Wprowadzenie
Bardzo często można w książkach i na blogach spotkać opisy wzorców architektonicznych, wzorców projektowych, dobrych praktyk. Jednak bardzo rzadko autorzy piszą o tym kiedy je stosować. Sam fakt, że jakiś wzorzec “rozwiązuje jakiś problem”, co jest celem tworzenia i stosowania danego wzorca, nie mówi nic o tym jak często i kiedy dany problem się pojawia.
Komputer może być częścią firmy, samochodu, lodówki, telewizora, może być platformą dla oprogramowania użytkowego albo dla gier komputerowych, ale te – użyte – staja sie częścią tego komputera (gramy na komputerze a nie na grze). Oprogramowanie użytkowe czy gry komputerowe (to też oprogramowanie) mają pewne cechy. Kluczową cechą jest zmienność mechanizmu działania lub całkowity brak takiej zmienności. W efekcie inne problemy rozwiązuje projektant gry czy systemu operacyjnego (tu w zasadzie nic sie zmienia), a inne projektant aplikacji której zadaniem jest np. zgodne z prawem fakturowanie wyprodukowanych wyrobów czy zrealizowanych usług (tu zmiany mogą zachodzić nawet kilka razu w roku).
Tak więc owszem, software to “słoń w pokoju” inżynierii [zotpressInText item=”{5085975:Y3KLU3JX}”].
Komputer
Komputer to generalnie procesor, pamięć i program. Jako materialna całość stanowi sobą jednak dość skomplikowane urządzenie zawierające także porty i urządzenia wejścia i wyjścia, a także elektromechaniczną część czyli zasilanie, obudowę, klawiaturę, ekran, mysz, wentylację itp. Nie zmienia to faktu, że jest to urządzanie realizujące określony mechanizm, jego zachowanie się “jest programowane”, czyli zachowanie się tego urządzenia jest efektem wykonywania przez procesor komputera kodu programu przechowywanego w pamięci, ten zaś jest niczym innym jak procedurą (zestawem procedur). Dlatego mówimy, że komputer to uniwersalny mechanizm [zotpressInText item=”{5085975:ZCXJ2S7U}”].
Urządzeniami wejścia i wyjścia mogą być nawet bardzo skomplikowane konstrukcje elektromechaniczne a całość może być nie tylko maszyną do pisania ale także robotem przemysłowym czy autonomicznym samochodem. Większe systemy (mechanizmy) dzieli się często na mniejsze części: komponenty, a te – każdy – może być samodzielnym urządzeniem zawierającym komputer. Notebook, który prawdopodobnie czytelnik tego tekstu ma teraz przed sobą, to złożone urządzenie. Wiele jego komponentów: dysk twardy, karta graficzna, klawiatura, ma swój procesor.
Wiele urządzeń, pierwotnie w 100% elektromechanicznych, ewoluuje do hybrydy: urządzenie elektromechaniczne + komputer, nazywamy to urządzeniem “mechatronicznym”. Prostym i typowym przykładem są zegary i programatory mechaniczne (np. pralki, obrabiarki). Bardziej wyrafinowane są urządzenia przetwarzające sygnały (zamiana analogowych urządzeń na cyfrowe), np. telefonia i telewizja. Proces ten postępuje (np. zegar obecnie może być w 100% komputerem). System ERP to też takie urządzenie.
Poniżej wykres pokazujący rosnący udział kosztów oprogramowania w urządzeniach, odpowiada to temu, że coraz więcej funkcji w tych urządzeniach realizuje (przejmuje) komputer [zotpressInText item=”{5085975:I7N5YSN4}”]. Trend ten nie jest nowy [zotpressInText item=”{5085975:2JAV96GM}”]. Więcej [zotpressInText item=”{5085975:NLT4Z5MI}”].
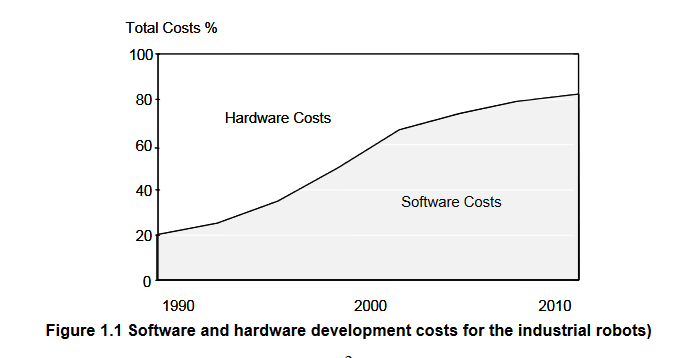
Jeżeli, kiedyś zegar odmierzał czas z pomocą wahadła i kół zębatych, a teraz role te pełnią procedury wykonywane przez procesor, to znaczy że komputer ma tę samą funkcjonalność co klasyczny zegar, ale nadal mechanizm pomiaru czasu to sekundy, minuty i godziny (patrz Zegar). Wielu autorów nazywa to wirtualizacją tego mechanizmu [zotpressInText item=”{5085975:5MQBZYDU}”].
