Bardzo wiele problemów w toku wdrożeń IT rodzą wadliwie zaprojektowane struktury dokumentów. Dotyczy to w szczególności zarządzania dostępem do treści, a patrząc szerzej: do informacji. Ostatnie lata to między innymi problemy urzędów z udzielaniem dostępu do informacji publicznej, od dwóch lat dodatkowo problemy stwarza RODO. Źródłem problemów jest treść dokumentów, rozumiana jako pytanie: “Czy te informacje muszą być zawarte w tym dokumencie”. Najpierw opiszę mechanizm powstawania przyczyn problemów i sposób ich rozwiązania. W podsumowaniu wskażę jak i gdzie sobie z tym radzić.
Napisałem o orientacji na dokumenty w toku analiz:
Często jestem i ja pytany o to ??Jak wyjaśnić złożone rozwiązanie techniczne interesariuszom nietechnicznym?? Jak wielu mi podobnych odpowiadam: rozmawiaj dokumentami. Sponsor projektu, przyszli użytkownicy, postrzegają swoją pracę poprzez dokumenty: ich treść i układ. (Wymagania na formularze czyli diagramy struktur złożonych i XML)
Dzisiaj pójdziemy dalej, omówimy to gdzie i jak zachować tę informację. Posłużę się prostym przykładem przychodni weterynaryjnej. Artykuł będzie opisem metody podejścia do analizy zorientowanej na procesy i dokumenty.
Tekst ma dwie części: pierwsza jest opisem drogi jaka prowadzi nas do zdefiniowania tego jakie dokumenty, jaką mają (mieć) zawartość i strukturę. Praktycznie jest to opis analizy i projektowania. Druga – krótka – to przykładowa architektura logiki realizacji aplikacji, pokazująca miejsce dokumentowej bazy danych w architekturze i projekcie, czyli także projektowanie.
Celem tego wpisu jest pokazanie czym może być analiza oraz jej produkt jakim jest Techniczny Projekt Oprogramowania.
Nadal obserwuję to, że model relacyjny i “tworzenie bazowych modeli danych na etapie analizy wymagań” (kanoniczny model danych) trzymają się twardo mimo tego, że nie wiele wnoszą do projektu a narzucają (sugerują) kiepską architekturę aplikacji z jedną relacyjna bazą danych. Co ciekawe zaczynanie od bazy danych jest wręcz zaprzeczeniem zwinności (konieczność ukończenia projektu docelowej bazy danych przed rozpoczęciem kodowania czyli klasyka waterfall, w efekcie betonowanie stanu z dnia rozpoczęcia) mimo, że autorki artykułu piszą o sobie że są agile…)
Popatrzmy na to co proponują w tym 2017 roku.:
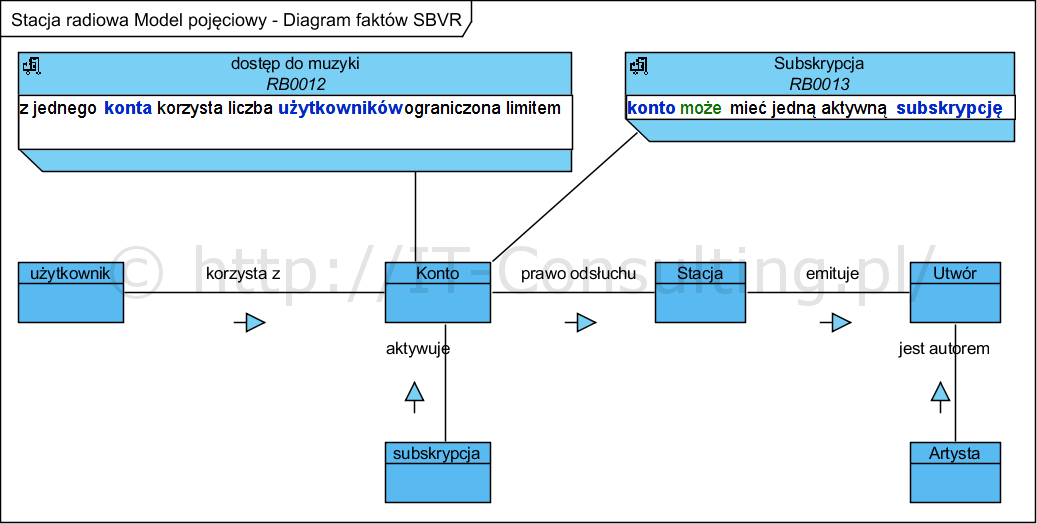
Jeśli w systemie istnieją określone reguły biznesowe, które określają maksymalne wartości relacji 0..n lub 1..n, można je uwzględnić w granicach kontekstu. Na przykład, PO dla SeiSounds może chcieć określić, że każde konto może być powiązane tylko z maksymalnie pięcioma użytkownikami lub słuchaczami, aby uniknąć sytuacji, w której znajomi kupują jedną płatną subskrypcję i dzielą się nią ze wszystkimi innymi. Proszę zobaczyć poniższy przykład:
