Od czasu do czasu jestem pytany o to, kiedy używać diagramu aktywności UML. Od 2015 roku specyfikacja UML wskazuje, że diagramy te są narzędziem modelowania metod czyli logiki kodu (dla Platform Independent Model): aktywności (activities) to nazwy metod, zadania/kroki (actions) to elementy kodu (przykłady w dalszej części).
Gdy powstawał UML, diagramy aktywności były używane także do modelowanie procesów biznesowych. W roku 2004 opublikowano specyfikację notacji BPMN, która w zasadzie do roku 2015 “przejęła” po UML funkcję narzędzia modelowania procesów biznesowych. W 2015 roku formalnie opublikowano specyfikację UML 2.5, gdzie generalnie zrezygnowano z używania UML do modeli CIM. Obecnie Mamy ustabilizowaną sytuację w literaturze przedmiotu: BPMN wykorzystujemy w modelach CIM (modele biznesowe), UML w modelach PIM i PSM jako modele oprogramowania (a modele systemów: SysML, profil UML).
Na przełomie lat 80/90-tych rozpoczęto prace nad standaryzację notacji modelowania obiektowego, w 1994 opublikowano UML 0.9, w 2001 roku pojawiają się pierwsze publikacje o pracach nad notacją BPMN, jednocześnie pojawia się Agile Manifesto, od 2004 roku ma miejsce spadek zainteresowania dokumentowaniem projektów programistycznych, w 2004 rok publikowano specyfkację BPMN 1.0, od tego roku ma miejsce wzrost zainteresowania modelowaniem procesów biznesowych, powoli stabilizuje się obszar zastosowania notacji UML. W 2015 roku opublikowano UML 2.5, stosowanie analizy (CIM) i i projektowania (PIM), jako etapu poprzedzającego implementacje, stało się standardem (źr. wykresu: Google Ngram).
Tak więc obecnie:
Nie używamy diagramów aktywności do modelowania procesów biznesowych. Do tego służy notacja BPMN!
Diagram aktywności [zotpressInText item=”{5085975:DCYU6XZJ}”] może być modelem kodu na wysokim lub niskim poziomie abstrakcji, operujemy wtedy odpowiednio aktywnościami (activity) lub działaniami (actions). Te ostatnie to w zasadzie reprezentacja poleceń programu.
Nie ma czegoś takiego jak “proces systemowy”, oprogramowanie realizuje “procedury”.
Projektując oprogramowanie zgodnie ze SPEM [zotpressInText item=”{5085975:IFJKR4D2}”], powstaje Platform Independent Model. W praktyce już na tym etapie programujemy, bo tworzymy logikę i obraz przyszłego kodu. Taka forma dokumentowania pozwala także lepiej chronic wartości intelektualne zamawiającego.
W 2015 roku pisałem o komponentowej architekturze w kontekście dużych aplikacji biznesowych:
Idąc w stronę komponentów i dużych złożonych systemów warto skorzystać z podejścia polegającego na tworzeniu (kupowaniu) tak zwanych mikroserwisów, czyli wąsko specjalizowanych dziedzinowych aplikacji (wręcz pojedynczych grup przypadków użycia). Paradoksalnie to bardzo ułatwia projektowanie, implementację a przede wszystkim obniża koszty utrzymania całego systemu. Brak złożonych połączeń między komponentami (współdzielona baza danych, złożone interfejsy) pozwala na to, by cykle ich życia były także niezależne (wprowadzane zmiany także). (Granice kontekstu i mikroserwisy )
Dwa lata później w tekście będącym kontynuacją:
Takie podejście pozwala tworzyć szybciej przy minimalnym ryzyku pojawienia się potrzeby re-faktoringu całości a także czyni aplikację łatwą do tworzenia w zespole i późniejszej rozbudowy ?(Gage, 2018)?. Rosnąca popularność tej architektury, tylnymi drzwiami powoli ruguje z rynku monolity ERP, które (niektóre) podlegają re-faktoringowi (ich producenci nie chwalą sie tym bo to powolny i bardzo kosztowny proces). Te systemy, które nadal są oparte na fundamencie jednej bazy danych z integracją bazująca na współdzieleniu danych, powoli przegrywają kosztami. (Mikroserwisy c.d.?)
Dzisiaj opiszę jak na etapie analizy i projektowania opracować model PIM (Platform Independent Model) [zotpressInText item=”{5085975:84CYAT4F},{5085975:TBT7B5D2}”], w taki sposób by stanowił projekt techniczny aplikacji webowej dla developera.
Streszczenie: W pracy przedstawiono metodę projektowania architektury oprogramowania od ogółu do szczegółu z pomocą metamodeli definiowanych jako profili UML. Pokazano zaletę jaką jest możliwość szybkiego rozpoczęcia prac projektowych i testowania efektów mimo braku detalicznej wiedzy o danych. Metoda zakłada, że dane są zorganizowane z nazwane dokumenty o określonej strukturze. W trakcie prac analitycznych i projektowych wystarczającą wiedzą jest to jakie dokumenty są (będą) przetwarzane, zrozumienie ich celu i opis zawartości. Detaliczne szablony dokumentów (pola i ich zawartość) mogą pozostawać nieznane prawie do końca analizy i projektowania, wymagane są dopiero na etapie implementacji.