Schematycznie urządzenie mechatroniczne mozna pokazać tak:
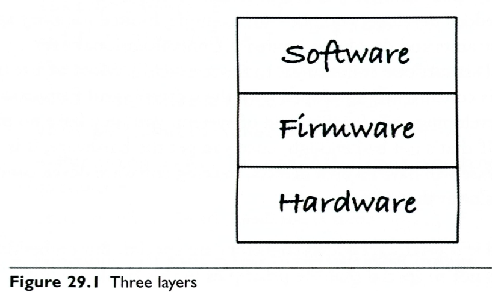
Są tu trzy kluczowe warstwy:
- hardware – sprzęt elektromechaniczny,
- firmware – sterowniki (ang. drivery) czyli interfejsy oferowane pomiędzy częścią elektromechaniczną a programową,
- software – funkcje systemowe i aplikacyjne, czyli właściwy kod, tu dobrą praktyką (wzorcem architektonicznym) jest wydzielenie (oddzielenie kodu, implementacji) kodu logiki dziedzinowej, reszta to tak zwane środowisko systemowe: system operacyjny i jego otoczenie.
Znakomita większość tej układanki to standardowe produkty, które praktycznie nie są modyfikowane od momentu ich wytworzenia. Są to: sprzęt oraz sterowniki dostarczane wraz z nim, systemy operacyjne i środowiska programistyczne (system operacyjny, biblioteki programistyczne, kompilatory). Pozostaje clue czyli wirtualizowany mechanizm co pokazano poniżej:
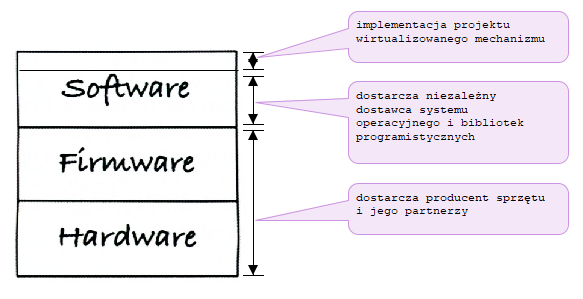
Jeżeli więc wirtualizujemy jakiś mechanizm jako program komputera, to kodowanie (pisanie kodu w jakimś języku programowania) de facto jest konfigurowaniem zachowania tego komputera. Pozostaje jedynie wcześniej opisać lub zaprojektować wirtualizowany mechanizm (opracować dokument zawierający modele np. w notacji UML).
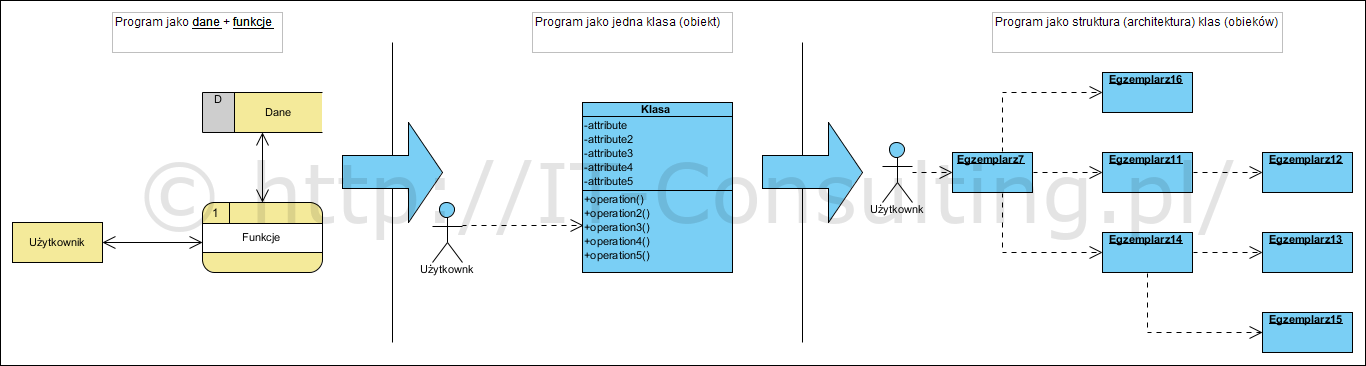
Model systemu i ochrona wartości intelektualnych
Z perspektywy dziedziny zwanej informatyką lub technologią informatyczną, najczęściej mamy do czynienia z oprogramowaniem określanym jako aplikacje biznesowe. Jest to oprogramowanie wspomagające zarządzanie takie jak CRM, ERP, workflow itp. ale także sklepy internetowe czy kasy samoobsługowe. Aplikacje te często pochodzą z różnych źródeł i wtedy są integrowane (patrz Integracja ERP).
