(streszczenie referatu na konferencji zorganizowanej 30 stycznia 2025 przez pureconferences.pl).
Wprowadzenie
Narzędzia zwane low-code oraz no-code (LCNC) znane są od czasów komputerów zwanych biurkowymi (np. narzędzie Clarion, 1986 rok), takim narzędziem był także arkusz kalkulacyjny VisiCalk a potem Lotus 123 (1979). Czy pomagają? Szybo się okazało, że tak zwany biznes po prostu przenosi do tych narzędzi to co i jak robi “na papierze” bez zastanawiania się czy to ma sens. Dzisiaj to zjawisko nazywamy “eksceloza” i nie przypadkiem ma to słowo charakter pejoratywny.
Czy zlecanie dedykowanego oprogramowania jest lepsze czy gorsze od LCNC? Niestety to w zasadzie to samo bo 99% deweloperów pracuje metodami opartymi na pracy pod dyktando przyszłego użytkownika. Dlatego inżynieria oprogramowania to przede wszystkim profesjonalna analiza problemu i projektowania rozwiązania. To jakimi metodami i w jakiej technologii powstanie ta implementacja powinno był wyłącznie konsekwencją czasu i kosztu implementacji.
Rozpoczynanie projektów od wyboru narzędzia to umowy, w których ogon macha psem.
Aplikacja
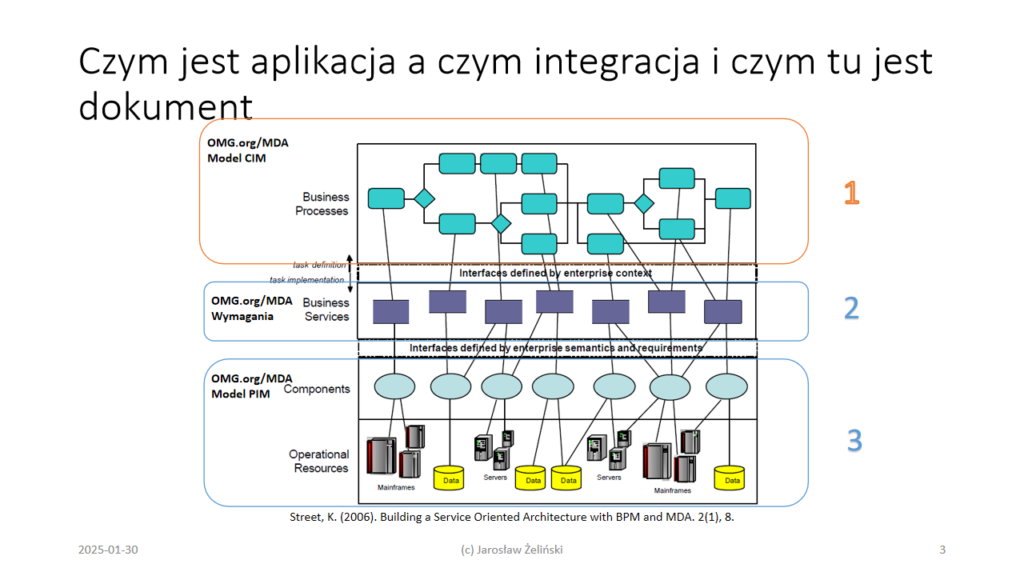
Powyższy diagram można w różnych formach spotkać u wielu autorów [zotpressInText item=”{5085975:K6RYSL8X}”]. To tak zwana architektura SOA: ang. Service Oriented Architecture, czyli Architektura Zorientowana na Usługi, i nie jest to architektura oprogramowana a architektura organizacji. Diagram pokazuje to co dzisiaj nazywamy “Architektura Korporacyjna” (ang. Enterprise Architecture) albo “Target Operating Model” [zotpressInText item=”{5085975:XD2JXZXK}”].
Do czego nam ta architektura? Projektowanie tak zwanych robotów programowych to nic innego jak projektowanie aplikacji/usług, które one potem realizują, lub koordynują. Roboty automatyczną komunikację miedzy aplikacjami na trzecim poziomie. Takie roboty to najczęściej skrypty integracyjne: pobierają i zapisują dane z serwerów wg. ustalonych reguł. Bywa, że dane te są dodatkowo przetwarzane. Jeżeli jest to tylko przenoszenie danych, roboty te mogą być “budowane” jako usługi aplikacji integrowanych (patrz artykuł Integracja ERP oraz Czym jest webhook).
