W perspektywie krótkoterminowej architektura oprogramowania pomaga zredukować czas i koszty rozwoju.
https://medium.com/@learnwithwhiteboard_digest/basics-of-software-architecture-a-guide-for-developers-8098a76881ca
W dłuższej perspektywie architektura oprogramowania pomaga zredukować koszty utrzymaniu.
Wstęp
W 2017 roku pisałem dość ogólnie o logice wzorca architektonicznego MVC kończąc artykuł słowami:
A gdzie mityczna baza danych? Tam gdzie jej miejsce: zarządza danymi utrwalanymi w pamięci. Baza danych i systemy zarządzania danymi w architekturze obiektowej nie stanowią miejsca na logikę biznesową, standardowym wzorcem projektowym jest tu active records. Podstawową zaletą stosowanie tego wzorca jest separacja utrwalonych danych od aplikacji. To pozwala skupić całą logikę i jej zmienność w kodzie aplikacji i jego architekturze. Dzięki temu można spełnić zasadę Open Close principia bez refaktoringu bazy danych i migracji danych, co miało by miejsce gdyby była to jednolita relacyjna baza danych dla całej aplikacji. Zachowanie separacji i hermetyzacji obiektów do poziomu danych włącznie (jeżeli obiekty współdzielą dane w bazie danych niszczy to ich separację), uwalnia nas od problemu ??jednolitego modelu danych?.
Source: MVC – komponent Model w architekturze systemu – Jarosław Żeliński IT-Consulting
W sieci jest wiele opisów tego wzorca, jednak nie wszystkie są poprawne, szczególnie tam gdzie autorzy piszą, że to odpowiednik trójwarstwowej architektury: warstwy prezentacji, logiki i danych czy też, że wzorzec ten separuje logikę biznesową i dane jako odpowiednio controller i model. Gdyby tak było, byłaby to trójwarstwowa architektura, a nie obiektowy wzorzec architektoniczny. Model-View-Controller. Nie jest też prawdą, że te trzy komponenty są połączone w trójkąt, gdzie aktor ma jakieś bezpośrednie interakcje z komponentem Controller czy Model (pytanie jak?).
Co można spotkać w sieci? Po wpisaniu do wyszukiwarki “model view controller pattern” na pierwszej stronie zobaczymy np. to:
Jak widać różnorodność jest dość duża. Co ciekawe, nadal wzorce MVC i BCE bywają mylone lub uznawane za ten sam wzorzec, co jest ogromnym błędem. Warto też zwrócić uwagę na częste nadużywanie i nieprawidłowe stosowanie przez projektantów i developerów notacji UML [zotpressInText item=”{5085975:9RYKUZ67}”].
Ten artykuł powstał między innymi na bazie wybranych formalnych (literatura na końcu) i nieformalnych (poniższe) źródeł opisujących wzorce i frameworki:
Chrome Developers. ?MVC Architecture?. Accessed 18 November 2022. https://developer.chrome.com/docs/apps/app_frameworks/.
InterviewBit. ?MVC Architecture – Detailed Explanation?, 27 May 2022. https://www.interviewbit.com/blog/mvc-architecture/.
Prabhu, John. ?MVC Architecture & Its Benefits in Web Application Development?. Tech Blogs by TechAffinity (blog), 18 July 2019. https://techaffinity.com/blog/mvc-architecture-benefits-of-mvc/.
Shishkov, Boris. Designing Enterprise Information Systems Merging Enterprise Modeling and Software Specification, 2020.\
Svirca, Zanfina. ?Everything You Need to Know about MVC Architecture?. Medium, 30 May 2020. https://towardsdatascience.com/everything-you-need-to-know-about-mvc-architecture-3c827930b4c1.
Od przypadków użycia, przez MVC do ICONIX/BCE
Opisywane tu metody pracy i ich produkty wywodzą sie z zaliczanej do zwinnych, obiektowo-zorientowanej metodyki ICONIX i jej pochodnych. Jej podstawą jest orientacja na przypadki użycia i komponentowo-obiektowy charakter architektury dzielonej na HLD (architektura aplikacji) i LLD (wewnętrzna architektura komponentów). Co ciekawe metoda ta od początku jej powstania abstrahuje od technologii i modelu danych [zotpressInText item=”{5085975:KID8ZABH},{5085975:P7WIX63W}”]. Swego czasu podjąłem próbę usystematyzowania podstawowych wzorców projektowych na tle MDA [zotpressInText item=”{5085975:TBT7B5D2}”]. Ta, potrójnie recenzowana, publikacja jest dostępna w IGI Global (IGI Global jest wiodącym, średniej wielkości, niezależnym wydawcą akademickim międzynarodowych badań naukowych). Poniżej kluczowe elementy tego opracowania dotyczące wzorca MVC i pokrewnych. Osobom zainteresowanym detalami polecam lekturę tej publikacji.