1. Wstęp
Wśród architektonicznych wzorców projektowych dominują wzorce opisujące elementy techniczne oprogramowania (Larman 2004) oraz wzorce opisujące ogólnie tworzenie dziedzinowych komponentów, tu najbardziej znany to wzorzec DDD (Evans 2003). Znane jest także podejście oparte na metodzie określanej jako “projektowanie zorientowane na odpowiedzialność klas” (Wirfs-Brock 2003).
Wzorzec DDD to wzorzec uniwersalny (dziedzina nie ma tu znaczenia), oparty na technicznych odpowiedzialnościach komponentów. Wirfs-Brock zaś opisuje podejście do projektowania architektury ale nie wskazuje konkretnych wzorców ani metamodeli, skupia sie na metodzie analizy i projektowania.
Artykuł ten to propozycja poszerzenia powyższych metod o podejście uwzględniające dziedzinę problemu oraz aktualne trendy w projektowaniu architektury dużych systemów (jednym z ciekawszych jest automatyzacja (Sobczak 2019). Celem jest dodanie warstwy abstrakcyjnej na jak najwcześniejszym etapie projektowania, by odsunąć w czasie prace ze szczegółami takimi jak atrybuty i wewnętrzne (prywatne) operacje komponentów. Innymi słowy celem jest poprzedzanie projektowania architektury oprogramowania studiami związanymi z dziedziną problemu, w celu opracowania profilu dla wybranej technologii lub projektu oraz słownictwa dla nazw elementów modeli, opisującego jednoznacznie role nazywanych komponentów.
Jest to idea znana z innych dziedzin np. zawodnicy drużyny piłki nożnej mają określone role, są klasyfikowani jako np. zawodnik obrony lub ataku, co informuje nas dość precyzyjnie o możliwych zachowaniach danego zawodnika a nie wymaga mimo to znajomości detali jego umiejętności (operacji), możemy długo nie wiedzieć kto konkretnie będzie grał na tej pozycji.
Do sporządzania schematów blokowych wykorzystano notację UML oraz SBVR (źr. omg.org).
2. Co zbadano?
Przedmiotem badań były projekty analityczne dokumentowane z użyciem notacji UML klasyfikowane przez autorów tych dokumentów jako obiektowe (o obiektowej architekturze).
3. Wyniki
Opracowano rozszerzenie wzorca BCE i opisano metodę jego rozszerzania. Zbudowanie rozszerzonego metamodelu wzorca BCE wymaga spójnego systemu pojęć.
3.1. Pojęcia agenta i robota
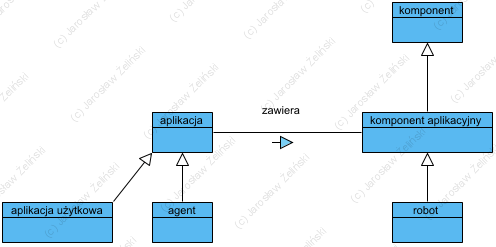
Diagram: Pojęcia agenta i robota
Opracowanie spójnego metamodelu wymagało włączenia do niego pojęć, które już są używane w inżynierii oprogramowania: agent i robot.
W słowniku języka polskiego aplikacja jest definiowana jako komputerowy program użytkowy zaś komponent jako część składowa czegoś. Kolejne pojęcia to robot jako urządzenie zastępujące człowieka przy wykonywaniu niektórych czynności oraz agent jako przedstawiciel jakiejś firmy. Pojęcia te funkcjonują już zarówno w branży zarządzania jak i w inżynierii oprogramowania, jednak nadal nie maja ścisłych definicji. Z uwagi na potrzebę ścisłego zdefiniowania tych pojęć w tej pracy, uwzględniając obecne już publikacje z tego zakresu, przyjęto tu model przedstawiony na diagramie Pojęcia agenta i robota:
komponent aplikacyjny jest typem komponentu,
aplikacja może być zbudowana z (zawiera) komponentów aplikacyjnych,
agent jest samodzielnym typem aplikacji,
aplikacja użytkowa jest oprogramowaniem dla użytkownika,
robot jest typem komponentu aplikacyjnego
Tak określone znaczenia tych pojęć są zgodne z przyjętymi w literaturze znaczeniami: agent to samodzielny program (aplikacja), robot jest automatem (postrzeganym jako “mniej inteligentny” od agenta, a więc niesamodzielnym). Takie definicje wzajemnie się wykluczają więc spełniają wymagania dla definicji w przestrzeni pojęciowej (namespace), nie kolidują także z przyjętymi w literaturze przedmiotu.
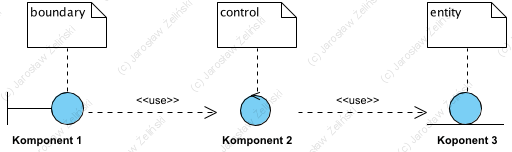
3.2. Wzorzec architektoniczny BCE
Wzorzec architektoniczny BCE. Ikony na diagramie Wzorzec architektoniczny BCE to graficzne reprezentacje stereotypów, klasy notacji UML.