[…]PODSUMOWANIE Diagramy danych biznesowych są jednym z tych modeli, które MUSZĄ BYĆ dla każdego produktu, który ma do czynienia z danymi. Samo ćwiczenie tworzenia modelu tworzy potężne, wspólne zrozumienie podstawowych konstrukcji danych, tak jak rozumieją je użytkownicy. BDD może również pomóc w zidentyfikowaniu dodatkowych, bardziej szczegółowych modeli, które mogą być potrzebne, a także w uzyskaniu pełnego zestawu historii użytkowników dotyczących interakcji użytkowników z danymi po wykonaniu czynności tworzenia, używania, edytowania, usuwania, przenoszenia i kopiowania. (Źródło: Deep Dive Models in Agile Series: Business Data Diagram)
Powyższy model:
deklaruje konkretną znaną “na teraz”, wartość limitu liczby użytkowników Konta,
pomiędzy autorem, utworem i stacją jest nic niemówiąca (każde z każdym bez żadnych ograniczeń) zależność,
pozostałe elementy nie wnoszą wartości dodanej (utwór jest cechą artysty czy może artysta jest cechą utworu…).
Zaryzykuję tezę, że powyższe w zasadzie nie pomaga developerowi w niczym. Czy wnosi coś do projektu? W moich oczach stanowi proste “zapisanie” tego co zeznali indagowani zamawiający (artykuł zawiera opis historyjek użytkownika i ich kojarzenia z tym modelem danych). Stwierdzenie zaś, że “…określone reguły biznesowe w systemie, które ustalają maksymalne wartości dla relacji 0..n lub 1..n…”, (np. maksimum pięcioro użytkowników może jednocześnie słuchać), to nie reguła biznesowa a kryterium decyzyjne (więcej o regułach biznesowych w literaturze).
Trzeba sobie tu jasno powiedzieć, że indukcyjne podejście do analizy (zbieranie i zapisywanie obserwacji w celu identyfikacji trendu lub powtórzeń) przypomina próby zrozumienia gry w szachy metodą wielokrotnej obserwacji rozgrywek. Im wierniejszy opis gry ma powstać, tym więcej obserwacji należy udokumentować, co nie zmienia faktu, że taki dokument nie mówi absolutnie nic o przyszłych rozgrywkach. Alternatywą jest dedukcyjne podejście, polegające na zrozumieniu i opracowaniu, możliwie najmniejszym nakładem pracy, reguł gry w szachy, czego udokumentowanie wymaga najwyżej dwóch stron papieru A4, taki dokument opisuje także w 100% wszystkie przyszłe rozgrywki…
Jak inaczej podejść do tego?
Na początek należy zrozumieć dziedzinę problemu i opisać ją słownikiem:
Powyższy model pojęciowy (diagram notacji SBVR, diagram klas notacji UML) to słownik pojęć a nie model danych. To diagram obrazujący pojęcia i kontekstowe związki między nimi (tym kontekstem są fakty z dziedziny analizowanego problemu). Nie są to ani dane ani reguły biznesowe.
Są to graficznie wyrażone zdania, testem tego modelu jest sprawdzenie czy są to zdania prawdziwe w danej dziedzinie, np. “artysta jest autorem utworu”.
Są to pojęcia 9nazwy), a nie “byty systemowe”. Poza takim diagramem, należy także stworzyć słownik pojęć biznesowych w postaci tabeli zawierającej precyzyjne, dziedzinowe definicje tych pojęć. Dla wygody i prezentacji ich treści naniosłem dwie reguły na diagram, są skojarzone z Kontem gdyż jego dotyczą. Co do zasady reguły biznesowe są kojarzone z elementami na innych diagramach poprzez słowa zdefiniowane.
