potencjalne skanowanie treści po drodze oraz brak kontroli nad doręczeniem. Czy można inaczej? Owszem: do przekazywania dokumentów można użyć repozytorium (serwera plików) z kontrolowanym dostępem. Poniżej schemat blokowy architektury niemającej ww. wad przesyłania dokumentów mailem:
Dokumenty przekazywane za pośrednictwem repozytorium
Dokumenty “w drodze” nie opuszczają repozytorium: z naszego komputera ładujemy je na serwer wskazując ewentualnie określonego adresata (lub robi to mechanizm obsługujący wymianę treści pomiędzy uczestnikami), określona osoba dostaje mailem informacje, że jest dla niej dokument, żeby go pobrać musi się zalogować do repozytorium. W efekcie treść (plik) nie jest nigdzie narażona na skanowanie, podejrzenie go itp. Tu email służy wyłącznie do monitowania faktu, że jest dokument do nas adresowany i że można do pobrać, co zostanie odnotowane.
Mając nawet proste, dostępne przez internet, repozytorium, można umieścić tam dowolny plik i mailem poinformować adresata (wcześniej zakładamy mu tam konto), że powinien pobrać plik. Serwer rejestruje zarówno moment załadowania pliku jak i jego pobrania, co jest gwarantowanym znakiem czasu nadania i doręczenia. Minus takiego rozwiązania to ręczna obsługa całego procesu, plus to panowanie nad wszystkim i bezpieczeństwo.
Sprawdzonym, od dawna, na rynku pomysłem jest system workflow z udostępnianym repozytorium, automatyzujący cały ten proces:
Architektura systemu wymiany danych z Repozytorium.
Uogólniając można go przedstawić jako serwer usług:
System workflow sterowany regułami
System doręczeń to tak naprawdę funkcjonalność aplikacji typu workflow zorientowanego na zadania (task manager), mającej możliwość udostępnienia jej kontrahentom. Funkcjonalność taką ma wiele systemów CRM, systemów helpdesk, wiele repozytoriów pozwala na skonfigurowanie subskrypcji zdarzeń powiązanych z dokumentami. Zbudowanie takiego systemu opartego na regułach, zamiast na macierzach praw dostępu do dokumentów, znakomicie upraszcza całość i dodatkowo podnosi bezpieczeństwo (bardzo ułatwia wdrażanie RODO) [zotpressInText item=”{5085975:E76NLXNX}”]. Ciekawą funkcjonalnością jest możliwość blokowania możliwości pobrania dokumentu na lokalny dysk, dozwolone jest jedynie przeglądanie treści w przewijanym oknie (oferują to niektóre tego typu systemy).
Systemy tego typu są także wdrażane jako zamiennik poczty elektronicznej wewnątrz organizacji. Tam gdzie podstawowym wewnętrznym systemem komunikacji jest poczta elektroniczna problemem są ginące dokumenty oraz brak dostępu do dokumentów (skrzynek) osób niedostępnych, będących poza firmą (chroba, delegacja itp.). Generalnie poczta jako “skład dokumentów” ma tę podstawową wadę, że dokumenty są rozproszone i zarzadzanie nimi w jednolity sposób jest niemożliwe. Stosowanie współdzielonych dysków nie rozwiązuje całkowicie problemu, bo po pierwsze nie da się budować reguł dostępu, po drugie wymiana dokumentów z osobami spoza firmy jest bardzo trudna (np. wymaga uruchomenia VPN co jest trudne, wymaga ingerencji w cudzy komputer, i coraz częściej nie jest to możliwe w wielu firmach).
Tak więc poczta elektroniczna, jako swobodna komunikacja między ludźmi owszem, jest przydatna. Jednak jako narzędzie do zarządzania komunikacją, przepływem treści, dokumentów ich wydań i doręczeń, jest bardzo zawodna. A warto wiedzieć, że prawna ochrona know-how w UE, czyli w Polsce także, to przede wszystkim obowiązek ochrony treści przez podmiot chroniący (udostępniający) takie dane. Dlatego dość kuriozalnie wygląda każda firma, która wysyłając mailem umowę o poufności (NDA) wysyła potem także mailem te “poufne” dokumenty…
Na zakończenie
Rozwiązań, realizujących opisane wyżej funkcje, nie brakuje. Główną blokadą ich wdrażania jest przyzwyczajenie do swobody. Jednak poczta elektroniczna jest klasycznym przykładem tego, że ułatwienie nie zawsze jest ulepszeniem. O wdrażaniu systemów workflow, panujących nad komunikacją i jej poufnością, mówi się podobnie jak o systemach kopii zapasowych: firmy dzielą się na te, które wdrożyły skuteczny workflow i na te które wdrożą.
Kilka przykładów (nie oferuję tych systemów, to nie są rekomendacje a przykłady):
Biuro księgowe, które mnie obsługuje, odeszło od prostego systemu FK i komunikacji mailowej (przekazywanie dokumentów kosztowych, wysyłanie klientom deklaracji podatkowych, raportów itp.), obecnie korzysta z podatkipodatki.pl.
Zaczynałem jak wielu od poczty elektronicznej, po kilku przygodach z dokumentami w projektach (kto, co, kiedy i komu) szybko wdrożyłem darmowy, potem supportowany osTicket (na początek bardzo dobry i łatwy we wdrożeniu).
Z uwagi na specyfikę mojej pracy (praca polegająca na zbieraniu danych i tworzeniu raportów z analiz, ich recenzowanie przez klientów) używam obecnie do komunikacji bardziej zaawansowanego oprogramowania PostMania.
U wielu klientów spotykam, popularny w serwisach i firmach IT, Mantis.