Kluczem do projektowania robotyzacji nie jest analiza tych aplikacji a analiza procesów biznesowych (warstwa 1 na powyższym diagramie) bo tam jest kontekst. Warto też nie zapominać, że dynamicznie generowane, z pomocą poleceń SQL, raporty z baz danych, to nie są dokumenty, a to dokumenty są przetwarzane w organizacjach:
Za trwały nośnik można uznać m.in. dokument papierowy, kartę pamięci, pendrive, wiadomość mailową lub załączony do niej plik, np. w formacie pdf. Samo hiperłącze przekierowujące na stronę internetową nie spełnia wymogów trwałego nośnika, jeżeli tego rodzaju strona internetowa nie spełnia cech trwałego nośnika. (https://uokik.gov.pl/zwrot-i-rekompensata-od-mpay-i-revolut-bank-uab)
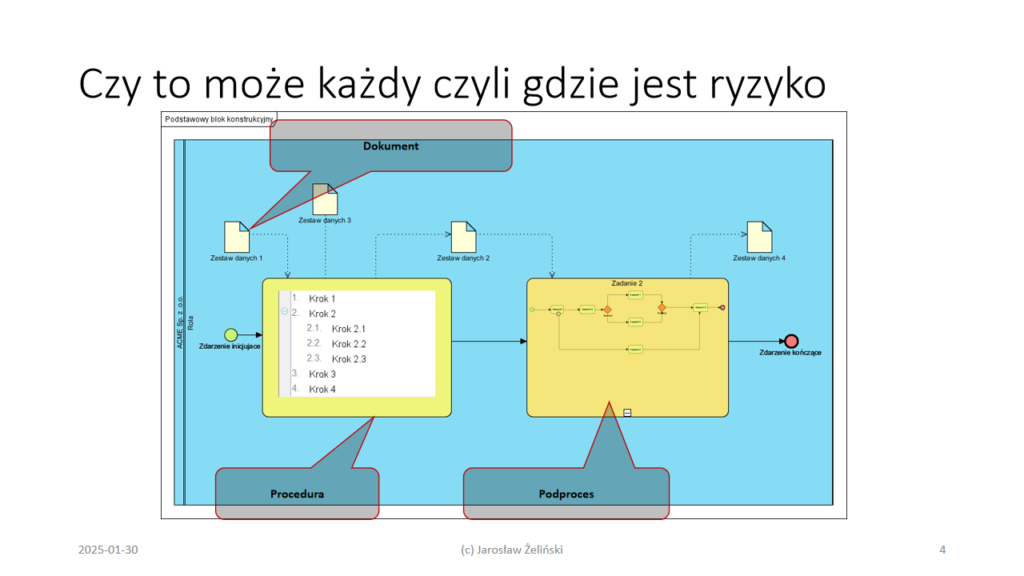
Modele procesów biznesowych czyli dokument i procedura
Kluczem do “robotyzacji procesów biznesowych” są modele tych procesów. Poprawnie opracowane modele procesów pokazują dokumenty, aktywności i procedury (zadanie na modelu procesów w BPMN to nazwa procedury, patrz artykuł Procesy a procedury). Planowanie robotyzacji polega na:
analizie i opracowaniu sformalizowanych modeli procesów bizneowych,
wskazaniu i testowanie miejsc możliwych do automatyzacji: to są miejsca dla których wykażemy, że nie istnieją w nich wyjątki,
opracujemy scenariusze, przetestujemy je na modelach, przekażemy do implementacji.
Kluczowe błędy robotyzacji
Podstawą i celem istnienia “systemów informatycznych” jest przetwarzanie danych niosących informacje: komputer nie przetwarza informacji tylko dane wg. ustalonych reguł [zotpressInText item=”{5085975:ZCXJ2S7U}”]. Przetwarzanie informacji jest cechą ludzi i ich mózgów [zotpressInText item=”{5085975:LCAP9JJ4},{5085975:D54YCRZ2}”].