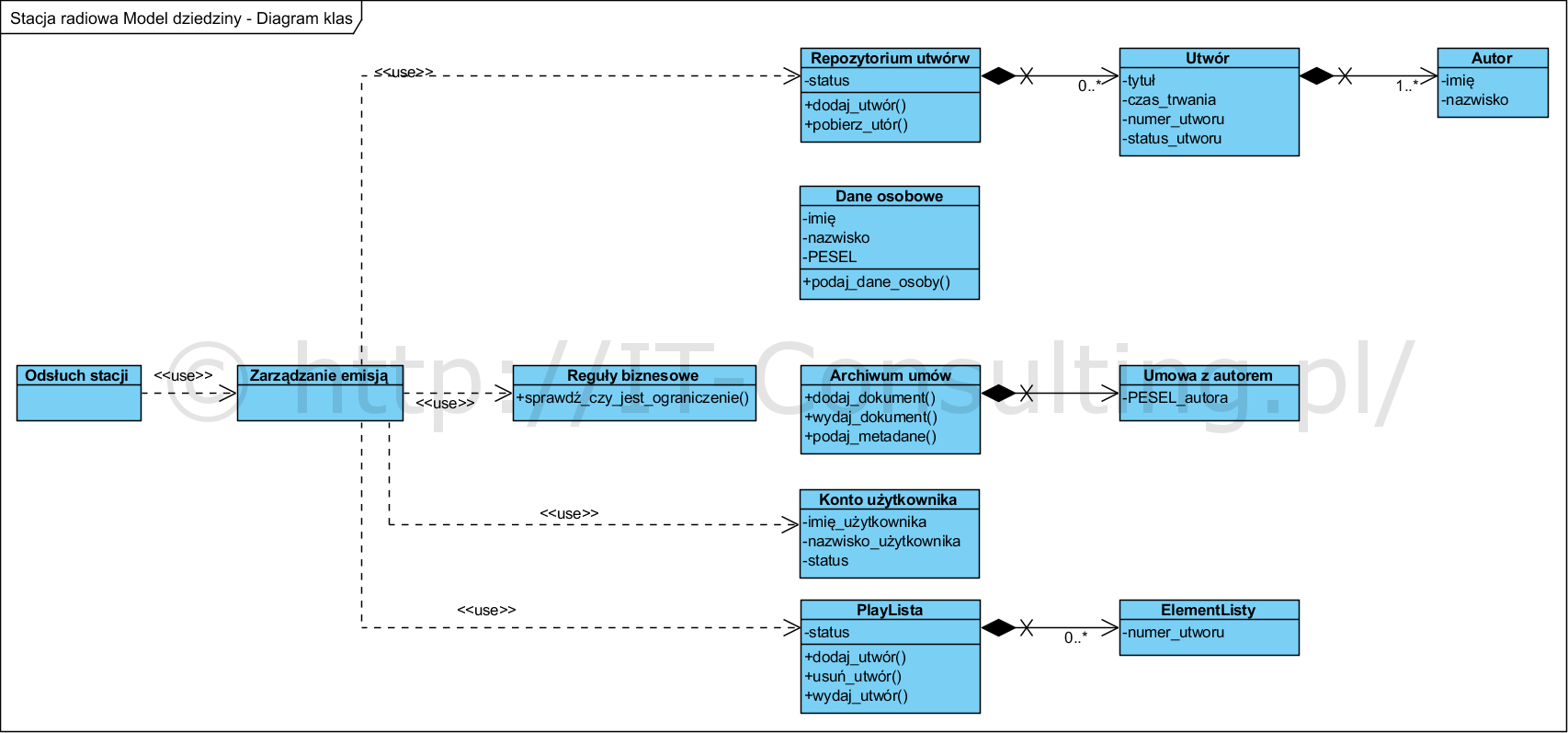
Cała analiza powinna się zaczynać od udokumentowania modeli procesów. Tu pominąłem te modele bo ich opisów jest na moim blogu wiele, a chcę się skupić na dziedzinie dla jakiej powstaje aplikacja. Analiza i zrozumienie problemu prowadzi do stworzenia modelu dziedziny aplikacji. Taki model powstaje na podstawie treści dokumentów wewnętrznych i zewnętrznych (tu np. Ustawa o prawach autorskich), pomagają co najwyżej bieżące wyjaśnienia. Do jego powstania nie są potrzebne żadne warsztaty ani całodzienne spotkania.
Celem modelowania dziedziny systemu (tu aplikacji) jest udokumentowanie wewnętrznej logiki aplikacji, czyli mechanizmu jej działania. Absolutnie nie jest to model danych. Powyższy model nie jest modelem “ukończonym”, wymaga na pewno dopracowania, jednak moim celem jest jedynie pokazanie idei jego tworzenia. Nazwy klas, atrybutów, operacji zawierają pojęcia zawarte w słowniku pojęć. Zapewnia to jednoznaczność i zrozumienie. Dodam, że dopiero ten model pokazuje bardzo ważną rzecz, to że autor jest cechą utworu a nie odwrotnie.
Tak więc:
uruchomienie i korzystanie z emisji kontrolowane jest przez Zarządzanie emisją, tu sprawdzane są i egzekwowane, reguły biznesowe,
komponent Zarządzanie emisją korzysta także z informacji zawartych w Koncie użytkownika i Playlisty, detale utworów pobiera z Repozytorium utworów.