Do zarządzania procesem negocjowania i podpisywania umów, wiele firm i ich prawników używa oprogramowania Pergamin.
Polecam rozważenie rezygnacji z poczty elektronicznej do przekazywania dokumentów projektowych, nie tylko z uwagi na ich bezpieczeństwo ale głównie z uwagi na zarządzanie nimi i kontrole w całym cyklu życia dokumentu.
Ważne
W tym przypadku zastosowanie znajduje art. 61 k.c., zgodnie z którym oświadczenie woli, które ma być złożone innej osobie, jest złożone z chwilą, gdy doszło do niej w taki sposób, że mogła zapoznać się z jego treścią (§ 1). Natomiast oświadczenie woli wyrażone w postaci elektronicznej jest złożone innej osobie z chwilą, gdy wprowadzono je do środka komunikacji elektronicznej w taki sposób, żeby osoba ta mogła zapoznać się z jego treścią (§ 2). Wystarczające jest natomiast by oświadczenie woli dotarło do adresata w taki sposób, że miał możliwość zapoznania się z jego treścią, bez względu na to czy rzeczywiście to nastąpiło (Wyrok SA w Poznaniu z 17.04.2024, I AGa 236/22).
Tym razem opisuję kwestie dokumentu, dokumentowej postaci czynności prawnej i faktur w wersji elektronicznej, których wystawianie jest jak najbardziej czynnością prawną, i o innowacji jaką Minister Finansów serwuje nam od nowego roku.
W 2018 roku opisywałem metody uwiarygodniania treści (dokumentów) podsumowując:
Tego typu metody zabezpieczenia (tak zwane systemowe, w przeciwieństwie do technicznych, jaką jest kwalifikowany podpis elektroniczny), są oparte na założeniu, że sfałszowanie treści dokumentu jest niemożliwe (lub jest wykrywalne w 100%) przy zachowaniu ustalonej procedury doręczenia dokumentu (patrz: Zasada Kerckhoffs?a). Wymagania nakładane formalnie na podmiot stanowiący Trzecią stronę zaufania (notariusz) powodują, że ryzyko niewykrycia fałszerstwa jest bliskie zeru. Opisane powyżej metody wymiany dokumentów nie wymagają kosztownego i trudnego w użyciu kwalifikowanego podpisu elektronicznego (źr.: Przesyłki sądowe dostarczane przez internet czyli e-dokumenty c.d.)
Generalnie chodziło o alternatywę dla e-podpisu, który nadal uważam za ślepą uliczkę. Od wielu lat, projektując systemy informatyczne, stosują zasadę mówiącą. że system informatyczny, jako rozwiązanie, nie powinien tworzyć nowych, sztucznych bytów informacyjnych, bo im więcej takich sztucznych (nie istniejących w rzeczywistości) bytów powstanie, tym bardziej system odstaje od realiów rzeczywistości, którą (podobno) ma wspierać. Praktyka pokazuje, że próby implementacji w systemach informacyjnych mechanizmów dalekich od realiów życia, kończy się ogromnym kosztem i często po prostu porażką.
Warto mieć świadomość, że strukturalne i stałe w czasie dane, stanowią mniej niż 20% procent wszystkich danych jakie człowiek tworzy, próby stosowania modelu relacyjnego i SQL do pozostałych ponad 80% danych (dokumentów) to droga do klęski.
On top of this, there is simply much more unstructured data than structured. Unstructured data makes up 80% and more of enterprise data, and is growing at the rate of 55% and 65% per year. (źr.: Structured vs Unstructured Data 101: Top Guide | Datamation)
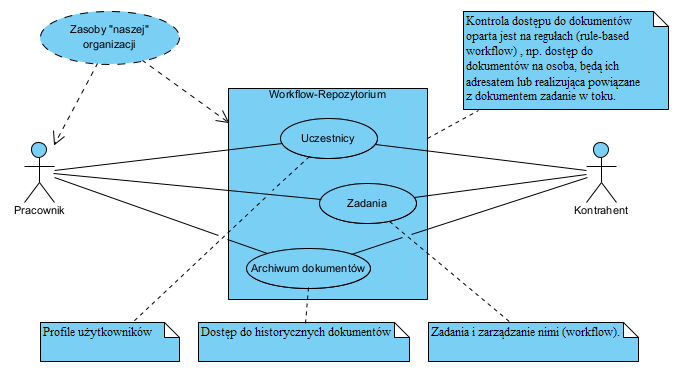
Profil UML i meta-model typów dokumentów jako system organizacji danych. Dokument jako kontekstowa struktura informacyjna.
Streszczenie: Opisano sprawdzona w praktyce metodę składowania danych zorganizowanych w dokumenty. Opisana metoda nie ma wad relacyjnego modelu organizacji danych, jakim jest utrata kontekstu danych i komplikacje wywołane brakiem redundancji danych. W pracy tej przedstawiono metodę organizacji danych w dokumenty jako sklasyfikowane agregaty, metodę ich klasyfikacji oraz metamodel ich budowy. Opisany metamodel zakłada, że dokumenty jako struktury danych to zwarte agregaty, klasyfikowane jako opisy obiektów (object) lub wydarzeń (events) co nadaje im zawsze określony i jednoznaczny kontekst. Opisano także metodę projektowania dokumentów jako agregatów kontekstowych, co pozwala zniwelować wskazane wady modelu relacyjnego oraz zagwarantować skuteczność zarządzania informacją. Dodatkowo opisany model rozwiązuje problemy zarządzania dostępem do danych poprzez określanie dostępu do całego kontekstowego dokumentu, a nie do poszczególnych pól. Dzięki temu zarządzanie dostępem do danych staje się znacznie prostsze.