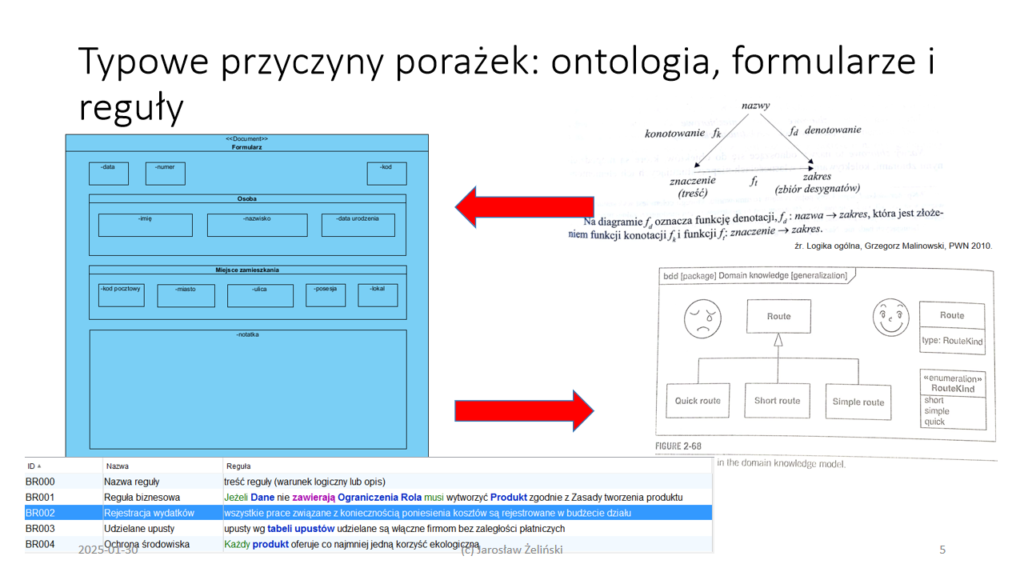
Dlatego planowanie robotyzacji wymaga opracowania wspólnej dla całej organizacji ontologii, czyli wspólnego spójnego słownika pojęć. Powodem jest to, że formularze (ich nazwy, nazwy pół i ich wartości) oraz reguły ich przetwarzania, to słowa. Słowa te wszędzie muszą oznaczać to samo albo żadna integracja i robotyzacja nie będzie możliwa do efektywnego przeprowadzenia.
Podsumowanie
Po prawej stronie przywoływana na początku referatu “Architektura Korporacyjna” (ang. Enterprise Architecture) zwana także “Target Operating Model” [zotpressInText item=”{5085975:XD2JXZXK}”]. Nasze żywe, istniejące organizacje to ta najniższa warstwa. To co jest nam potrzebne do planowania wszelkich wdrożeń to warstwa środkowa: procesowy i informacyjny model organizacji. To tu można znaleźć obszar do automatyzacji, przetestować pomysł (proof of concept), opracować jego ostateczną postać, i dopiero zlecić implementację.
Bardzo ważną rzeczą jest prowadzenie etapu analizy i projektowania po swojej stronie (zbudowanie kompetencji w firmie lub ich wynajęcie), by uniknąć uzależnienia od dostawców systemów. Posiadanie praw majątkowych do dokumentacji metod, scenariuszy i algorytmów robotyzacji-automatyzacji, daje z automatu prawa do kodu, i jest kluczowe dla zarządzania własnym know-how.
Od kilku już lat jestem, jako ekspert, angażowany jako rzeczoznawca do sporządzania opinii na zlecenie sądów (opinia biegłego) lub jednej ze stron sporu (opinia prywatna). Są to spory dotyczące nieudanych dostaw i wdrożeń oprogramowania, nie tylko ERP, bardzo często także dedykowanego.