Tu ważne jest podkreślenie, że reguła dotycząca ograniczenia liczby jednocześnie słuchających, jest oddzielona od Kont użytkowników i (nie pokazanych tu) Subskrypcji. Dzięki temu parametr ten jest łatwo modyfikowalny z poziomu aplikacji (parametryzowane kryterium decyzyjne) bez potrzeby jakichkolwiek ingerencji w “model danych”. Umieszczanie jakichkolwiek reguł w bazie danych (czyli na poziomie implementacji utrwalania) jest niestety ich “betonowaniem”.
Zmienność, nie tylko rynku ale i samych reguł w organizacjach, to stały element środowiska aplikacji. Dlatego dobrą praktyką jest, by utrwalanie danych (wszelkie bazy danych, pliki itp..) nie służyło do niczego poza utrwalaniem. Logika biznesowa powinna być w w 100% w aplikacji a nie podzielona pomiędzy aplikację i dane (żadna baza danych nie jest w stanie przechowywać innych reguł biznesowych niż bezpośrednie związki ilościowe). Na etapie implementacji, stosujemy zasadę hermetyzacji, czyli nie współdzielimy, na żadnym poziomie, danych pomiędzy repozytoriami i nie usuwamy redundancji. Dzięki temu nie odcinamy sobie drogi do zmian systemu takich jak np. zastąpienie klasy Dane osobowe interfejsem do zewnętrznego systemu, dysponującego takimi informacjami (klasa ta zostanie zmieniona, stanie się wtedy mostem do API zewnętrznego systemu co nie pociągnie za sobą jakichkolwiek zmian, bo interfejs tej klasy i jej nazwa pozostaną niezmienione, patrz zasada open-close principia oraz polimorfizm).
Poniżej kluczowe związki w UML i ilustracja związku pomiędzy modelem pojęciowym a modelem struktury (architektury, to model dziedziny):
Na zakończenie warto zauważyć, że zmienność środowiska biznesowego powoduje, że żadne decyzje o logice biznesowej nie są ostateczne, jednak są elementy niezmienne takie jak np. nasze dane osobowe. Tak więc to, co powszechnie nazywane jest “modelem danych” (business data diagram) w rozumieniu opisanym przez autorki artykułu, nie ma dzisiaj racji bytu. Ma sens zachowanie zamówienia i osobno faktury, ale to czy regułą jest jedno zamówienie do jednej faktury, podlega zmianom wynikającym i ze zmienności prawa i ze zmienności modeli biznesowych. Nie widzę żadnego powodu deklarowania już na początku projektu, tego by nie więcej niż 5 osób mogło korzystać z jednego konta i subskrypcji. W szczególności nie widzę powodu by taka zasada była zawarta w samym kodzie aplikacji.
Warto także mieć na uwadze to, że oprogramowanie może być tworzone z użyciem zewnętrznych komponentów dostępnych na rynku. Założenie więc na samym początku projektu, że dane są w jednolity sposób przechowywane i współdzielone w jednej centralnej i współdzielonej bazie danych, wraz z logiką ich użycia, jest tu nie tylko nieuzasadnione ale wręcz szkodliwe.
I na koniec gratka: dokładnie ta powstała, i nadal tak wygląda, znaczna większość obecnych na rynku systemów ERP, CRM itp….
oraz cytat z literatury
z 1994 roku:
(źr. Designing Objects Systems, Steve Cook, John Daniels, 1994 rok.)
Nie raz tu już pisałem, że analizy i projekty związane bezpośrednio z wymaganiami na oprogramowanie to “tylko” ok. 3/4 moich projektów. Jednak nawet, jeżeli projekt nie jest “nazwany” informatycznym, to zawsze jest “informacyjny” w rozumieniu zarządzania informacją (także zarządzanie wiedzą). Tym razem kilka słów na temat dokumentów. Stanowią one podstawową jednostkę informacji (i danych) w każdym systemie biznesowym. Są także źródłem danych dla hurtowni danych.
Wiele projektów związanych z dokumentami jest sprowadzanych do problemu:
“jakie mamy dokumenty i co z nimi robimy?”
Zaniedbuje się bardzo ważny element: odpowiedź na pytanie:
“czy nasze obecne dokumenty, ich ilość i treść, są właściwe?”
Otóż praktyka pokazuje, że dość często problemem są dokumenty opracowane “kiedyś tam”. Inicjuje się projekt z różnymi wymaganiami ale nikomu nie przychodzi do głowy by zastanowić się nad tym czy obecne dokumenty, w ich obecnej postaci, są dobrym pomysłem i powinny takie pozostać.
Czy dokumenty są niezmienialnym bytem? Nie, nie są.