Wzorzec BCE (Boundary, Control, Entity) w swojej pierwotnej wersji (Rosenberg 2005) zakłada, że komponenty aplikacyjne mają (realizują) jedną z trzech odpowiedzialności:
Boundary to interfejs komponentu,
Control to logika biznesowa,
Entity to utrwalanie.
Wzorzec ten był często niesłusznie interpretowany jako trójwarstwowe podejście do aplikacji (odpowiednio: interfejs, logika, dane) zgodnie z podejściem “aplikacja to funkcje i dane”. Później rozszerzono zastosowanie wraz ze wzorcem MVC (Rosenberg 2007). Wzorzec ten jednak jest bardzo ogólny i nie pozwala na precyzyjniejsze modelowanie ról. Z tego powodu bardzo szybko projektanci przechodzili do modelowania detali takich jak operacje i atrybuty klas i do implementacji, co w dużych projektach często prowadzi do szybkiego “zalania” projektu szczegółami.
There is some similarity between ECB and model–view–controller (MVC): entities belong to the model, and views belongs to boundaries. However the role of the ECB-control is very different from MVC-controller, since it encapsulates also use-case business logic whereas the MVC controller processes user input which would be of the responsibility of the boundary in ECB. The ECB control increases separation of concerns in the architecture by encapsulating business logic that is not directly related to an entity. https://en.wikipedia.org/wiki/Entity%E2%80%93control%E2%80%93boundary
Zadaniem było opracowanie metody i rozbudowy wzorca BCE w sposób nie kolidujący z jego podstawową ogólną formą (dla zachowania kompatybilności z historycznymi przypadkami jego użycia), dający możliwość projektowania zorientowanego na odpowiedzialność komponentów. Narzędziem jest tworzenie profili UML oraz budowanie modeli pojęciowych.
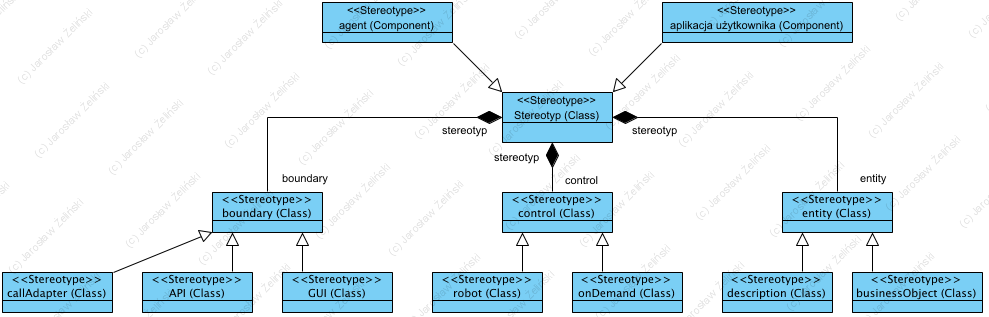
3.3. Profil UML dla rozszerzonego wzorca BCE
Diagram: Profil UML dla rozszerzonego wzorca BCE
Podstawowy zestaw stereotypów (stereotyp to dodatkowa klasyfikacja określonych elementów w notacji UML) to: boundary, control, entity. Rozszerzenie przestrzeni pojęciowej pozwala uzyskać profil zobrazowany na diagramie Profil UML dla rozszerzonego wzorca BCE.
Centralnym elementem jest pojęcie Stereotyp, jako dodatkowy klasyfikator dla nazwanych elementów Class (patrz OMG.org/MOF oraz OMG.org/UML). Dla komponentów (<<component>>) wprowadzono dwa stereotypy (dwie klasy komponentów): agentoraz aplikacja użytkownika. Celem jest wskazanie, że aplikacja może zostać zaprojektowana jako oprogramowanie dla jego użytkownika (będącego człowiekiem) lub oprogramowanie autonomiczne (reaguje na szerokopojęte otoczenie), działające samodzielnie. Oba te typy aplikacji mogę być projektowane z użyciem wzorca MVC więc komponent logiki dziedzinowej jest w oby typach aplikacji modelowany w ten sam sposób.
Trzyelementowy wzorzec BCE został poszerzony w ten sposób, że każdy z trzech jego elementów zyskał specjalizacje:
boundary: callAdapter, API oraz GUI,
control: robot oraz onDemand,
entity: description oraz businessObject.
Komponent boundary to interfejs pomiędzy aplikacją a jej otoczeniem. Usługi są udostępniane aktorom, zależnie od typu aktora, interfejsem GUI lub API 9interfejs oferowany). Jeżeli jest to przypadek interfejsu wymaganego, “wyjście na świat” deklarujemy jako callAdapter (nie dopuszczamy by jakiekolwiek komponent z wnętrza aplikacji wywoływał bezpośrednio usługi z poza aplikacji).
Komponent control realizuje usługi dziedzinowe na żądanie jako onDemand, albo działa samoczynnie jako “demon” robot. W literaturze pojęcie demon jest często stosowane jako nazwa automatu uruchamiającego polecenia wg. harmonogramu, dlatego celowo użyto pojęcia robot, na nazwę komponentu zachowującego pełną autonomię w tym jakie funkcje i jak realizuje. Komponent entity odpowiada za utrwalane dane. Dla rozróżnienia description odpowiada za przechowywanie wszelkich opisów konfiguracji, z reguły jest singletonem (singleton to klasa mająca jedną instancją). Te oznaczone businessObject reprezentują wszelkie strukturyzowane dane takie jak formularze, dokumenty, multimedia itp. Warto tu nadmienić, że obiekty typu entity nie reprezentują interfejsu do bazy danych wg. wzorca active records lub active table (Larman 2004). Dokument może tu być rozumiany jako ciąg znaków XMl przechowywany jako wartość jednego atrybuty klasy.