Zakres projektu
Zawieranie umowy na zakres projektu i projektowanie to inżynieria (a nie inżynieria wymagań, po prostu inżynieria, ewentualnie inżynieria oprogramowania, albo ogólniej inżynieria systemów).
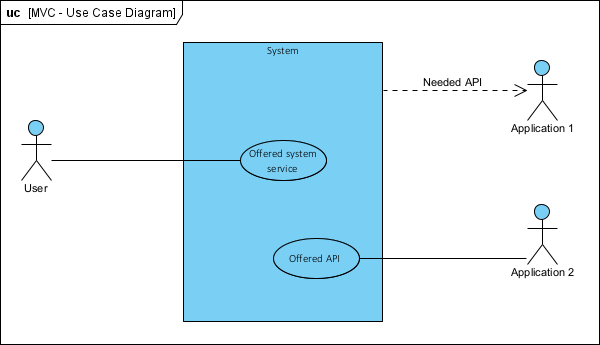
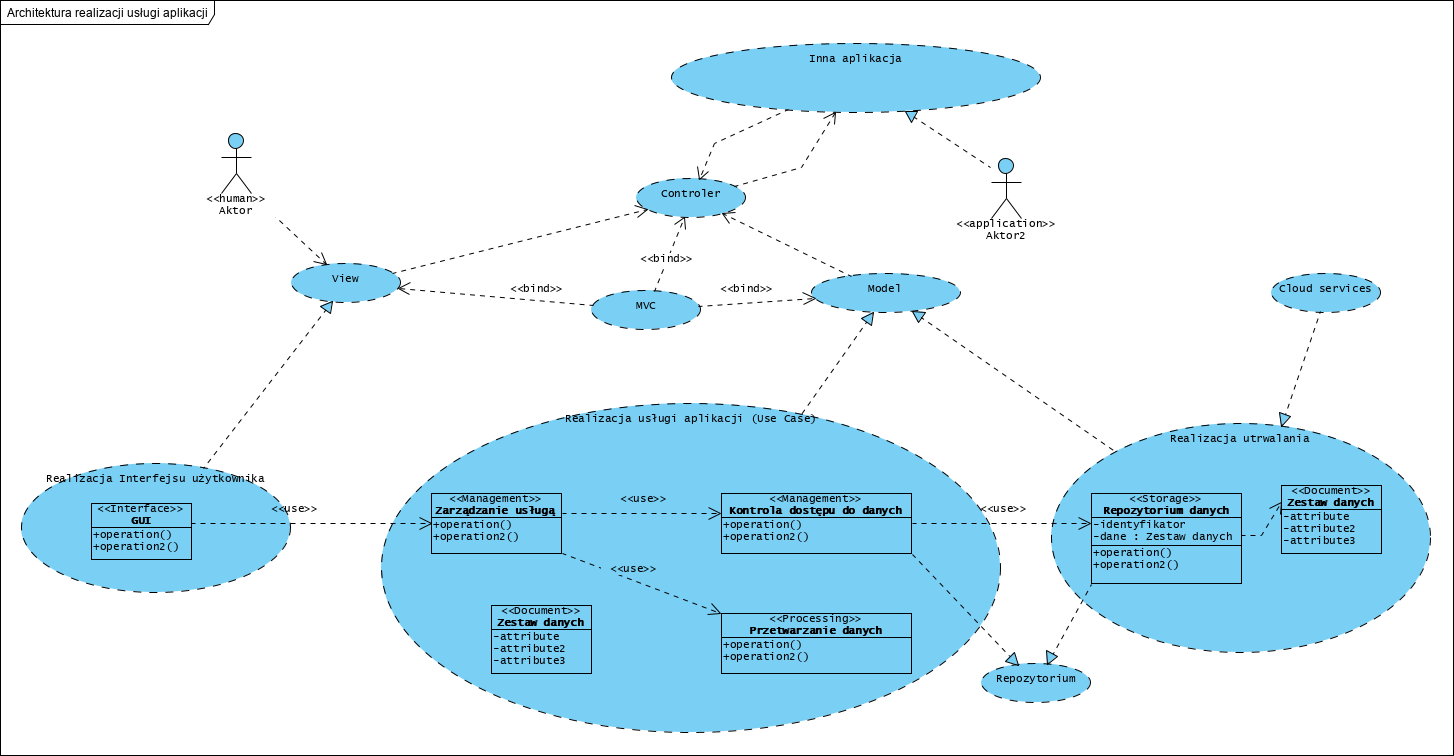
Zakres projektu to usługi aplikacyjne jakie ma świadczyć System. Kontekst systemu to jego otoczenie wyrażone w postaci aktorów (User, Application 1, Application 2). Powyższy System realizuje dwie usługi: jedną użytkownikowi, drugą wewnętrznemu systemowi (Application 2). Sam zaś korzysta z usług zewnętrznego systemu Application 1.