Każda organizacja obraca skończoną liczbą dokumentów, są to różnego rodzaju formularze, w najogólniejszym przypadku dokumentem jest po prostu każda treść, także “zwykła proza” np. notatka. Warto jednak zwrócić uwagę na to, że nawet ona ma pewną strukturę: np. autora, adresata, temat, datę i treść. Dokumenty to określona konkretna treść utrwalona z określonego powodu (w przeciwnym wypadku dokument nie by powstał). Osiem lat temu opisywałem kwestie różnicy między dokumentem, wiedzą, informacją a danymi:
Czy baza danych to wiedza?[?] Model jawnie pokazuje, że bezpośredni związek z Bazą Danych mają Dane. Dalej już są wyłącznie niematerialne pojęcia czym więc jest Zarządzanie Wiedzą (milcząco zakładam, że zarządzać można czymś materialnym)? Jest to ?przechowywanie danych jednoznacznie zrozumiałych, opisujących określone i ograniczone liczbą fakty interpretowane jako pojmowalna przez adresata informacja?. (Źródło: Potrzeby informacyjne firmy ? Zarządzanie wiedzą | Jarosław Żeliński IT-Consulting)
Dzisiaj co nieco o tym, dlaczego od czasu do czasu warto się pochylić nad wzorami dokumentów i czy czasem nie zmienić nieco podejścia do nich.
Dokumenty w organizacji
Swego czasu u jednego z moich klientów “odkryłem” ciekawy dokument. Była to faktura z dodanym zestawem danych odpowiadającym dokumentom WZ oraz analogicznym zestawieniem dotyczącym opakowań zwrotnych. Ten super dokument był pomysłem z przed wielu lat osoby odpowiedzialnej za wydawanie i zarządzanie opakowaniami zwrotnymi w magazynie. Uzasadnienie brzmiało: na jednym dokumencie będą wszystkie informacje związane z konkretną sprzedażą i dostawą. Brzmi ładnie jednak: praktycznie każdy kto miał z tym dokumentem do czynienia, w toku obsługi zamówienia, dostawał nadmiarowe dane, nie raz niejawne (niektóre) ceny, szczegóły zawartości paczek, wartość towaru (po co ta wiedza kierowcom), ilości i salda (tak) opakowań zwrotnych (jak się okazało dokument nie raz pomagał w nadużyciach, niektórzy pracownicy zaś zamazywali czasami część danych przekazując dokument dalej, by ich nie ujawniać). Ale największym problemem było to, że ta osoba uczyniła z tego wzoru dokumentu wymaganie wobec oprogramowania ERP. Jak się nie trudno domyśleć, żaden rynkowy system nie ma takiego dokumentu standardowo, dostawca ERP uznał to wymaganie bez zastrzeżeń, co przyczyniło się do wielu modyfikacji oprogramowania także w innych miejscach, znacznego wzrostu budżetu (współdzielona baza danych propaguje zmiany praktycznie na całą aplikację). Nie będę tu opisywał dalszych losów tego wzoru dokumentu bo celem moim było jedynie pokazanie problemu na realnym przykładzie.
Każdy projekt, czy to wdrożenie nowych zasad zarządzania czy nowego oprogramowania, związany z zarządzaniem organizacją, to (powinien być) także co najmniej przegląd dokumentów i ich obiegu. Kluczowym elementem tego przeglądu powinna być analiza treści tych dokumentów, ich optymalność, nie tylko obiegu ale także treści i jej struktury. Owszem, wiele dokumentów ma narzuconą strukturę np. w odpowiedniej ustawie, jednak są to minimalne zawartości (np. faktura) nie ma zakazu uzupełnienia tej struktury i np. dodania do faktury numeru zamówienia, z którym jest związana.