Struktura systemu informatycznego w średniej wielkości organizacji może schematycznie wyglądać jak pokazano poniżej:
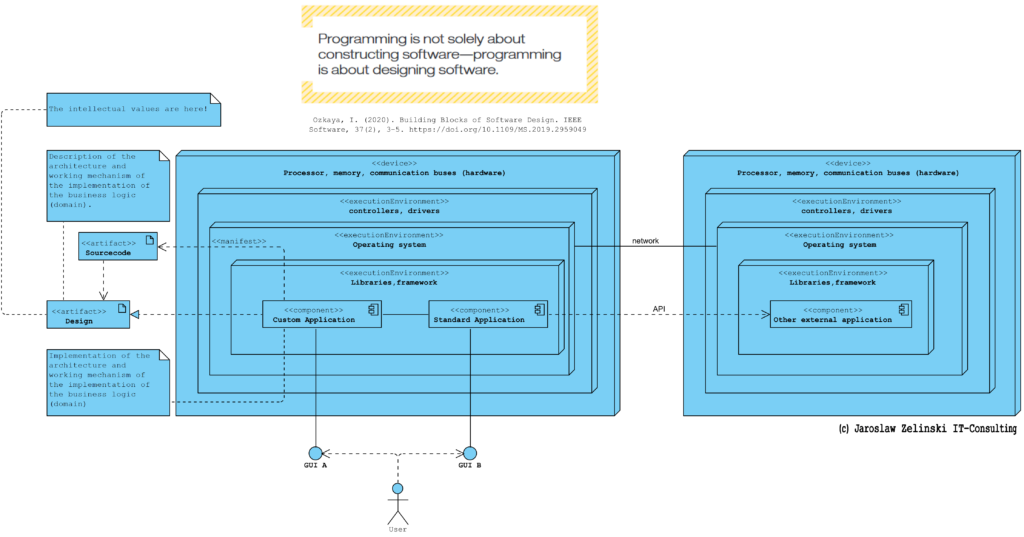
Warto tu zwrócić uwagę na kwestię tego czym tu są, i czyje są, chronione wartości intelektualne (ang. IP, Intellectual Properties). Na powyższym diagramie w zasadzie każdy element może być licencjonowany od innej firmy. Coraz częściej jednak zdarza się, że organizacja, w pewnym obszarze, cechuje się pewną własną, unikalną logiką działania. Rzadko jest to więcej niż 10% całości mechanizmów działania danej organizacji gdyż większość wymuszają prawo i standardy branżowe. Jednak organizacje, szczególnie te które wyróżniają sie na rynku, cechują się pewna specyfiką, unikalnym elementem sposobu swojego działania. Wtedy powstaje potrzeba stworzenia dedykowanego oprogramowania (Custom Application). Wymaganiem wobec oprogramowania, czyli de facto komputera, jest ten specyficzny mechanizm działania, który musi zostać opisany aby możliwa była jego ochrona jako ww. wartości intelektualne i jego odtworzeniem z pomocą komputera (wirtualizacja). Np. archiwum treści w postaci e-booków to nic innego jak zwirtualizowane archiwum papierowe wraz z zasadami dostępu do zasobów, rejestracją udostępniania itp.