Słowa kluczowe: systemy informacyjne, inżynieria oprogramowania, bazy danych, BCE, agregat, metody obiektowe, paradygmat obiektowy, inżynieria systemów, DDD, aggregate
1. Wprowadzenie
W wielu projektach, których celem jest zarządzanie informacją i przetwarzanie jej, pojawia się problem z opracowaniem modelu danych. Często a priori przyjmuje się, że dokumenty to informacja organizowana w postaci formularzy złożonych z określonych pól, a te będą przechowywane w modelu relacyjnym [Shimura, T., Yoshikawa, M., Uemura, S., 1999]. Model ten prowadzi do sytuacji gdzie: <dokument> = <zbiór danych w modelu relacyjnym> + <zapytanie SQL do tego zbioru>. Innymi słowy dokumenty to dynamicznie generowane treści, nie istniejące jako trwałe byty. Dla rozbudowanych modeli danych procedury nazwane <zapytanie SQL do tego zbioru> są bardzo złożone i ich wykonanie generuje duże zapotrzebowanie na czas i moc procesora. Ich opracowanie i testowanie jest kosztowne, bo zajmuje wiele czasu specjalistów, którzy je tworzą. Nie mniej kosztowne jest wprowadzanie do nich zmian w cyklu życia oprogramowania.
Dokumenty bardzo często zawierają bardzo wiele różnych informacji stanowiących sobą złożone wielokontekstowe zestawy (agregaty) danych. Zastosowanie modelu relacyjnego do organizowania takich informacji, prowadzi do powstania złożonego systemu powiązanych relacyjnie tabel a usuwanie redundancji prowadzi często utraty kontekstu treści poszczególnych pól w tabelach. W konsekwencji pojawia się konieczność stosowania bardzo złożonych zapytań w języku SQL, by dokumenty te zapisywać w takiej bazie i odtwarzać z niej. W samej bazie są to tylko pozbawione kontekstu dane w tabelach a nie dokumenty.
Wielu autorów zwraca uwagę na problem złożoności i utraty kontekstu jednolitych modeli relacyjnych, zalecając separowanie kontekstów w dużych relacyjnych modelach danych, jednak poprzestają oni tylko na rekomendacji by te konteksty separować [EVANS 2003, M.Fowler 2014] pozostając nadal przy modelu relacyjnym, co nie rozwiązuje problemu całkowicie [Awang, M.K., Labadu, N.L., Campus, G.B., 2012].
Zmiana kontekstu często zmienia znaczenie danych [Danesi, M., 2004]. Próby zachowania tego znaczenia prowadzą często do powstawania rozbudowywania relacyjnych modeli danych, co z kolei powoduje dodatkowy koszt. W konsekwencji stosowanie jednego modelu relacyjnego danych do zapisu treści wielu różnych dokumentów powoduje, że system taki staje się wielkim i niepodzielnym monolitem, kosztownym w opracowaniu i utrzymaniu.
Stosowane jest też podejście, w którym oprogramowanie przetwarza dokument (jego treść) traktując go jako samodzielny obiekt zapisując jednak jego treść (poszczególne pola) w modelu relacyjnym [O?Neil, E. J. (2008)] co powoduje dodatkowy nakład pracy w toku projektowania takiego systemu oraz duże zapotrzebowanie na moc procesora w trakcie odczytu i zapisu dokumentów z pomocą dodatkowej warstwy aplikacji, jaką jest tu mapowanie obiektowo-relacyjune (ORM, Object-Relational Mapping). Problem ten jest często nazywany niedopasowaniem oporu modelu relacyjnego i obiektowego (object-relational impedance mismatch) [Ireland, C., Bowers, D., 2015].
Celem badań było znalezienie odpowiedzi na pytanie dlaczego tylko ok. 10% wdrożeń systemów informacyjnych kończy się sukcesem [The Standish Group International, Inc. (2015)] i czy inny niż, nie raz krytykowany za nieskuteczność [Cook, S., & Daniels, J. (1994)] relacyjny korporacyjny model organizacji danych, pomoże zwiększyć skuteczność tych projektów. Obszar badań autora to modele jako metody analizy i projektowania a metamodele jako narzędzie budowy teorii (patrz także Gray, J., & Rumpe, B. (2019)).
2. Użyte metody i narzędzia
Materiałem źródłowym do analiz pojęciowych i struktur danych były dokumenty w badanych firmach, w szczególności w obszarze finanse i księgowość, zarządzanie produktami, rejestry nieruchomości a także archiwa plików multimedialnych. Były to dane dostępne dla autora w toku pracy zawodowej.
Opisane tu metody projektowania dokumentowych struktur danych zostały zastosowane przez autora w kilku projektach. Uzyskane efekty pokazały przewagę tej formy analizy i projektowania struktur danych do celów zarządzania wiedzą, w porównaniu do metod opartych na relacyjnym modelu danych.
Jako podstawowe narzędzia wykorzystano w pracy analizę pojęciową i obiektową oraz modelowanie obiektowe. Do udokumentowania wyników wykorzystano systemy notacyjne: Semantic Business Vocabulary and Rules [SBVR 2017] oraz Unified Modeling Language [UML 2017]. Wykorzystano także wiedzę z zakresu semantyki [semantic triangle Sowa, J.F., 2000] oraz pojęcia klasy, klasyfikatora i obiektu [UML 2017]. Celem tej publikacji jest prezentacje opracowanej metody a nie przegląd systemów projektowanych i wdrażanych przez autora.
3. Wyniki
Opracowano system standaryzacji organizowania informacji, jej przechowywania i przetwarzania. W wyniku tych prac opracowano metamodel i profil UML, dla architektury modelowania danych metodą organizacji ich w dokumenty. Opracowano metody projektowania struktur dokumentów gromadzących informacje. Opiera się ona na założeniu, że dokumenty stanowią agregaty danych George Papamarkos, Lucas Zamboulis, Alexandra Poulovassilis, 2015]).