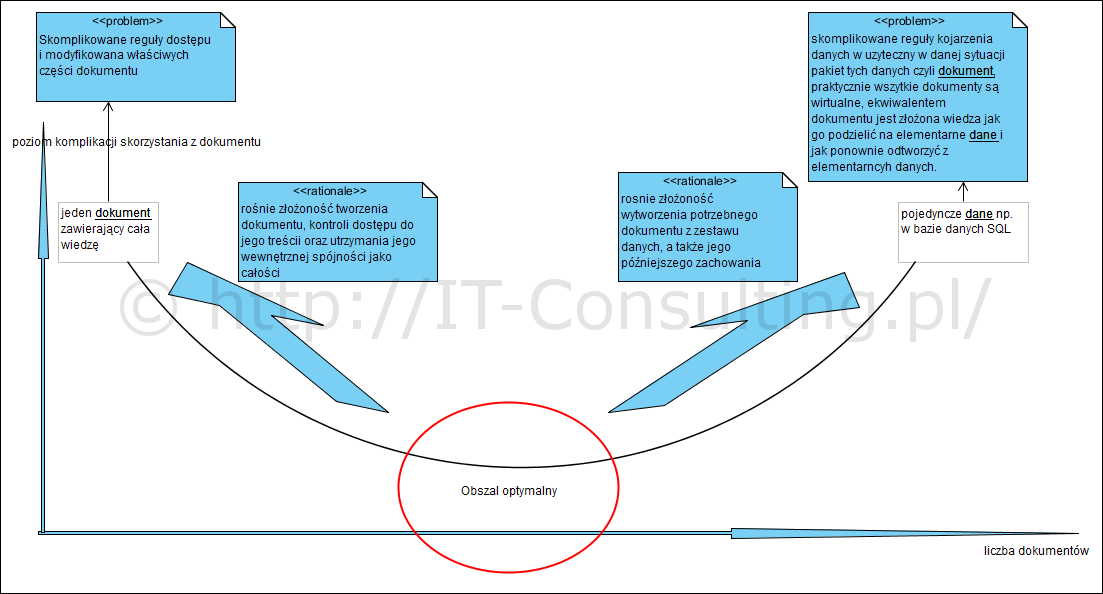
Ogólnie można określić pewne prawidłowości: jeżeli dokumenty są przeciążane treścią, czyli idziemy w kierunku małej ilości dokumentów zawierających dużo danych, rośnie złożoność reguł pracy z takim dokumentem. Jeżeli zaś idziemy w kierunku dokumentów “bardzo prostych”, rośnie ilość ich typów i rośnie liczba reguł kojarzących te dokumenty ze sobą w celu ich użycia. Ogólnie obrazuje to poniższy diagram:
Tak więc skrajnym rozwiązaniem będzie stworzenie jednego dokumentu, na którym będą wszystkie informacje np. związane z danym zamówieniem. Drugą skrajnością jest podzielenie informacji na odrębne małe niepodzielne już grupki, jak to ma miejsce w znormalizowanych relacyjnych bazach danych. Jeżeli megadokumenty to raczej bardzo rzadkie zjawisko, to przypadek drugi jest dość powszechny. To co nazywamy często dokumentem to tu tak na prawdę nieistniejący byt w relacyjnej bazie danych, generowany ad-hoc “w locie” z szeregu rozdrobnionych tablic danych. Innymi słowy nie są to “stałe struktury” a pewna określona złożona logika, tworząca z prostych danych pobieranych z tablic, konkretne zestawy informacji np. faktury (to dlatego często w “języku dostawcy” faktura to raport a nie dokument!). Ta złożona logika realizowana jest (wykonywana w pamięci komputera) za każdym razem gdy odwołamy się do takiego dokumentu.
Optymalna sytuacja to rodzaj kompromisu pomiędzy złożonością logiki tworzenia i korzystania z dokumentu a jego zawartością. Na powyższym diagramie jest to obszar stanowiący okolice minimum krzywej opisującej zależność pomiędzy liczbą dokumentów a złożonością operowania nimi. Nie ma prostej reguły na opracowywanie i optymalizacje treści i liczby dokumentów jednak są pewne sprawdzone dobre praktyki, a mianowicie jeden dokument, o określonej strukturze, powinien zawierać dane o określonym zdarzeniu w określonym kontekście [powstaje teraz publikacja na ten temat, wydaje się można to jednak zdefiniować, przyp autora 2019]. Dokumenty te, podobnie jak fakty które dokumentują, mogą mieć każdy własny i różny od innych cykl życia, dlatego często bywa bardzo szkodliwe “rozdzielanie” ich na pola bazy danych i pozbycie się redundancji.
Przykładem mogą być: zamówienie jako udokumentowanie faktu zawarcia umowy na dostawę, faktura jako udokumentowanie faktu sprzedaży (przeniesienia własności) oraz dokument WZ dokumentujący fakt wydania z magazynu określonych produktów. Bardzo często specyfikacja tego co wydano z magazynu nie jest tożsama z treścią faktury (sprzedano odkurzacz a wydano odkurzacz i zapasowe worki), na zamówieniu mógł być wyszczególniony odkurzacz, worki oraz wymagane końcówki (które są np. u producenta pakowane w standardzie więc nie ma ich ani na fakturze ani na WZ). Dlatego ma głęboki sens by te dokumenty były jednak “osobnymi dokumentami” a nie zachowywanymi w bazie danych danymi jako odrębne pola pozbawione redundancji, wymagające skomplikowanej logiki (polecenia SQL) by je (te “dokumenty”) pokazać na ekranie czy wydrukować.