Kolejny etap to opracowanie architektury Systemu. Tu najczęściej korzystamy właśnie z wzorca MVC.
Wzorzec MVC
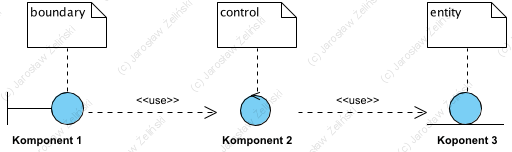
Jest to tak na prawdę podział aplikacji na środowisko wykonawcze (Controller, to praktycznie runtime systemu), środowisko pracy użytkownika (View) oraz “motor systemu” czyli logika zdefiniowana jako “mechanizm działania systemu”: jest to właściwy projekt PIM aplikacji i potem jej serce [zotpressInText item=”{5085975:AH5MN5KL}”].
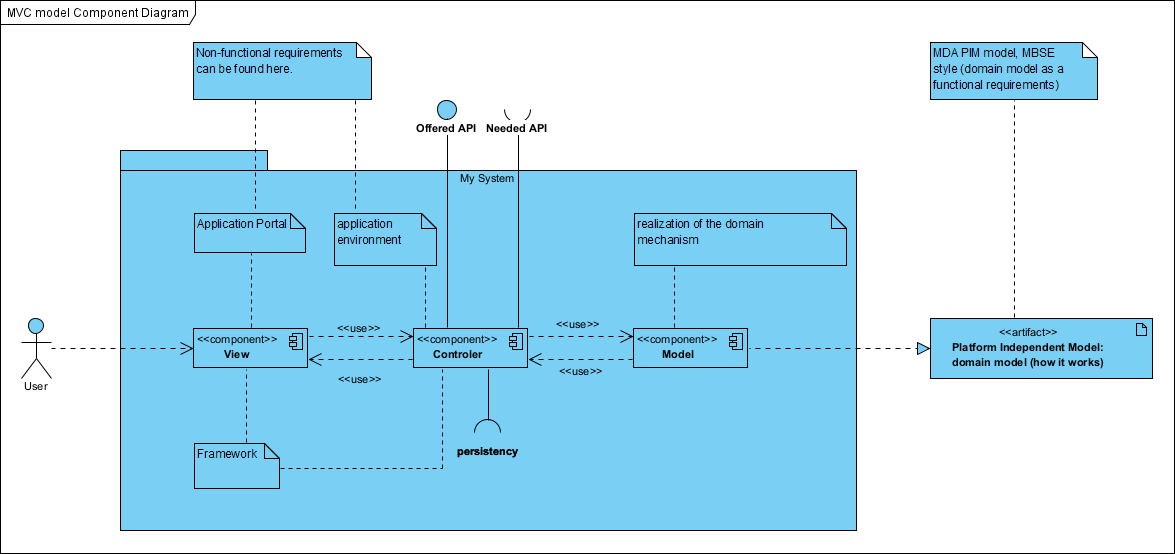
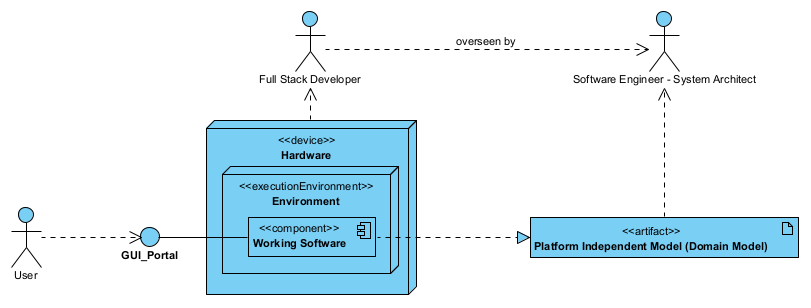
Powyższy diagram to wewnętrzna architektura Systemu pokazanego wcześniej na diagramie przypadków użycia. Działająca aplikacja to środowisko (View i Controller) oraz właściwy program aplikacji (Model, patrz też Domanin Model).