3.1. Przetwarzanie informacji
Informacje zawsze są o czymś, innymi słowy opisują coś co istnieje lub mogłoby zaistnieć. Jeżeli mówimy, że system informatyczny przetwarza informacje, to znaczy, że przetwarza dane, które są zapisanymi informacjami (dane oczywiście mogą nie nieść żadnej informacji, ale w tej publikacji się tym nie zajmuję).
Rysunek 1. Przetwarzanie informacji o tym co jest i co zaszło
Na diagramie Rysunek 1. Przetwarzanie informacji o tym co jest i co zaszło pokazano schematycznie związek między światem rzeczywistym (Świat opisywany danymi), danymi zapisanymi metodami tradycyjnymi (Dokumenty papierowe (nośniki danych) i danymi zapisanymi i przetwarzanymi z użyciem oprogramowania, tu: Aplikacja zarządzająca danymi.
Innymi słowy Dokumenty papierowe (nośniki danych) “niosą” dane stanowiące określone informacje o świecie rzeczywistym. Stanowią więc sobą informacje o historii, czyli informacje o stanie “świata rzeczywistego” w czasie przeszłym. Mogą to być także informacje o czasie przyszłym, są to np. plany lub prognozy.
Celem tworzenia oprogramowania jest przetwarzanie danych, stanowiących określone informacje, które opisują określone elementy świata rzeczywistego. Struktura tych danych, powinna odpowiadać strukturze rzeczy, które są opisywane (o których informacje przetwarzamy) [Mountriver 2011,Smith 1985]. Wynalezienie komputera otworzyło nowe możliwości przetwarzania (wdrożenie oprogramowania – kierunek zmian), ale nie zmienia rzeczywistości opisywanej danymi przetwarzanymi w nim, gdzie same dokumenty jako takie, także są elementem tej rzeczywistości.
Zgodnie z tym co już napisano, informacje opisują albo zdarzenie albo obiekt. Złożone dokumenty mogą zawierać wiele informacji, jednak powinno być możliwe przyporządkowanie danego dokumentu do jednego z typów: opis obiektu lub opis zdarzenia, gdyż jak już napisano, jeden dokument może (powinien) mieć jeden kontekst, z uwagi na wymaganą jednoznaczność jego treści (kontekst). W dalszej części opisano dlaczego.
Rysunek 2. Obiekt i jego historia
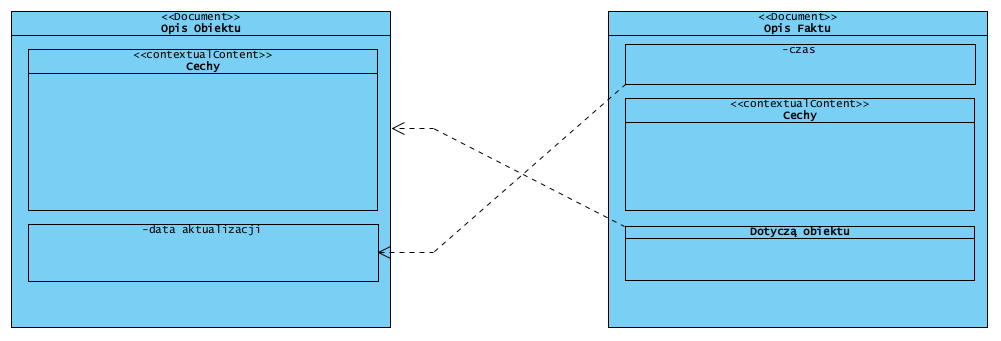
W sytuacji przedstawionej na diagramie Rysunek 2. Obiekt i jego historia, mamy jeden obiekt i trzy związane z nim zdarzenia. To znaczy, że powinny tu istnieć – co postuluję – cztery niezależne opisy (dokumenty): jeden to wersjonowany opis obiektu, pozostałe trzy to opisy faktów do jakich doszło w związku z tym obiektem. Kluczowe jest przyjęcie zasady: dokument może mieć jeden z dwóch możliwych kontekstów: informacje o obiekcie lub informacje o zdarzeniu.
Pojęcie przedmiot (subject), zobrazowano i opisano w dalszej części na diagramie Rozszerzony model pojęciowy. Ma ono tylko dwa typy: zdarzenie oraz obiekt (“Data are symbols that represent the properties of objects and events” [Ackoff, R.L., 1999. ]). Taksonomia ta ma kluczowe znaczenie w opracowanym metamodelu. Źródłem tego podziału jest kontekst opisu, co pokazano na diagramie Rysunek 2. Obiekt i jego historia. Obiekt niezmiennie trwa w czasie. Może on ulegać zmianom: ma cykl życia, ale co do zasady trwa, zmiany są (mogą być) skutkiem określonych zdarzeń, powiązanych z tym obiektem. Zdarzenia jednak nie muszą zmieniać przedmiotu, mogą go jedynie “dotyczyć”. Obiekty (object) i zdarzenia (events) definiowane są przez ich cechy (properties).