Od wielu lat toczą się spory na temat tego czy i jak chronić to powyżej opisano. Aktualne prawodawstwo powoli ale systematycznie zmierza jednak do tego, by chronić opis mechanizmu a nie kod, który go implementuje:
Prawa autorskie, chociaż nie doprowadziły do tak wielu jawnie absurdalnych zgłoszeń, zostały mocno rozciągnięte przez sądy. Pojęcie, pierwotnie mające na celu ochronę prac literackich, zostało tak rozszerzone, iż zawiera takie pisarskie „prace” jak programy komputerowe czy nawet kod maszynowy i kod wynikowy, którym bliżej do elementów maszyn, takich jak krzywka, niż do prac literackich. [zotpressInText item=”{5085975:QAHTAUZ4},{5085975:Y4W6IFZI}”]
Na tym tle ciekawe jest:
2.6. Wystarczające ujawnienie
Opis wynalazku powinien przedstawiać (ujawniać) wynalazek na tyle jasno i wyczerpująco, aby znawca mógł ten wynalazek urzeczywistnić, a ekspert mógł dokonać rzeczowej analizy porównawczej z dotychczasowym stanem techniki. Za „znawcę z danej dziedziny” uważa się przeciętnego praktyka dysponującego przeciętną, ogólnie dostępną wiedzą z danej dziedziny w odpowiednim czasie, który dysponuje typowymi środkami i możliwościami prowadzenia prac i doświadczeń. Przyjmuje się, że specjalista taki ma dostęp do stanu techniki; tzn. informacji zawartych w podręcznikach, monografiach, książkach. Zna także informacje zawarte w opisach patentowych i publikacjach naukowych, jeżeli wynalazek dotyczy rozwiązań, które są na tyle nowe, że nie są zawarte w książkach. Ponadto, potrafi korzystać ze stanu techniki w działalności zawodowej do rozwiązywania problemów technicznych. Przedstawiony wynalazek powinien więc nadawać się do odtworzenia bez dodatkowej twórczości wynalazczej. Pod pojęciem tym należy rozumieć dodatkową działalność umysłową, eksperymentalną związaną z niepełną informacją techniczną zawartą w opisie wynalazku, a także konieczność dodatkowych uzupełniających badań naukowych, niezbędnych do realizacji rozwiązania według wynalazku w pełnym zakresie żądanej ochrony. Odtworzenie wynalazku powinno być możliwe na podstawie przeciętnej wiedzy specjalisty w danej dziedzinie, bez nadmiernego wysiłku. [zotpressInText item=”{5085975:Y86V5TMQ}”].
Z perspektywy tematu tego tekstu w miejsce słowa “wynalazek” wystarczy wstawić słowo “produkt” (lub komputer). Dlatego niektórzy autorzy operują pojęciem “testu urzędu patentowego: “czy to COŚ można zgłosić jako patent”, i niestety żaden kod źródłowy nie spełnia twego warunku. Tu autor wynalazku (produktu) to projektant, zaś znawca zdolny do jego urzeczywistnienia, to deweloper.
Bezpieczeństwo
Kilka słów o bezpieczeństwie. W obszarze tak zwanego cyberbezpieczeństwa mówi się o podatnościach:
Podatności to luki w systemach informatycznych, które mogą być wykorzystane przez atakujących do uzyskania nieautoryzowanego dostępu do danych lub systemów. Mogą one wynikać z błędów w oprogramowaniu, niewłaściwej konfiguracji systemów, słabych haseł czy też zaniedbania w aktualizowaniu oprogramowania. Podatności stanowią poważne zagrożenie dla bezpieczeństwa, ponieważ mogą być wykorzystane do przeprowadzenia różnorodnych ataków, takich jak kradzież danych, przejęcie kontroli nad systemami, czy też zakłócenie działania usług.
W praktyce podatności mogą przyjmować różne formy. Przykłady obejmują exploity wykorzystujące luki w oprogramowaniu, ataki typu SQL Injection, które wykorzystują słabe zabezpieczenia baz danych, czy też błędy w konfiguracji serwerów, które pozwalają na nieautoryzowany dostęp. Każda z tych podatności może prowadzić do poważnych konsekwencji, w tym utraty danych, naruszenia prywatności, a nawet strat finansowych. (https://nflo.pl/baza-wiedzy/czym-jest-zarzadzanie-podatnosciami-it-vulnerability-management-i-dlaczego-jest-kluczowe-dla-cyberbezpieczenstwa/)
Definicje, taka jak powyższa, skupiają się na “systemie informatycznym” jednak należy odróżnić wadliwość zaimplementowanego mechanizmu od wadliwości jego implementacji (błędy w kodzie) oraz celowego działania dewelopera (exploity). Innymi słowy podatnościami mogą być:
- niskiej jakości projekt (złe procedury w mechanizmie działania aplikacji),
- niskiej jakości implementacja (błędy koderów),
- celowe działania projektanta i/lub dewelopera.
Powyższe może dotyczyć każdej ww. warstwy. Czy certyfikaty chronią? Paradoksalnie bardzo słabo: wiele znanych z prasy włamań, a w dużych instytucjach wszystkie, to włamania do organizacji i ich systemów, które miały certyfikaty.