To dość trywialny przykład, bo opisane dokumenty są wymagane przepisami jako dowody księgowe, jednak każda większa organizacja ma swoje wewnętrzne dokumenty, na których ilość i treść ma pełny wpływ. Po drugie nawet te dokumenty są często właśnie zapisywane w relacyjnych bazach danych jako rozproszone po małych tabelach dane, wymagające skomplikowanych operacji łączenia w jeden “dokument”, każdorazowo przy próbie jego użycia. Tu zachodzi bardzo duże ryzyko, że postać i treść takiego dokumentu ulegnie zmianie np. po reorganizacji bazy danych. Takich “dokumentów” nie da się (w tej postaci) podpisać elektronicznie, bo one po protu fizycznie na prawdę nie istnieją.
A jak inaczej? Nie ma żadnego problemu by dowolny dokument stanowił sobą jednolity byt np. zestaw danych w formacie XML, skojarzony ewentualnie ze swoją postacią gotową do druku albo np. plik PDF skojarzony z metadanymi opisującymi go (wybór jest na prawdę duży). Nie należy zapominać, że poza dokumentami, które są tworzone w organizacji operujemy dokumentami obcymi, otrzymanymi z zewnątrz i wypadało by mieć taki dokument w postaci takiej jaką przesłał nam ich twórca. Owszem pojawia się redundancja danych ale ona nie stanowi sobą nic złego. Ogromną korzyścią takiego podejścia jest rozwiązanie problemu polegającego na niemożności rozdzielenia “dokumentów” i logiki operowania nimi jeżeli są zapisane w postaci odrębnych pól w relacyjnej bazie danych. Np. staje się niemożliwe pozostawienie faktur i wyniesienie dokumentów magazynowych do odrębnego systemu (w tym zmiana ich struktury) co ma miejsce nie raz przy wdrażaniu systemów WMS (systemy logistyczno-magazynowe). Takie operacji prawie żaden duży zintegrowany ERP nie wytrzyma (usłyszymy raczej, że “my dostosujemy do Państwa potrzeb nas moduł magazynowy…).
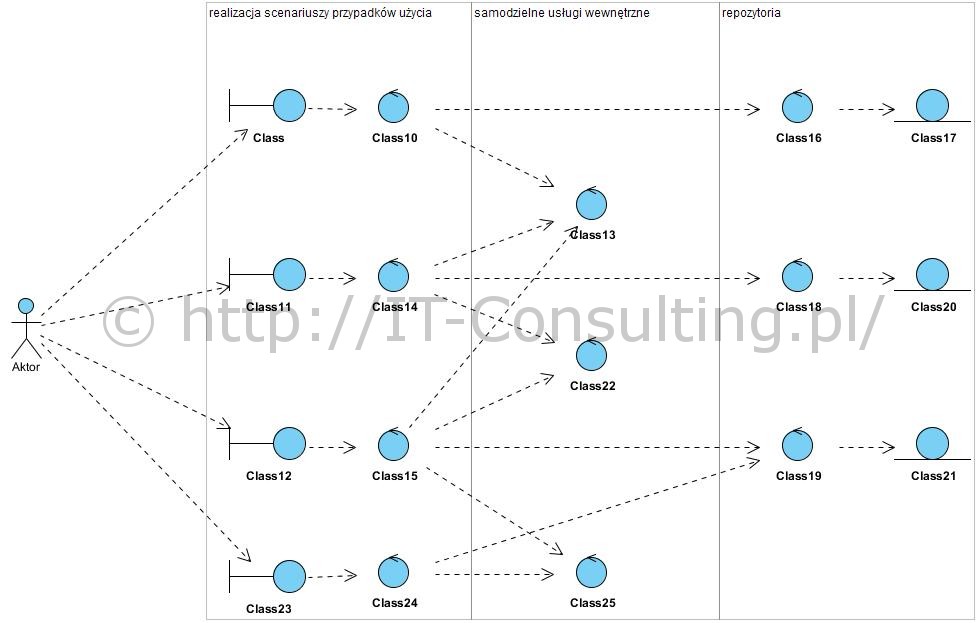
Podejście takie ma także inna ciekawą zaletę: jeżeli udokumentujemy osobno struktury dokumentów i logikę operowania nimi (także ich tworzenia), to otrzymamy obiektowy model organizacji: model pokazujący wzajemną współpracę obiektów biznesowych (dokumentów) odpowiedzialnych za przechowywanie informacji, obiektów odpowiedzialnych za rejestrowanie tych informacji, obiektów mających wiedzę jak operować tymi informacjami, obiektów udostępniających to wszystko zgodnie z określoną logiką. Poniżej obiektowy model na którym od prawej mamy: dokumenty z ich treścią oraz logikę ich tworzenia i udostępniania (repozytoria czyli kuwetki na dokumenty), logikę korzystania z informacji w repozytoriach, także ich wzajemnego kojarzenia (samodzielne usługi) oraz logikę dostępu do tego systemu (realizacja scenariuszy przypadków użycia). Jeżeli w toku analizy uznamy, że jakieś elementy tej logiki to zadania poddające się w 100% algorytmizacji, to poniższy model jest jednocześnie modelem logiki aplikacji i nazywamy go Modelem Dziedziny Systemu. Nie jest to absolutnie żadna baza danych, poniższe repozytoria niczego nie współdzielą (można je w dowolnym momencie zamieniać na inne bez konsekwencji dla reszty systemu).