To co łączy zdarzenia z obiektami to określone czas i miejsce zdarzenia. Obiekt, którego zdarzenie dotyczy, jest elementem jego opisu. Obiekt niezmiennie trwa w czasie, więc wiąże się z nim także pojęcie jego cyklu życia: jest to jego historia. Historia obiektu to zbiór powiązanych z nim zdarzeń (których dany obiekt był uczestnikiem). Zdarzenia i obiekty opisujemy z użyciem cech. Zdarzenie i obiekty muszą być unikalne (odróżniamy je od siebie), jednak wartości poszczególnych cech nie muszą już być unikalne, np. ta sama data wielu różnych zdarzeń, to samo miejsce wystąpienia różnych zdarzeń. Wartości (value) cech (properties) nie są ani zdarzeniem ani obiektem, choć mogą mieć złożoną strukturę (np. pełny adres pocztowy jest wartością cechy położenie, ale nie jest ani zdarzeniem ani obiektem). To dlatego nie są one typem tematu. Temat opisu to albo obiekt albo zdarzenie. Jeżeli przyjmiemy założenie, że kontekst określa znaczenie pojęć, opis zaś składa sie z pojęć, to w konsekwencji określony dokument, by jego treść była jednoznaczna, może mieć tylko jeden kontekst.
Z perspektywy przetwarzania danych nie ma znaczenia czy zdarzenie (event) jest z przeszłości czy przyszłości bo oba maja identyczne cechy (dane opisujące: atrybuty). Pojęcie czasu ma znaczenie dla człowieka który interpretuje dane (patrz A-theory and B-theory, [Mountriver 2011]). Dlatego system informatyczny posortuje chronologicznie zdarzenia, ale określenie czy dane zdarzenie było czy będzie, wymaga skorelowania daty tego zdarzenia (jego cecha) z datą dnia gdy pytanie takie jest zadane. Innymi słowy pytanie o “zdarzenia wczorajsze” każdego dnia da inny wynik mimo, że dane o zdarzeniach nie ulegają zmianie.
Opis obiektu vs. opis Faktu – informacja jako agregat danych
Kluczowe reguły: dokument jest klasyfikowany albo jako opis obiektu albo faktu, opis faktu nie może być modyfikowany, opis obiektu może być (aktualizacja stanu faktycznego). Modyfikacja opisu obiektu jest faktem (który należy udokumentować), fakt musi dotyczyć co najmniej jednego obiektu.
(kompletny tekst ma 26 stron, zawiera kompletny opis metody i metamodel informacji organizowanych w dokumenty, przykłady użycia metody; data i miejsce publikacji będą tu podane w komentarzach, które można subskrybować, publikacja ukazała sie w 2021 roku [zotpressInText item=”{5085975:9KMR85JV}”])
Uzupełnienie
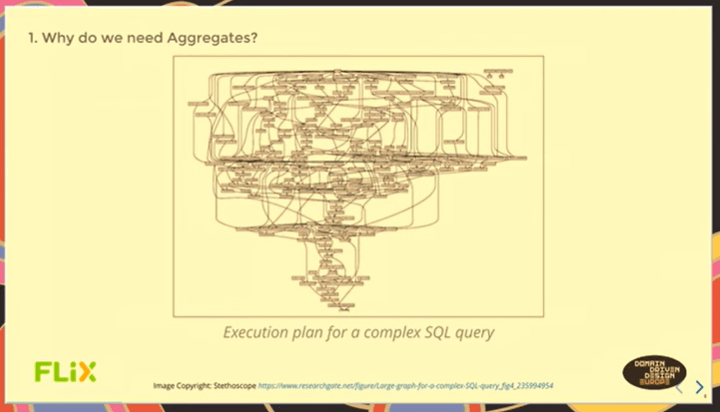
[Marzec 2023] Zarządzanie zestawem powiązanych danych jako agregatem jest bardzo efektywne. Traktowanie dokumentów jako agregatów to sposób na budowanie bardzo efektywnej architektury. Niedawno ukazała się bardzo ciekawa prezentacja na temat agregatów w DDD. Autor pokazuje jakim ogromnym problemem są zapytania do relacyjnych baz danych już w systemach mających kilkadziesiąt tabel i jakim “dobrodziejstwem” jest operowanie pojęciami Aggregate i Value Object.
The One Question To Haunt Everyone: What is a DDD Aggregate? – Thomas Ploch – DDD Europe 2022
Struktura i treść dokumentu (formularz jako agregat) może być zapisana i potem odzyskana w bazie danych o relacyjnym modelu danych, poniżej struktura zapytania SQL do tej bazy (kilkaset tablic):
Struktura zapytania SQL do bazy relacyjnej, w której zapisano Strukturalny formularz.
Po obejrzeniu całej powyższej prezentacji pomyśl, że struktura i treść dokumentu (formularz jako agregat) może być wyrażona także w postaci jednego ciągu znaków XML (lub JSON, itp.) jako wartość jednego pola dowolnej bazy danych (szczególnie bazy NoSQL) a zapytanie do takiej bazy danych to polecenie na kilka słów. Wtedy obiekt niosący taki XML jest właśnie tym ‘entity’, korzeniem i tożsamością całego agregatu, tyle, że powyższe monstrualne zapytania SQL do relacyjnej bazy nie są już potrzebne.
Agregat – kontekst treści formularza
[Grudzień 2023] Jako ludzie zapisujemy informacje z zasady w określonym kontekście. To co dla nas jest informacją, dla papieru (i każdego innego nośnika) jest znakiem (znakami). Znaki do dane, których nie rozumie ani nośnik ani stos reguł (procedura). Czyli komputer też nie rozumie!
Standardową “ludzką” formą zapisu są dokumenty i formularze. Dokument ma kontekst, każda część dokumentu także. Poniższy formularz to dwa identyczne zestawy danych o dwóch osobach, pełniących jednak różne role. Ten dokument to: kontekst dokumentu oraz zagnieżdżone dwa konteksty osób (ich role).
Wyobraźmy sobie, że mamy kilkadziesiąt takich różnych dokumentów, każdy ma swój własny inny kontekst, i na każdym powtarzają się pewne dane (w innym kontekście). Żadna z tych danych nie jest liczbą, na której można wykonać operację matematyczną.