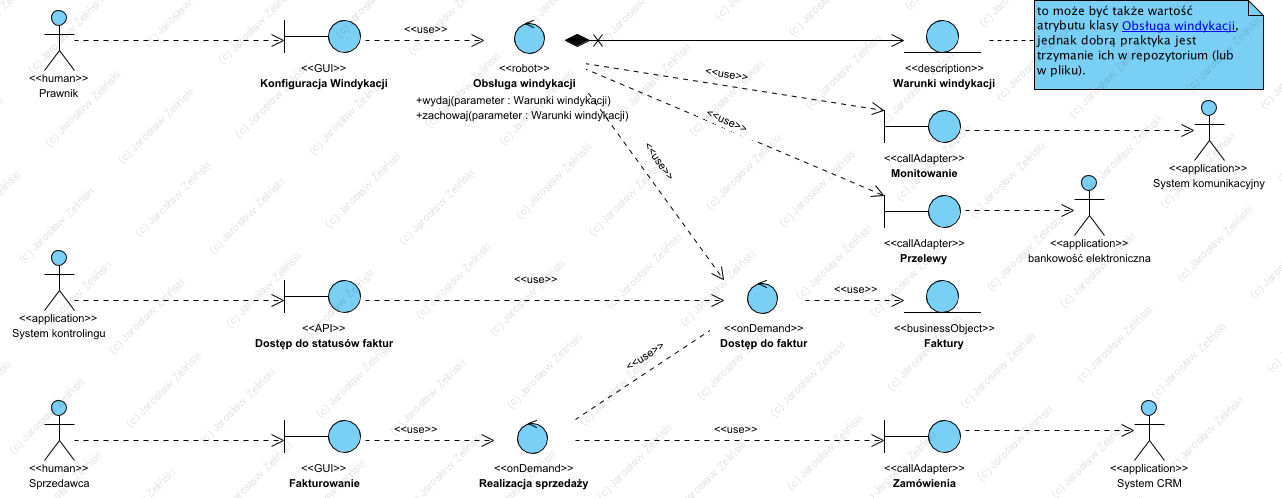
3.4. Przykład użycia rozszerzonego wzorca BCE
Diagram: Przykład użycia rozszerzonego wzorca BCE
Na diagramie Przykład użycia rozszerzonego wzorca BCE pokazano architekturę prostej aplikacji wspomagającej sprzedaż. Jest to model jej dziedziny.
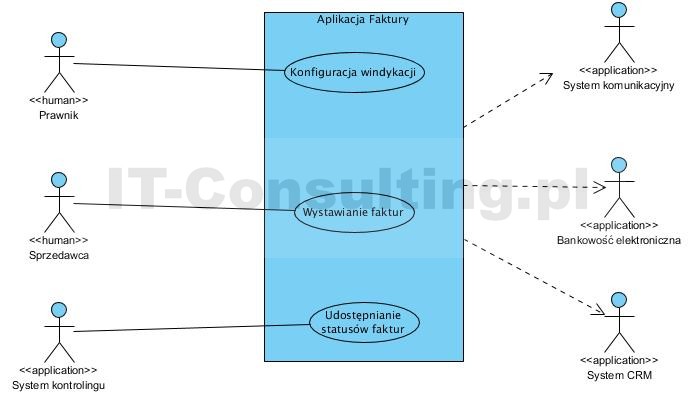
Aplikacja jest oprogramowaniem typu aplikacja użytkownika gdyż powstała by wspomagać prace użytkownika jakim jest Sprzedawca. Użytkownik Prawnik jest tu wyłącznie osobą parametryzującą (np. okresowo) zachowanie robota Obsługa windykacji. Celem aplikacji jest wystawianie faktur oraz bieżące prowadzenie tak zwanej miękkiej windykacji.
Standardową usługą tej aplikacji jest wystawianie faktur na postawie zamówień pobieranych z aplikacji System CRM.
System kontrolingu ma dostęp do faktur przez interfejs Dostęp do statusów faktur, pobiera dane o fakturach, dla których miękka windykacja była nieskuteczna.
Z uwagi na żmudną pracę związaną z miękką windykacją (załóżmy, że wcześniej robiło to call center), zautomatyzowaną ją dodając do aplikacji komponent Obsługa windykacji pracujący jako robot. Jest to komponent zawierający kompletną procedurą, która cyklicznie realizuje scenariusz: sprawdź status faktury, sprawdź czy wpłynęła dla niej płatność, zależnie od tego oznacz ją jako zapłaconą lub wyślij monit, stosownie do tego, które jest to wezwanie do zapłaty.