Model ten powstał z użyciem bloków funkcjonalnych wzorca BCE (opisałem go tu: Wzorzec analityczny Boundary Control Entity). Dla wyjaśnienia: powyższy diagram to w pełni poprawny Model dziedziny wykonany z użyciem diagramu klas UML, klasy mają stereotypy boundary, control i entity (powyżej od lewej do prawej), stereotypy te są reprezentowane symbolami opisanymi (ikonami) w BCE. (Źródło: Krzywe i koszty? architektury | | Jarosław Żeliński IT-Consulting)
Podsumowanie
Prawie zawsze obserwuję, że podstawowym domyślnym założeniem wdrożeń systemów wspomagających zarządzanie, jest uznanie a priori niezmienności struktury i wzorów dokumentów.
Z doświadczenia mogę powiedzieć, że analiza i optymalizacja treści dokumentów wewnętrznych może przynieść bardzo duże korzyści przekładające się na duży wzrost wewnętrznej efektywności i jakości pracy, a w przypadku wdrożeń oprogramowania wspomagającego zarządzanie, pozwala nie raz całkowicie uniknąć bardzo kosztownych i ryzykownych kastomizacji. Zaryzykuje tezę, że kilka projektów w ten sposób wręcz uratowałem…
Przypominam, że systemy ERP inne o podobnej architekturze, nie przechowują dokumentów, bo dynamicznie generowane treści (raporty SQL, i podobne generowane “w locie” na API) to w świetle prawa nie są dokumenty, i słusznie bo nie istnieją w czasie.
Za trwały nośnik można uznać m.in. dokument papierowy, kartę pamięci, pendrive, wiadomość mailową lub załączony do niej plik, np. w formacie pdf. Samo hiperłącze przekierowujące na stronę internetową nie spełnia wymogów trwałego nośnika, jeżeli tego rodzaju strona internetowa nie spełnia cech trwałego nośnika. (https://uokik.gov.pl/zwrot-i-rekompensata-od-mpay-i-revolut-bank-uab)
Rola architektury danych znalazła także odzwierciedlenie w zarobkach architektów danych. Diagram 3 przedstawia średnie zarobki roczne architektów różnych specjalności w tysiącach USD (dla porównania dodano także inne specjalności z obszaru IT). Widać wyraźnie, że architekci danych są wśród najwyżej opłacanych specjalistów. (źr. Architekt danych ? zawód przyszłości?).
ja obserwuje coś “obok”, otóż dane są wtórne w stosunku do faktów, obecne systemy raczej odchodzą od “jednolitych współdzielonych baz danych”, i nie dlatego, że RDBMS są “niemodne”, a dlatego, że same dane pozbawione kontekstu, są mało wartościowe (do tego normalizacja modeli danych to proces stratny), w moich oczach ma wartość np. faktura jako zapis faktu do jakiej transakcji doszło, zaś rozdzielenie danych z faktury na kilka tabel, czyni każdą z nich z osobna mało wartościową albo i bezwartościową… To, że architektura danych ma dziś najniższy słupek nie koniecznie znaczy, że ktoś to będzie nadrabiał (słynne dywagacje o tym, czy chodzący boso mieszkańcy Afryki wróżą mega rynek na obuwie), warto pamiętać o tym, że integracja pomiędzy systemami coraz częściej odbywa się na poziomie logiki biznesowej, poprzez wymianę obiektów opisujących zdarzenia i byty rzeczywiste, a nie poprzez współdzielenie (baz) danych, czego się zresztą nie da robić w sieciach rozproszonych takich jak chmury… Osobiście wróżę karierę analitykom, potrafiącym całościowo (holistycznie ;)) patrzeć na organizacje, rośnie złożoność organizacji, co w toku analiz i modelowania, zmusza do abstrahowania od pewnych szczegółów, tu wraca do łask analiza systemowa … (nie mylić z analiza systemów IT). Pamiętajmy, że:
Cook, S., & Daniels, J. (1994). Designing object systems: object-oriented modelling with Syntropy. New York: Prentice Hall.