Jaki sens ma ładowanie danych z wielu różnych formularzy (pól i ich wartości) do jednego systemu relacyjnych tabel i pozbawianie ich kontekstu i redundancji? Ile pracy należy włożyć w każdorazowy zapis i odtworzenie każdego z tych formularzy?
Standard clean application form. Document template admission of a foreigner traveling abroad, application vector for filling out passports, immigrant visas.
O tym, że liczby nie są dobrym pomysłem na “bycie danymi” pisał także [zotpressInText item=”{5085975:IS7I7MFC}”]:
Why the number input is the worst input. Think that web form has got your number? If you used input type=”number”, you may be surprised to find that it doesn’t.
Nowe przepisy uznają za dokumenty i dopuszczają jako dowody w sądzie e-maile, esemesy, nagrania audio czy wideo, wręcz ?każdy nośnikinformacji umożliwiający zapoznanie się z jej treścią“. Te nośniki będą zrównane z pismem papierowym. W elektronicznej formie (tzw. dokumentowej), będzie też można zawierać umowy, składać wiążące oświadczenia.
Z tymi oczywistymi ułatwieniami, wynikającymi z postępu techniki i zmian zwyczajów w biznesie, wiąże się niestety też ryzyko.
? W e-korespondencji strony powinny zachować szczególną ostrożność. Adresat e-maila czy nagrany rozmówca może bowiem opacznie odczytywać oświadczenia składane w formie elektronicznej i wykorzystać je potem w sądzie ? wskazuje Monika Leszko, radca prawny w kancelarii DLA Piper. ? Pierwsza rada, jaka się nasuwa, jest taka, by w takiej korespondencji wyraźnie zastrzegać, że nie jest to np. oferta czy zgoda. (źr. RP.pl)
Chciałbym się tym razem skupić na wytłuszczonej w cytacie treści. Problemem z jakim muszą się zmierzyć między ustawodawca, urzędy, ale także autorzy “dokumentów”, jest zapewnienie porządku pojęciowego dla zachowania poprawnej i jednoznacznej komunikacji. W szczególności dotyczy to podkreślonych powyżej pojęć: nośnik, informacja, treść, opacznie zrozumieć.
Cztery lata temu zwracałem uwagę na to samo (głownie treść, oryginał, kopia, nośnik) ale w kontekście praw autorskich i ustawy ich dotyczącej:
Dzieło może mieć postać materialną i niematerialną. Dzieło materialne (rzeźba, obraz malarski) ma swój oryginał, mogą powstać reprodukcje. To drugie dzieło, niematerialne, dotyczy w szczególności utworów muzycznych, zdjęć czy treści (każda wypowiedź to proza lub poezja ;)). Dzieło niematerialne może być utrwalone na wybranym nośniku (muzyka na płycie CD, proza na papierze, ?), wtedy powstają jego egzemplarze.
Artykuł ten zwraca uwagę na problemy jakie stwarza między innymi “rozłączność treści i nośnika oraz na stwierdzeniu czym jest oryginał, kopia i egzemplarz. Kluczowe są tu pojęcia: nośnik, dzieło (dane), oryginał i kopia.
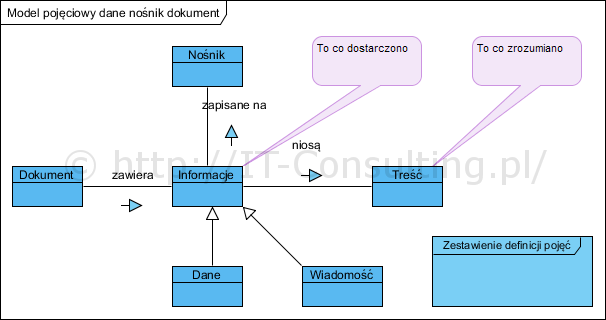
Na czym polega problem? Zbudujmy model pojęciowy dla problemu dokumentu i jego roli:
Diagram czytamy tak: dokument to informacje utrwalone na nośniku. Informacją są dane lub wiadomości niosące określoną treść. Dla porządku przytaczam przyjęte definicje tych pojęć (na podstawie sł. j.polskiego PWN):
Skupmy się na tym, że dowodem może być “każdy nośnikinformacji umożliwiający zapoznanie się z jej treścią” i na tym, że ktoś “może bowiem opacznie odczytywać oświadczenia składane w formie elektronicznej i wykorzystać je potem w sądzie”.
Z perspektywy teorii komunikacji za treść (to co zrozumiano) odpowiada nadawca (autor) treści i dobra rada, żeby w treści “wyraźnie zastrzegać” o co chodzi, jest jak najbardziej właściwa. Jednak teoria komunikacji nie jest tu głównym wątkiem ani problemem :).
Pozostaje kwestia nośnika i danych (wiadomości) niosących ową treść. Oczywiście można użyć podpisu elektronicznego, jednak jego powszechność w Polsce jest znikoma (nieco ponad milion, z tego aktywnych ok. 1/3, podobnie jak i profilu zaufanego na ePUAP). Pojawia się nowe pojęcie: forma dokumentowa (zamiast “forma pisemna”):
Ustawodawca postanowił, że forma dokumentowa będzie zachowana wówczas, gdy oświadczenie woli zostanie złożone w postaci dokumentu, w sposób umożliwiający ustalenie osoby składającej to oświadczenie. Warto podkreślić, że podpis w takim przypadku nie jest elementem koniecznym dla zachowania tej formy czynności prawnej. Wymagane jest natomiast istnienie dokumentu, czyli, zgodnie z wprowadzanym przez nowelizację przepisem, nośnika informacji umożliwiającego zapoznanie się z jej treścią. Drugorzędna jest natomiast fizyczna postać tego nośnika ? może to być papier, jak i np. plik komputerowy ? ważne jest, by sposób zapisania na nim informacji umożliwiał jej utrwalenie i odtworzenie. (Źródło: Nowe formy czynności prawnych w Kodeksie cywilnym – Aktualności, Zmiany w prawie, NL Zmiany w prawie – Czytaj – kancelaria.lex.pl)
Ustawodawca moim zdaniem słusznie godzi się na dopuszczenie dokumentów niepodpisanych elektronicznie (mail, SMS, dokument na pendrive itp.) do “obiegu” w urzędach i sądach. Głównym, w moich oczach, dotychczasowym problemem było praktyczne wykluczenie znacznej większości obywateli z komunikacji drogą elektroniczną, a powodem jest brak powszechnego używania wspomnianego podpisu i profilu.