Na tym etapie, opracowanie architektury zorientowane na odpowiedzialność klas, nie jest potrzebne wiedza o danych, zupełnie wystarczy wiedza o rolach poszczególnych komponentów. Kolejnym krokiem było by tu ustalenie wszystkich potrzebnych statusów i ich nośników, a na końcu dopiero ustalenia wymaga struktura faktury, monitu i dowodu wpłaty.
Rozszerzony wzorzec BCE, jako metamodel i zarazem wzorzec architektoniczny, pozwala od razu zbudować szkielet tej aplikacji, stanowi wspólny język. Można przyjąć założenie, że zrozumienie pojęć jakimi nazwano role poszczególnych komponentów (stereotypy) pozwala zrozumieć zobrazowany mechanizm działania (formalnie powinny powstać także diagramy sekwencji, które pomięto by nie zwiększać objętości tego tekstu).
Aplikacja Faktury Usługi i wymagania
Opisana aplikacja z zewnątrz jest dla użytkownika relatywnie prostym programem użytkowym. Ma tylko jednego użytkownika (Sprzedawca), Użytkownikiem jest także Prawnik, który sporadycznie ustawia parametry pracy komponentu oznaczonego jako robot.
Na diagramie Aplikacja Faktury Usługi i wymagania zobrazowano aplikację Aplikacja Faktury z użyciem diagramu przypadków użycia notacji UML. Należy tu zwrócić uwagę, że diagram ten służy wyłącznie do dokumentowania celu tworzenia aplikacji. Diagram ten nie służy do opisu szczegółów jej funkcjonowania. Dlatego ten diagram w notacji UML bywa nazywany kontraktem lub kontekstem projektu. A typowym procesie analizy i projektowania ten diagram powstaje jako pierwszy.
4. Dyskusja
W toku przeglądu dostępnych autorowi dokumentacji projektowych, stwierdzono, że powszechna praktyką jest rozpoczynanie analiz i projektowania od tworzeniu modelu danych (diagramu ERD) lub szczegółowych diagramów klas bazujących na wzorcu active records lub active table (klasa i jej atrybuty reprezentują wiersze tabel baz danych, zaś związki między klasami relacje między tymi tablicami). Przykładem takiego podejścia jest próba stworzenia wzorców bazujących na detalicznych danych w dokumentach biznesowych (Arlow Neustadt 2004).
Autor proponuje całkowicie inne podejście, oparte na doświadczeniach z wzorcami BCE i DDD: budowanie dziedzinowych metamodeli w postaci profili abstrahujących całkowicie od detalicznej wiedzy o dokumentach (businessObject) a skupiających się na mechanizmie działania, tu jedynymi wymaganymi atrybutami są te, które obsługują logikę biznesową, są to metadane i statusy (nie pokazane w tym dokumencie). Trwają prace nad testowaniem tej metody. Spodziewane są małe zmiany definicji poszczególnych elementów.
5. Literatura
Arlow Neustadt 2004
Enterprise Patterns and MDA: Building Better Software with Archetype Patterns and UML, Jim Arlow; Ila Neustadt, ISBN-13: 9780321112309, 2004
Dzieszko i inni 2013
ROCZNIKI GEOMATYKI 2013 m TOM XI m ZESZYT 4(61), MODELOWANIE AGENTOWE NOWOCZESNA KONCEPCJA MODELOWANIA W GIS, Piotr Dzieszko, Katarzyna Bartkowiak, Katarzyna Gie?da-Pinas, Uniwersytet im. Adama Mickiewicza w Poznaniu, Wydzia? Nauk Geograficznych i Geologicznych, Instytut Geoekologii i Geoinformacji, Zakład Geoekologii
Evans 2003
Domain Driven Design Tackling Complexity in the Heart of Software by Evans, Eric. Published by Addison Wesley,2003,
Larman 2004
Applying UML and Patterns: An Introduction to Object-Oriented Analysis and Design and Iterative Development, Craig Larman, Prentice Hall, October 30, 2004, ISBN-10: 0131489062
Rosenberg 2005
Rosenberg, Don, Collins-Cope, Mark, Stephens, Matt, Agile Development with ICONIX Process, Apress 2005, ISBN 978-1-59059-464-3
Rosenberg 2007
Use Case Driven Object Modeling with UMLTheory and Practice, Theory and Practice, Rosenberg, Don, Stephens, Matt, Apress 2007
Streszczenie: Wiele publikacji, w tym podręczniki akademickie, zawiera niespójności w opisach zastosowań metod i wzorców architektonicznych, kryjących się pod skrótami MOF, MDA, PIM, MVC, BCE. Skuteczna analiza oraz następujące po niej projektowanie oprogramowania, szczególnie gdy są to projekty realizowane w dużych zespołach, wymaga standaryzacji procesu wytwórczego i stosowanych wzorców i frameworków. W pracy tej podjęto próbę uporządkowania systemu pojęć opisujących ten proces , stosowanych do opisu wzorców architektonicznych. Przeprowadzono analizę kluczowych pojęć MOF i MDA, wzorców MVC i BCE, stworzono spójny opis łączący je w jeden system.