Po tych latach wyłania się pewien wspólny mianownik, łączący te porażki scenariusz:
firma dostaje ofertę na dostarczenie i wdrożenie oprogramowania,
ma miejsce prezentacja pomysłu, jakieś makiety, jakaś działająca funkcjonalność,
przedmiotem oferty jest prezentowane istniejące oprogramowanie z obietnicą jego dostosowania (kastomizacji), lub oferta wykonania dedykowanego oprogramowania,
projekt przyjmuje formę umowy T&M, podane są stawki wykonawcy,
prawa autorskie (osobiste i majątkowe) do tego co powstaje w toku projektu, są “z zasady” należne wykonawcy, z możliwością przekazania praw majątkowych zamawiającemu (często za dodatkową opłatą),
prawnicy obu stron nie mają do powyższego żadnych zastrzeżeń, skupiają na formalnościach: zawarcie umowy, jej rozwiązanie, przekazanie praw majątkowych do kodu, warunki płatności itp… w zasadzie nic co dotyczy przedmiotu umowy, bo nie istnieje opis przedmiotu umowy (nie licząc licencji na standardowe oprogramowanie i ogólnego celu zamawiającego),
początek projektu, szybko powstaje (albo jest gotowe) tak zwane MVP (Minimum Valuable Product), zamawiający nabiera zaufania do dostawcy, uwierzył w zwinne projektowanie,
kolejne funkcjonalności zaczynają nastręczać problemów, ale wszyscy są dobrej myśli, zamawiający zaczyna coraz częściej słyszeć, że to on jest problemem bo zmienia wymagania i wierzy, że to on jest powodem problemów, dostawca mówi że tak (długo i drogo) ma być to biznes się zmienia i trzeba płacić,
zależnie od cierpliwości zamawiającego, zaczyna sie eskalacja problemu, w zasadzie nic nie jest tak jak powinno być, zamawiający zaczyna ponosić straty,
zamawiający wstrzymuje płatność za ostatnią fakturę (z powodu umowy T&M, poprzednie są już w praktycznie nieodzyskiwalne), zaczyna sie spór, zaczynają zarabiać kancelarie prawne, często te same, które wspierały projekt na etapie zawierania umowy.
Mityczne MVP?
Co jest problemem wielu firm? Zarząd, który nie ma pomysłu na rozwój. Czy musi go mieć? Nie, może zaangażować analityka, który opracuje model działania organizacji i wskaże na nim możliwe usprawnienia. Jednak wielu nie robi tego wierząc, że dobrym pomysłem jest już samo rozpoczęcie metodą prób i błędów.
Generalnie więc powodem problemów jest zupełny brak pomysłu na to czym ma być rozwiązanie, a sam problem jest zarysowany ogólnie i często do końca niezrozumiany. Mimo to obie strony – firma i deweloper – są pełne zapału.
Jednym z typowych argumentów deweloperów na etapie ofertowania i prezentowania “metodyki pracy” jest mityczne MVP, często prezentowane jak poniżej:
Rysunek ten, w tej i podobnych wersjach krąży po stronach WWW deweloperów i jest chyba jednym najbardziej manipulacyjnych i nieprawdziwych schematów. Deweloperzy często argumentują, że ścieżka dolna jest długa i kosztowna, trzeba płacić i długo czekać na ostateczną wersję produktu, bo najpierw trzeba ponieść koszty projektowania, a do tego czasu “nic nie ma”. Sugerują, że szybko coś przydatnego dostarczą (MVP). W czym problem?
W tym, że:
faktycznie rozwiązaniem problemu (potrzeba biznesowa) jest ostatnia pozycja po prawej,
wszystkie kolejne pośrednie urządzenia powstają na koszt zamawiającego, są odrzucane (nie spełniają wymagań) a realnie w niczym nie pomagają, no bo rozwiązaniem (potrzebą) jest ostateczny produkt,
zamawiający nie ma kompetencji (a nie raz nie ma dostępu do kodu) i nie wie, że realnie płaci za kod, który jest zastępowany kolejnym pomysłem, i tak wiele razy, cały czas na jego koszt,
dolna ścieżka realnie, jest znacznie krótsza, bo projektowanie produktu na modelach jest co najmniej o rząd wielkości tańsze i znacznie szybsze, nie realizowane zbędne prace na odrzucanych prototypach,
praktyka pokazuje, że w dniu podpisania umowy zamawiający też nie wie (nie ma pomysłu, koncepcji) co ma ostatecznie powstać, więc generalnie projekt sie toczy bez żadnego planu i kontroli kosztów,
autorzy tego obrazka całkowicie pominęli fakt, że dzisiejsze aplikacje, podobnie jak ten samochód, w 90% powstają z gotowych i dostępnych na rynku komponentów, więc realnie raczej nie wymyślamy koła na nowo.
Tak więc cała powyższa “metoda” to całkowicie nieplanowany, bardzo kosztowny proces z dużym ryzykiem, że nie powstanie nic wartościowego bo braknie czasu i środków. I tak właśnie wyglądają te sporne projekty.
Troszkę teorii: Komponenty i Paradygmat Obiektowy
Paradygmat obiektowy to hermetyzacja i wymiana komunikatów, a nie “dziedziczenie i łączenie funkcji i danych w obiekty”, które jest cechą pierwszych języków obiektowych i stosowanych w nich wzorcach (C++/Java). W zasadzie JavaEE/Spring to framework oparty na antywzorcach (anemiczny model dziedziny, set/get, brak separacji logiki od backendu, patrz artykuł: Ten straszny diagram klas).