Ustawodawca doprecyzowuje definicję: “dokumentem jest nośnik informacji umożliwiający zapoznanie się z jej treścią”. Zakładam, że intencją jest, by nie uznać za dokument tego co z powodów np. technicznych, nie jest możliwe do odczytania przez adresata (sąd, urząd, …). Rodzi to ryzyko uznaniowości (a ja nie mam jak tego odczytać). Tu sugeruję dokumentować (ustalać) zasady komunikacji lub żądać co najmniej oświadczenia o tym jakie “dokumenty” adresat jest w stanie odczytać by “zapoznać się z ich treścią”.
Pewną ciekawostka jest natomiast dla mnie zapis:
w art. 73 § 1 otrzymuje brzmienie:
?§ 1. Jeżeli ustawa zastrzega dla czynności prawnej formę pisemną, dokumentową albo elektroniczną, czynność dokonana bez zachowania zastrzeżonej formy jest nieważna tylko wtedy, gdy ustawa przewiduje rygor nieważności.?;
Skoro użyto trzech odrębnych pojęć “pisemną, dokumentową albo elektroniczną” to znaczy że ich znaczenia się (powinny) wzajemnie wykluczają. Jak więc to rozumieć w świetle definicji pojęć powyżej? Firma pisemna to każda forma “utrwalona”. Dokument jest niczym innym jak właśnie formą utrwaloną (na nośniku). Forma elektroniczna to treść na nośniku, w formie elektronicznej. Ciekaw jestem interpretacji prawników…
Jednak dalej czytamy:
Art. 781
. § 1. Do zachowania elektronicznej formy czynności prawnej wystarcza złożenie oświadczenia woli
w postaci elektronicznej i opatrzenie go bezpiecznym podpisem elektronicznym weryfikowanym przy pomocy ważnego kwalifikowanego certyfikatu.
Co nieco burzy moje zrozumienie całości…
Jakie ryzyka powoduje rezygnacja z podpisu dokumentu w wersji elektronicznej? Generalnie rzecz biorąc dotyczy to uwiarygodnienia: informacji, daty jej powstania, daty doręczenia. Pamiętajmy, że w powszechnym obrocie są dokumenty papierowe. Co jest ich kluczową cechą? Nierozłączność informacji i nośnika oraz relatywnie duża trudność w sfałszowaniu (i treści i odręcznego podpisu). W kwestii doręczenia radzimy sobie wysyłając dokument za poświadczeniem odbioru.
W wersji elektronicznej oddzielono pojęcie treści od nośnika z powodów jak wyżej, z tego także powodu straciło sens pojęcie kopii i oryginału: istotne są informacje a nie forma zapisu i liczba egzemplarzy (ustawodawca zrobił tu już formalnie w przypadku faktur). W konsekwencji stwierdzenie czy informacja była zmieniana staje się bardzo trudne.
Stan obecny, mimo że jest bardzo wygodny, rodzi jednak ryzyka związane z trudnością zagwarantowania autentyczności dokumentu. Zapis na nośnikach wielokrotnego użytku (np. pendrive, karty pamięci…) jest potencjalnie podważalny. Ja osobiście stosuje nagrania na płytach CD-R/DVD. Raczej trudno podważyć niemodyfikowalość zapisu na nich. Co do daty doręczenia/powstania to w przypadku rzeczy ważnych (czyli rodzących duże ryzyko) warto takie nośniki tworzyć u kogokolwiek, kto dysponuje ważnym podpisem elektronicznym, gdyż cudzy podpis zawiera także znacznik czasu, co uwiarygodni datę powstania treści. Nie zmienia to faktu, że podpisanie się na takiej płycie niezmywalnym pisakiem czyni ją “nie gorszą” od podpisanego papieru ;).
Formą łatwą i tanią oceny wiarygodności treści jest uznanie kontroli krzyżowej jako weryfikatora. Tak są weryfikowane od lat niepodpisywane faktury (porównanie treści u wystawcy i odbiorcy).
Artykuł ten ma na celu zwrócenie uwagi na problemy i ryzyka związane z nowymi przepisami a nie rozwiązywanie ich. Mam nadzieję, że większe ich zrozumienie przyczyni się do większej dbałości o swój interes i stosowanie tak prywatnie jak i w prowadzonej działalności, mechanizmów minimalizujących ryzyka korzystania z dokumentów elektronicznych. Osobiście nie korzystam z podpisu elektronicznego, do urzędów, w tym Urzędu Skarbowego, od lat wysyłam zwykłe email’e. Owszem korzystam także z papieru i Poczty Polskiej, gdyż wychodzę z założenia, że należy dostosowywać środki do celu, a nie “być za wszelką cenę” nowoczesnym.