1. Wprowadzenie
Celem badań było zweryfikowanie obecnego stanu metod projektowania i opracowanie spójnego systemu pojęć i wzorców projektowych w obszarze projektowania logiki oprogramowania, jako jej abstrakcyjnego modelu. Wiele publikacji na temat analiz i projektowania, w obszarze inżynierii oprogramowania, przywołuje nazwy wzorców projektowych MVC i BCE oraz model PIM (patrz OMG MDA, OMG MOF 2016). Z uwagi na, nie raz, nie małe rozbieżności w interpretacji tych metod i wzorców, autor podjął próbę uporządkowania ich wzajemnych zależności.
2. Metody
Wykorzystano systemy notacyjne Object Management Group (OMG.org). Specyfikacja MOF opisuje trzy poziomy abstrakcji: M1, M2, M3 oraz poziom M0 czyli realne rzeczy (patrz struktura poziomów abstrakcji, OMG MOF 2016). M0 to realny system, poziom M1 to abstrakcja obiektów tego systemu (jego model) . Poziom M2 to związki pomiędzy klasami tych obiektów (nazwy ich zbiorów) czyli metamodel systemu. Poziom M3 to meta-metamodel poziom opisujący metodę modelowania z użyciem nazwanych elementów o określonej semantyce i syntaktyce.
Proces analizy i projektowania został oparty na specyfikacji MDA (OMG MDA). Proces ten ma trzy fazy rozumiane jako tworzenie kolejnych modeli: CIM, PIM, PSM oraz fazę tworzenie kodu. Model CIM jest dokumentowany z użyciem notacji BPMN (OMG BPMN 2013) i SBVR (OMG SBVR 2017). Są to odpowiednio: modele procesów biznesowych oraz modele pojęciowe i reguły biznesowe. Modele PIM i PSM dokumentowane są z użyciem notacji UML (OMG UML 2017). Pomiędzy modelem CIM a PIM ma miejsce ustalenie listy usług aplikacyjnych (reakcje systemu), których mechanizm realizacji opisuje model PIM. Standardowym wzorcem używanym do modelowania architektury aplikacji jest wzorzec MVC. Komponent Model tego wzorca jest modelowany z użyciem wzorcza architektonicznego BCE.
[…]
Spis treści 1. Wprowadzenie 1 2. Metody 2 2.1. Semiotyka a UML 2 2.2. Specyfikacja MOF Poziomy abstrakcji 3 2.3. Specyfikacja MDA i model PIM 4 2.4. Wzorzec architektoniczny MVC 5 2.5. Wzorzec architektoniczny BCE 5 3. Rezultaty 6 3.1. Założenie uproszczające 6 3.2. Zintegrowany model struktury procesu projektowania aplikacji 7 4. Dyskusja 8 5. Dalsze prace 8 6. Bibliografia 9 7. Kluczowe pojęcia metodyczne 11
Cała publikacja …
Synthesis of MOF, MDA, PIM, MVC, and BCE Notations and Patterns Jaroslaw Zelinski (Independent Researcher, Poland)
Tematem numer jeden, niemalże w każdym moim projekcie, jest model biznesowy i tajemnica przedsiębiorstwa. Z perspektywy lat muszę powiedzieć, że to fobia wielu (jak nie większości) przedsiębiorców i nie tylko przedsiębiorców. Nie dlatego, że chcą coś chronić, ale dlatego co i jak chronią. Nie raz już pisałem, że firmy nie raz, najpierw podpisują z dostawcami rozwiązań i konsultantami umowy o poufności, a potem wyzbywają praw do swojego know-how na ich rzecz:
W branży inżynierii oprogramowania dość powszechna jest sytuacja, gdy programista jest także projektantem, innymi słowy programista ma pełnię praw autorskich do kodu jaki tworzy a jego klient żadnych mimo, że jest inwestorem!1
Dzisiaj drugi problem czyli bezpieczeństwo informacji a nie raz i całej firmy.
Na początek coś z zakres teorii informacji:
Zasada Kerckhoffs’a to jedna z podstawowych reguł współczesnej kryptografii. Została sformułowana pod koniec XIX wieku przez holenderskiego kryptologa Augusta Kerckhoffs’a (ur. 19 stycznia 1835, zm. 9 sierpnia 1903). Zasada ta mówi, że system kryptograficzny powinien być bezpieczny nawet wtedy, gdy są znane wszystkie szczegóły jego działania oprócz sekretnego klucza. […]
System powinien być, jeśli nie teoretycznie, to w praktyce nie do złamania.
Projekt systemu nie powinien wymagać jego tajności, a ewentualne jego ujawnienie nie powinno przysparzać kłopotów korespondentom.
Klucz powinien być możliwy do zapamiętania bez notowania i łatwy do zmienienia.
Kryptogramy powinny być możliwe do przesłania drogą telegraficzną.
Aparatura i dokumenty powinny być możliwe do przeniesienia i obsłużenia przez jedną osobę.
System powinien być prosty ? nie wymagający znajomości wielu reguł ani nie obciążający zbytnio umysłu.
Właśnie druga z tych reguł nosi obecnie nazwę zasady Kerckhoffs’a.
[…]Ideę zasady Kerckhoffs’a wyraża również przypisywane Claude’owi Shannon’owi powiedzenie “Wróg zna system” (ang. The enemy knows the system), znane pod nazwą Maksymy Shannona (ang. Shannon’s maxim).2
Zasadę tę, jako kryterium, można łatwo poszerzyć, usuwając ostatnie słowo do postaci:
Projekt systemu nie powinien wymagać jego tajności, a ewentualne jego ujawnienie nie powinno przysparzać kłopotów.