Model PIM naszej aplikacji to specyfikacja, wyrażona jako modele w notacji UML. Na powyższym diagramie jest to element Domanin Model, oznaczony na diagramie stereotypem ‘artifact’. Jest to w nomenklaturze prawnej (przetargi) tak zwany Opis Techniczny Oprogramowania czyli: struktura i dynamika aplikacji, algorytmy, modele danych, itp., wyrażone w sposób techniczny, czyli w postaci schematów blokowych wykonanych w notacji UML. Developer, w wybranej przez siebie technologii, wykonuje implementację, czyli oprogramowanie realizujące ten model. Jest to wyrażanie wymagań w formie modelu systemu (MBSE).
Powyższa forma to logiczna postać tego wzorca (MVC) pokazująca komunikację między tymi trzema komponentami. Znacznie właściwsze było by pokazanie komponentu Controller jako środowiska wykonawczego (biblioteki i API do otoczenia systemowego) co zobrazowano poniżej:

ICONIX i wzorzec BCE
Wzorzec BCE ma swój rodowód w metodyce ICONIX [zotpressInText item=”{5085975:KID8ZABH},{5085975:P7WIX63W}”]. Pierwotnie oparty był na frameworku EJB i wspierał projektowanie w tym środowisku (robustness diagram, odnośniki do POJO, DAO, model dziedziny, dlatego teraz EJB nazwany anemicznym modelem i antywzorcem). Kluczową ideą wzorca ICONIX orientacja architektury i procesu projektowego na przypadki użycia, rozwijana później przez Jacobsona i innych pod nazwą Use Case 2.0 [zotpressInText item=”{5085975:IENSXKK5},{5085975:XSXM2FP8}”].
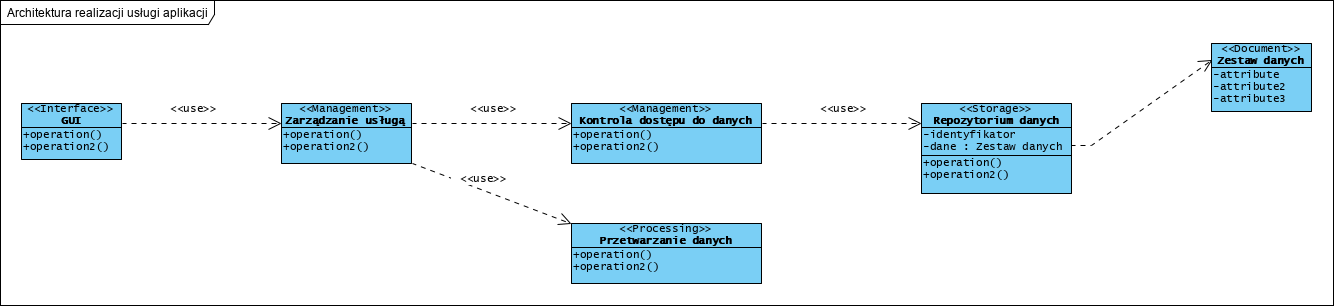
Każda usługa aplikacji w tym podejściu (jej przypadek użycia) to niezależny zamknięty komponent, dostępny przez jego własne API. Komponent taki może mieć (i z reguły ma) udokumentowaną własną wewnętrzną, nie raz nietrywialną, architekturę:
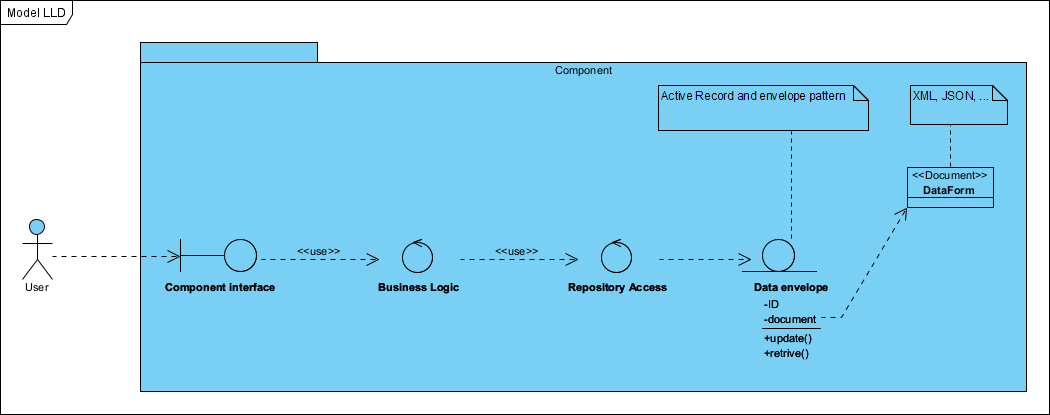
Każda usługa jest realizowana przez kluczowe typy komponentów: interfejs komponentu, realizacja logiki biznesowej (dziedzinowej), realizacja dostępu do obiektów w repozytorium, obiekty w repozytorium (nośniki danych zapisywanych tu w postaci dokumentów). Wzorzec BCE był tu opisywany szerzej w artykule Wzorce projektowe w analizie i projektowaniu modelu dziedziny systemu.
