Obydwa te, spotykane często w prasie, skróty mają wiele wspólnego: oznaczają aplikacje zarządzające obiegiem informacji i jej magazynowaniem (ECM – Electronic Content Management czyli zarządzanie treścią w postaci elektronicznej oraz EOD – Elektroniczny Obieg Dokumentów). Cechą zawartą “nie wprost” w tych nazwach jest zarządzanie także składowaniem i przepływem tej informacji. Osiem lat temu pisałem o kwestiach pojęciowych (czym jest wiedza, jej przetwarzanie, czym są dane):
Problematyka informacji w firmach, jej kolekcjonowania i przetwarzania jest częstym tematem artykułów w prasie specjalistycznej jak i opisem zakresów projektów IT. Termin ten jest jednak nie raz nadużywany. W prasie można pozwolić sobie na pewną dowolność jego interpretacji jednak w opisie zakresu projektu analitycznego pozycja o nazwie ?Zdefiniowanie potrzeb informacyjnych firmy? może rodzić poważne kłopoty z odbiorem tej części projektu gdyż tu na dowolność interpretacji nie powinno być miejsca. (Źródło: Zarządzanie Wiedzą | Jarosław Żeliński IT-Consulting)
Niedawno, 26 stycznia 2016, miałem referat na konferencji pod hasłem Business Process Management:
W trakcie referatu zwróciłem uwagę na to, że to co często nazywamy zarządzaniem procesami (popularny skrót [[BPM]]) biznesowymi, tak na prawdę jest zarządzaniem przepływem pracy, zarządzaniem informacją i nadzorowaniem tych aktywności. Tu zwrócę uwagę na to, że przepływ pracy odwzorowywany jest w aplikacji jako ciąg raportów i notatek:
przełożony dowiaduje się o wykopaniu rowu nie z własnej obserwacji a z raportu swojego podwładnego
dlatego oprogramowanie może operować wyłącznie udokumentowanymi faktami a nie zjawiskami w realnym świecie: to są zapisy jakimi zarządza oprogramowanie zarządzające szeroko pojętą treścią. Tak więc
zarządzanie procesami biznesowymi to nic innego jak zbieranie informacji, przetwarzanie ich i decydowanie o kolejnych pracach do wykonania, informując o tym wykonawców tych kolejnych prac.
Aplikacja wspierająca przepływ pracy to oprogramowanie, które pozwala na tworzenie formularzy (i zasad weryfikacji ich poprawności) specyficznych dla każdego zadania, reguł biznesowych narzucających opcjonalność i kolejność realizacji zadań (aktywności), kategoryzowanie treści i zadań, udostępnianie powstałych treści:

Powyższy diagram przypadków użycia można w zasadzie uznać za “referencyjny”, każda aplikacja tego typu tak mogła by wyglądać, czy to wystarczy dostawcy oprogramowania? Nie, bo cała wiedza o konkretnym wdrożeniu tkwi w szczegółach. Gdzie one są? Pisałem o tym prawie rok temu:
Tu warto na początek wrócić do klasyfikacji wymagań. W artykule Inżynieria wymagań opisałem trzy ich rodzaje: (1) funkcjonalne czyli usługi aplikacji (przypadki użycia tej aplikacji), (2) poza-funkcjonalne czyli cechy jakościowe, (3) dziedzinowe czyli logika biznesowa. I teraz bardzo ważna rzecz: które elementy architektury oprogramowania, za realizację których wymagań odpowiadają? (Źródło: Gdzie są te cholerne szczegóły | | Jarosław Żeliński IT-Consulting)
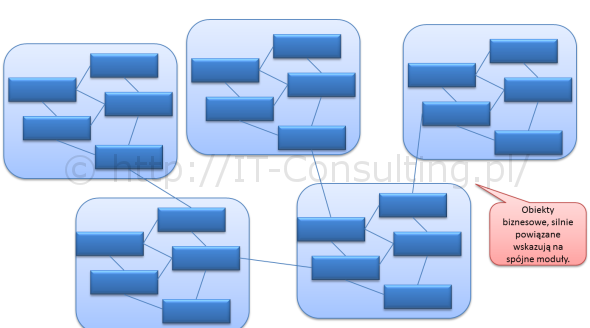
Jak widać, klucz tkwi w modelu dziedziny systemu czyli w specyfice branży, konkretnej firmy lub organizacji. Powyższe przypadki użycia, jak wyżej, to opis “dowolnego ECM/EOD”. Referencyjna architektura takiego systemu mogła by mieć taką postać:

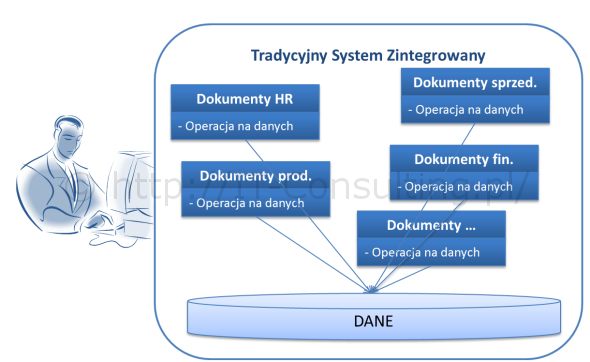
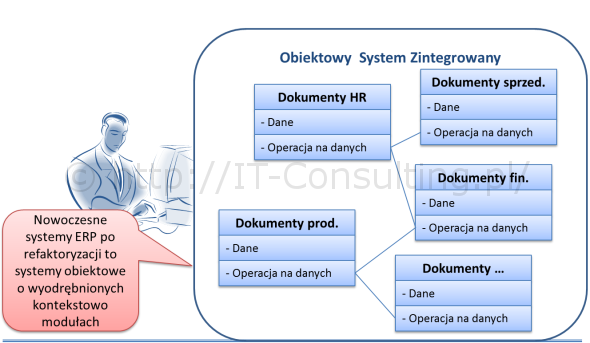
Dlaczego tak? Komponent zarządzający procesami odpowiada za logikę kolejności przetwarzania treści. Repozytorium odpowiada za zachowywanie i udostępnianie treści. Dodano tu komponent Filesystem, gdyż osobiście jestem zwolennikiem podejścia, w którym dokumenty elektroniczne są składowane nie w bazie danych (tak zwane BLOB) a na dyskach, a logika zarządzania nimi to odrębne oprogramowanie (patrz europejksie zalecenia Moreq). Dzięki temu utrata lub zmian aplikacji (i bazy danych) nie powoduje utraty zasobów.
Na czym więc polega analiza biznesowa przed wdrożeniem EOD/ECM? Czym są tu wymagania? Są nimi reguły biznesowe, wzory dokumentów i słowniki pojęć (danych). To tu tkwi największe ryzyko wdrożenia, kluczem jest tu zawsze tak zwany model pojęciowy. Powyższa architektura jest przeze mnie traktowana jako referencyjna, gdyż gwarantuje możliwość odwzorowania dowolnego “systemu zarządzania informacją”, taką lub podobną zalecaną architekturę można spotkać w wielu opracowaniach na temat ECM.