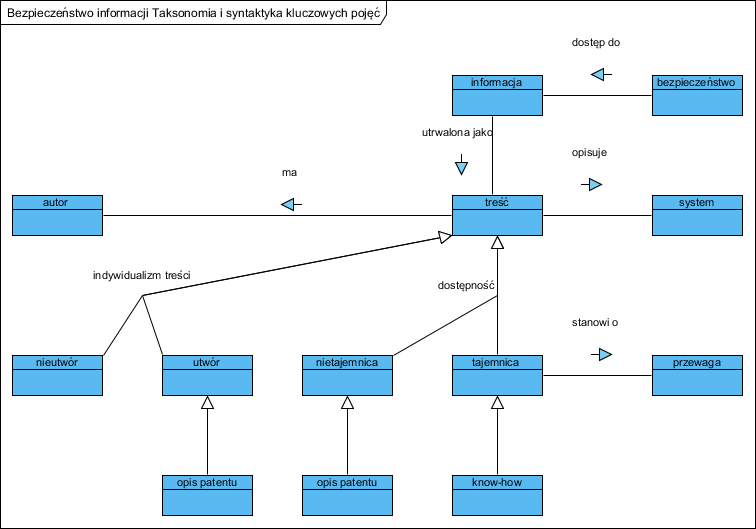
Na rynku mamy dwa przeciwstawne w pewnym sensie (o tym dalej) pojęcia: patent oraz know-how, dodać należało by do tego zestawu pojęcie prawo autorskie osobiste i majątkowe.
O bezpieczeństwie biznesowym
Na początek klasycznie kluczowe definicje:
know-how: rozumiane jest jako pakiet nieopatentowanych informacji praktycznych, wynikających z doświadczenia i badań, które są: 1. niejawne (nie są powszechnie znane lub łatwo dostępne); 2. istotne (ważne i użyteczne z punktu widzenia wytwarzania Know-how: ochrona tajemnicy przedsiębiorstwa).
bezpieczeństwo: stan niezagrożenia (s.j.p.)
tajemnica: sekret; też: nieujawnianie czegoś (s.j.p.)
patent: dokument przyznający jakiejś osobie lub firmie wyłączne prawo do czerpania korzyści z wynalazku; też: to prawo (s.j.p.)
informacja: to, co powiedziano lub napisano o kimś lub o czymś, także zakomunikowanie czegoś (s.j.p.)
utwór: każdy przejaw działalności twórczej o indywidualnym charakterze, ustalony w jakiejkolwiek postaci, niezależnie od wartości, przeznaczenia i sposobu wyrażenia (Ustawa)
Dla zapewnienia i sprawdzenia jednoznaczności tego tekstu zbudujmy model pojęciowy (taksonomia i syntaktyka pojęć, przypominam, że nie korzystamy w takich analizach a ontologii, poniższy diagram to nie ontologia):
Warto tu zwrócić uwagę na to, że pojęcie opis patentu pojawia się w taksonomii indywidualizmu treści jak i jej dostępności. Innymi słowy opis patentu jest zarówno utworem jak i treścią nie będącą tajemnicą. I teraz pytanie: co należy chronić i dlaczego? To zależy…
Patent to monopol, jednak fakty pokazują, że monopole trzeba samemu egzekwować, co nie zawsze jest ekonomicznie uzasadnione, przy założeniu że koszty ochrony patentu nie powinny przekroczyć korzyści z jego posiadania. I nie mam tu na myśli tylko opłat dla Urzędu patentowego, a potencjalne stałe koszty ochrony z tytułu wytaczanych pozwów cywilnych za łamanie praw patentowych. Rynek pokazuje, że nie raz ochronę patentową można zastąpić ochroną z tytułu praw autorskich (treść opisu jakiegoś rozwiązania to utwór, patrz diagram powyżej) np. wzory przemysłowe, tym bardziej że są rzeczy których nie można opatentować, ale można opisać i chronić właśnie jako utwór (np. logikę oprogramowania).
Know-how
Know-how to kolejny ciekawy obszar, bo wymagający bardzo często ochrony. Patent z zasady jest treścią jawną, podawaną do publicznej wiadomości. Jeżeli ktoś uzna, że jego know-how stanowi o jego przewadze a nie chce czynić z niego patentu, to ma dwa wyjścia: (1) utrzymywać know-how na poziomie trudnym do naśladowania, to się nazywa utrzymywanie bariery wejścia (patrz analiza pięciu sił Portera), albo (2) utrzymywać know-how w tajemnicy przed konkurencją. To kluczowy prawdziwy powód podpisywania umów o zachowaniu poufności (drugi to prawo regulujące dostęp do informacji w spółkach giełdowych).
I teraz jeszcze raz cytowana na początku zasada:
Projekt systemu nie powinien wymagać jego tajności, a ewentualne jego ujawnienie nie powinno przysparzać kłopotów.