(Tekst ustawy: Ustawa z dnia 10 lipca 2015 r. o zmianie ustawy – Kodeks cywilny, ustawy – Kodeks postępowania cywilnego oraz niektórych innych ustaw)


![Przetwarzanie informacji o tym co jest i co zaszło
Na diagramie Przetwarzanie informacji o tym co jest i co zaszło pokazano schematycznie związek między światem rzeczywistym (Świat opisywany danymi), danymi zapisanymi metodami tradycyjnymi (Dokumenty papierowe (nośniki danych) i danymi zapisanymi i przetwarzanymi z użyciem oprogramowania, tu: Aplikacja zarządzająca danymi.
Innymi słowy Dokumenty papierowe (nośniki danych) "niosą" dane stanowiące określone informacje o świecie rzeczywistym. Stanowią więc sobą informacje o historii, czyli informacje o stanie "świata rzeczywistego" w czasie przeszłym. Mogą to być także informacje o czasie przyszłym, są to np. plany lub prognozy.
Celem tworzenia oprogramowania jest przetwarzanie danych, stanowiących określone informacje, które opisują określone elementy świata rzeczywistego. Struktura tych danych, powinna odpowiadać strukturze rzeczy, które są opisywane (o których informacje przetwarzamy) [Mountriver 2011,Smith 1985]. Wynalezienie komputera otworzyło nowe możliwości przetwarzania (wdrożenie oprogramowania - kierunek zmian), ale nie zmienia rzeczywistości opisywanej danymi przetwarzanymi w nim, gdzie same dokumenty jako takie, także są elementem tej rzeczywistości.
Zgodnie z tym co już napisano, informacje opisują albo zdarzenie albo obiekt. Złożone dokumenty mogą zawierać wiele informacji, jednak powinno być możliwe przyporządkowanie danego dokumentu do jednego z typów: opis obiektu lub opis zdarzenia, gdyż jak już napisano, jeden dokument może (powinien) mieć jeden kontekst, z uwagi na wymaganą jednoznaczność jego treści (kontekst). W dalszej części opisano dlaczego.](https://it-consulting.pl//wp-content/uploads/2020/10/przetwarzanie-informacji-o-tym-co-jest-i-co-zaszlo.png)
![Obiekt i jego historia
W sytuacji przedstawionej na diagramie Obiekt i jego historia mamy jeden obiekt i trzy związane z nim zdarzenia. To znaczy, że mogły by istnieć - co postuluję - cztery niezależne opisy (dokumenty): jeden opisujący obiekt i trzy opisujące zaszłe zdarzenia. Te cztery opisy to hipotetyczne cztery dokumenty, jednak każdy z nich byłby opisem albo zdarzenia albo obiektu. Kluczowe jest przyjęcie zasady, że dokument może mieć jeden z dwóch możliwych kontekstów: informacje o obiekcie lub informacje o zdarzeniu.
Pojęcie przedmiot (subject), zobrazowano i opisano w dalszej części na diagramie Rozszerzony model pojęciowy. Ma ono tylko dwa typy: zdarzenie oraz obiekt ("Data are symbols that represent the properties of objects and events" [Ackoff, R.L., 1999. ]). Taksonomia ta ma kluczowe znaczenie w opracowanym metamodelu. Źródłem tego podziału jest kontekst opisu, co pokazano na diagramie Obiekt i jego historia. Obiekt niezmiennie trwa w czasie. Może on ulegać zmianom: ma cykl życia, ale co do zasady trwa, zmiany są (mogą być) skutkiem określonych zdarzeń, powiązanych z tym obiektem. Zdarzenia jednak nie muszą zmieniać przedmiotu, mogą go jedynie "dotyczyć". Obiekty (object) i zdarzenia (events) definiowane są przez ich cechy (properties).
To co łączy zdarzenia z obiektami to określone czas i miejsce zdarzenia. Obiekt, którego zdarzenie dotyczy, jest elementem jego opisu. Obiekt niezmiennie trwa w czasie, więc wiąże się z nim także pojęcie jego cyklu życia: jest to jego historia. Historia obiektu to zbiór powiązanych z nim zdarzeń (których dany obiekt był uczestnikiem). Zdarzenia i obiekty opisujemy z użyciem cech. Zdarzenie i obiekty muszą być unikalne (odróżniamy je od siebie), jednak wartości poszczególnych cech nie muszą już być unikalne, np. ta sama data wielu różnych zdarzeń, to samo miejsce wystąpienia różnych zdarzeń. Wartości (value) cech (properties) nie są ani zdarzeniem ani obiektem, choć mogą mieć złożoną strukturę (np. pełny adres pocztowy jest wartością cechy położenie, ale nie jest ani zdarzeniem ani obiektem). To dlatego nie są one typem tematu. Temat opisu to albo obiekt albo zdarzenie. Jeżeli przyjmiemy założenie, że kontekst określa znaczenie pojęć, opis zaś składa sie z pojęć, to w konsekwencji określony dokument, by jego treść była jednoznaczna, może mieć tylko jeden kontekst.
Z perspektywy przetwarzania danych nie ma znaczenia czy zdarzenie (event) jest z przeszłości czy przyszłości bo oba maja identyczne cechy (dane opisujące: atrybuty). Pojecie czasu ma znaczenie dla człowieka który interpretuje dane (patrz A-theory and B-theory, [Mountriver 2011]). Dlatego system informatyczny posortuje chronologicznie zdarzenia, ale określenie czy dane zdarzenie było czy będzie, wymaga skorelowania daty tego zdarzenia (jego cecha) z datą dnia gdy pytanie takie jest zadane. Innymi słowy pytanie o "zdarzenia wczorajsze" każdego dnia da inny wynik mimo, że dane o zdarzeniach nie ulegają zmianie.](https://it-consulting.pl//wp-content/uploads/2020/10/obiekt-i-jego-historia-w-sytuacji-przedstawionej.png)