Wiele emocji i kontrowersji budzi dokumentowa metoda zarządzania danymi. Dane są tu zapisywane w zwartej zmaterializowanej postaci. Najczęściej w formacie JSON lub XML (element DataForm oznaczony stereotypem ‘Document’). Jeżeli jest to nowy komponent starej aplikacji, zbudowanej na relacyjnym modelu danych, najczęściej stosowany jest w tym miejscu wzorzec projektowy Active Record, rzadziej Active Table. Z jego pomocą operacje update i retrieve obiektów klasy “Data envelope”, są implementowane jako zapytania SQL do relacyjnej bazy danych. Klasa “Data envelope” stanowi wtedy API do tej starej bazy danych. Takie podejście uniezależnia projektanta i projekt, od metody i technologii utrwalania danych oraz od potrzeby znajomości SQL. Jako projektant uważam, że jest to dobre wyjście przy rozbudowie starych systemów legacy. Jednak model relacyjny, szczególnie w systemach biznesowych, stanowi ogromne ograniczenie rozwojowe na przyszłość i uniemożliwia stosowanie repozytoriów NoSQL w chmurze.
Podsumowanie
Podstawową zalecą wzorca MVC jest odseparowanie (hermetyzacja) logiki dziedzinowej od środowiska wykonawczego aplikacji. Dzięki czemu możliwe jest projektowanie wyłącznie modelu dziedziny systemu i jego późniejsza, niezależna od technologii, implementacja. Dodatkową korzyścią jest tu powstająca dokumentacja, stanowiąca ochronę know-how sponsora projektu, co w obecnych czasach nabiera coraz większego znaczenia.
Dostępne w literaturze schematy blokowe pokazujące ideę wzorca MVC, pokazują często logikę działania tego wzorca, rozumianą jako przesyłanie komunikatów. Stąd prawdopodobnie schematy w postaci trójkąta. Jednak warto wiedzeć, że fizycznie jest to podział aplikacji na jej środowisko (biblioteki, API to otoczenia) i komponent realizujący dziedzinową logikę, która odpowiada za realizację funkcjonalności oprogramowania. Odmianą tego wzorca jest MV-VM. Jest to wzorzec uwzgledniający fakt, że środowisko wykonawcze może być podzielone na część serwerową i część wykonywaną np. w przeglądarce WWW (patrz artykuł Aplikacje webowe i mikroserwisy czyli architektura systemów webowych) lub w smartfonie. Przeglądarka WWW, czy system operacyjny (środowisko) smartfona, to kolejny runtime: zestaw lokalnych bibliotek i API do otoczenia (np. lokalna pamięć, dysk twardy, dane z modułu GPS, itp.).
Dodatek: inżynier vs. developer
Dlatego od pewnego czasu już rozróżniamy pojęcie “software engineer” i “software developer”. Drugi opracowuje i wykonuje implementacje tego co zaprojektuje pierwszy. Pojęcie programisty ma od pewnego już czasu nieco inny kontekst:
Programming is not solely about constructing software?programming is about designing software.
[zotpressInText item=”{5085975:NZCQDD79}”]
Pamiętajmy więc, że programowanie to opracowanie tego jak ma być przetwarzana informacja reprezentowana jako dane w aplikacji, a nie tego jaką technologią mają być przetwarzane dane. To drugie realizuje developer, pierwsze inżynier, architekt całego systemu.
software developer vs software engineer
https://www.randstad.co.uk/career-advice/career-guidance/full-stack-developer-vs-software-engineer/
Generally, software engineers look after the bigger picture, while software developers focus on one area to execute their plans. Engineers can act as developers, too, or simply oversee developers who create functional programs.
Tak więc opracowanie modelu dziedziny systemu, czyli zaprojektowanie systemu, to rola inżyniera, który tu jest architektem systemu informacyjnego. Zaprojektowanie środowiska wykonawczego o opracowanie implementacji to rola developera:
Źródła
[zotpressInTextBib style=”apa” sortby=”author” sort=”ASC”]