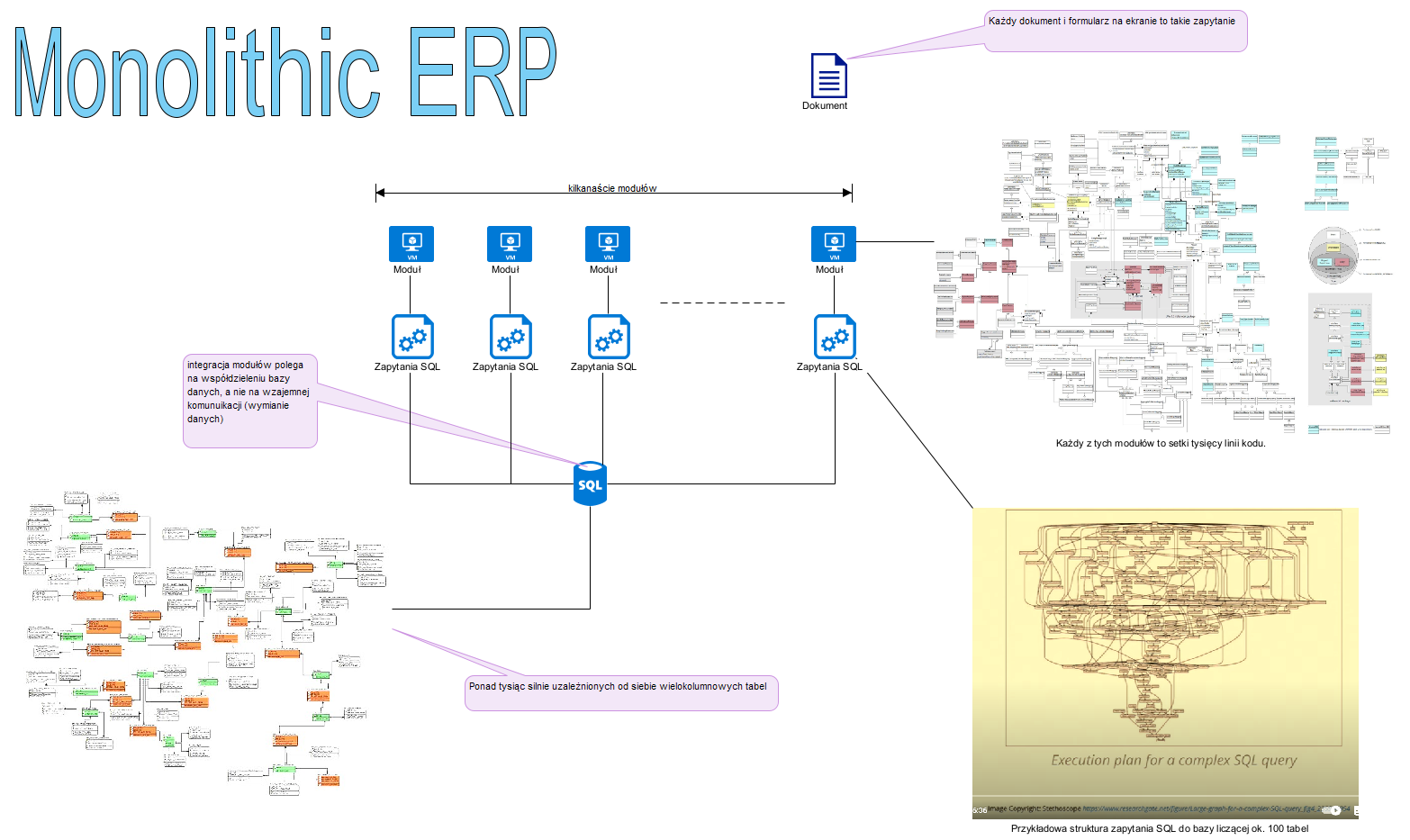
Bardzo niebezpieczne (stwarzają ogromne ryzyko) są monolityczne aplikacje (jeden błąd i cały system jest otwarty). Najskuteczniejszą metodą ochrony jest dzielenie systemu na komponenty bo mogą one kontrolować się wzajemnie, a podatność zamknie się jednym komponencie, czyli w razie ataku nie “padnie” cały system a jeden jego komponent. Te komponenty nie powinny pochodzić z jednej fabryki. Podział systemu na dziedzinowe aplikacje i ich integracja powoduje, że żaden dostawca nie ma “władzy” nad całością.
Źródła
[zotpressInTextBib style=”apa” sort=”ASC”]