I to jest ideał (idealizacja) do prowadzenia analiz. Punktem wyjścia w projekcie powinna być analiza sprawdzająca czy faktycznie ujawnienie danej informacji przynosi szkodę a jeżeli tak, to dlaczego. Dalej: jeżeli know-how stanowi sobą określony mechanizm i jego ujawnienie przynosi szkodę, to faktycznie należy go – jego opis – chronić. Jak? Przede wszystkim taki, precyzyjny, opis musi w ogóle powstać. Jeżeli z jakiegoś powodu nie może być przedmiotem patentu, to pozostaje prawo autorskie. A skoro tak, to: (1) posiadaczem prawa majątkowego do opisu know-how powinien być ten, kto chroni swoje know-how, (2) jeżeli oprogramowanie ma realizować mechanizm stanowiący know-how, to dostawca (wykonawca) tego oprogramowania nie powinien mieć żadnych praw do tego know-how, o ile tylko faktycznie stanowi ono o przewadze na rynku.
Ideał jest taki jak zasada powyżej, wniosek zaś jest taki, że jeżeli o przewadze rynkowej stanowi tajemnica, jej bezpieczeństwo staje się kluczowe. A jak chronić tajemnicę czyli informacje? W ten sam sposób: system opisujący bezpieczeństwo informacji opisuje się procedurami i procesami :), a te właśnie (dokumenty opisujące procesy), zgodnie z zasadą opisaną na początku, nie powinny wymagać ochrony…
Warto na koniec dodać, że na gruncie ustawy o zwalczaniu nieuczciwej konkurencji know-how nabywane przez pracowników IT podlega obowiązkowi ochrony tajemnicy przedsiębiorstwa, który od dnia 4 września 2018 r. został określony jako bezterminowy…
Na zakończenie
Bardzo często jestem pytany o różnicę pomiędzy chronionym utworem a chronionym know-how. Popatrzmy na poniższą mapkę, znaną z książki (i gier) Wyspa Skarbów:
Otóż mapka ta jest chroniona prawem autorskim jako obraz graficzny. Jeżeli prawdą zaś jest, że treść mapki zawiera wiedzę o tym jak dotrzeć do skarbu, to wiedza ta stanowi know-how piratów i jest trzymana w tajemnicy. Tak więc mapka ta jest utworem niosącym wiedzę o know-how. :). Wystarczająco precyzyjny projekt architektury i logiki działania oprogramowania jest także utworem, niosącym wiedzę o know-how.
A teraz popatrzcie Państwo na swoje umowy z dostawcami oprogramowania… i miejcie ograniczone zaufanie do prawników firm dostawców oprogramowania 🙂
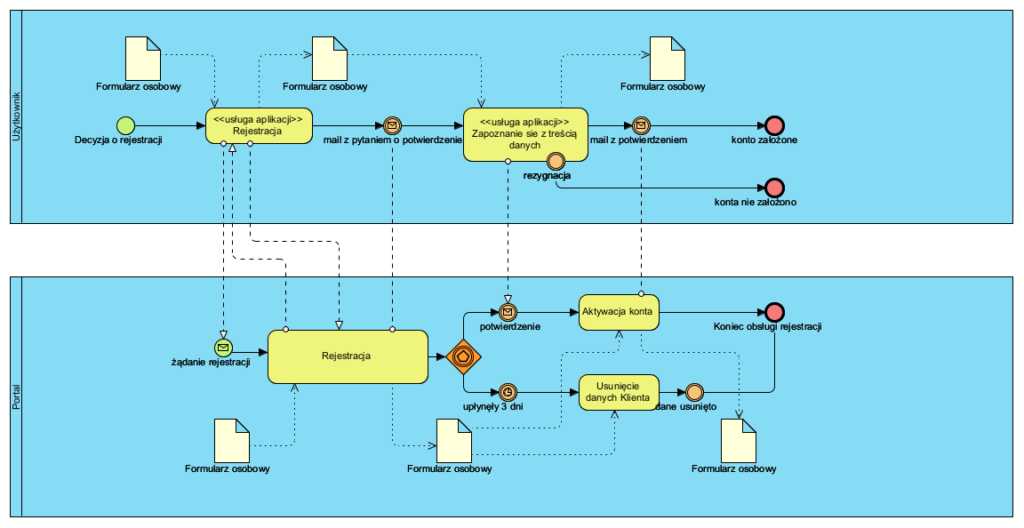
Dodatek: bezpieczeństwo systemowe znane także jako bezpieczeństwo proceduralne
Klasycznym jego przykładem jest uwierzytelnienie dwuskładnikowe (2FA) czy potwierdzanie double opt-in (model procesu poniżej).
Nawiązując do Zasady Kerckhoffs’a, bezpieczeństwo (metody i narzędzia) nie powinny być tajne (bezpieczeństwo przez zaciemnienie), gdyż wtedy “jedno ujawnienie” niszczy to bezpieczeństwo. Zarówno procedury 2FA jak i opt-in (to tylko dwa z wielu przykładów) nie są tajemnicą, a mimo to nikt nie powie, że ich stosowanie jest niebezpieczne.
Testowanie bezpieczeństwa informacji powinno się odbywać na poziomie procesów biznesowych i procedur. Jeżeli tu istnieją “luki” to żadna technologia szyfrowania i systemy haseł niczego nie zmienia na lepsze ale niewątpliwie podniosą koszty.