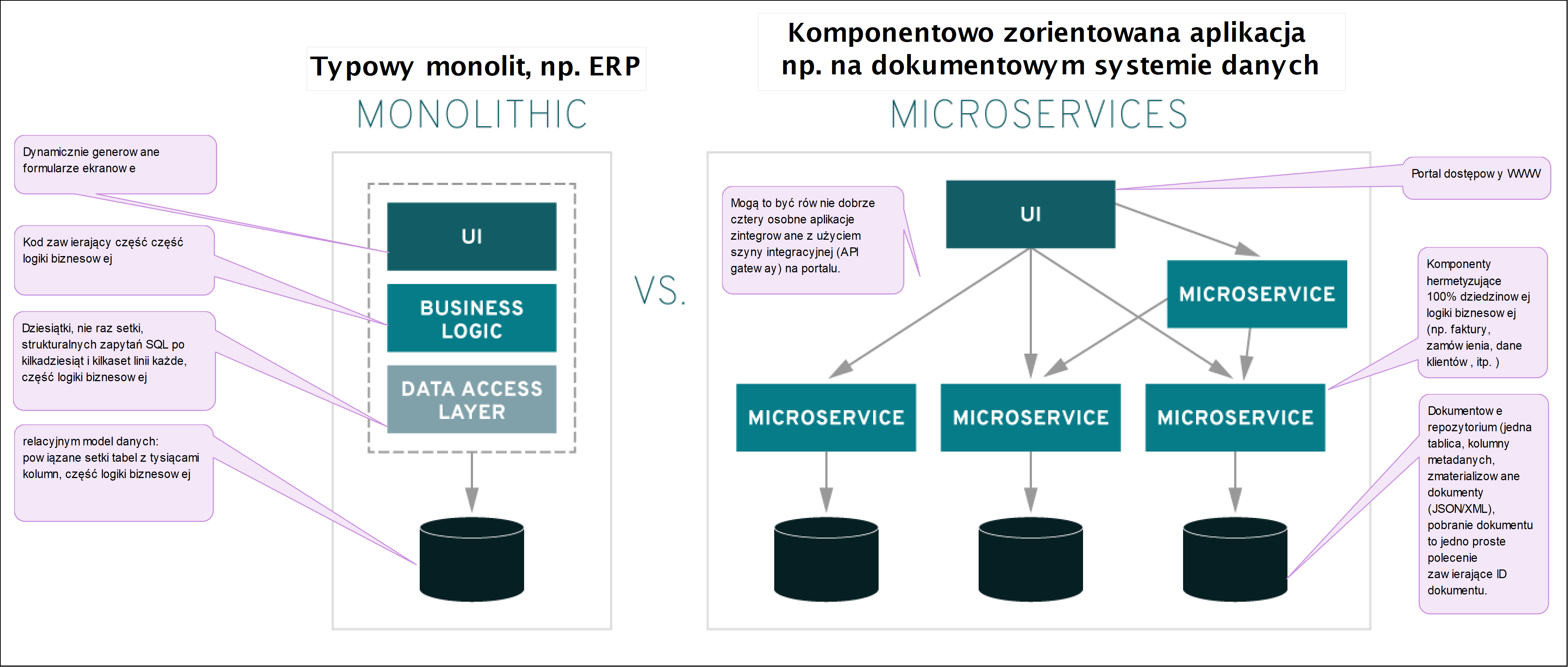
Diagram powyżej pokazuje typową monolityczną architekturę po lewej stronie. Kluczowe cechy monolitu to fakt, że każda zmiana funkcjonalności wymaga refactoringu kodu i migracji danych do nowej, większej bazy o nowej strukturze. Za każdym kolejnym razem jest to trudniejsze i kosztowniejsze. Jeżeli zaś jest to np. kastomizowany system ERP, to praktycznie na większą skalę jest to niemożliwe (dlatego producenci tych systemów odradzają takie podejście, patrz artykuł: Kastomizacja oprogramowania standardowego, aspekty ekonomiczne: Recenzja i rekomendacje).
Po prawej stronie mamy architekturą komponentową, potocznie i powszechnie określaną jako mikro-serwisy, czasami jako mikro-aplikacje. Jest to tak na prawde znana od lat 90-tych architektura komponentowa [zotpressInText item=”{5085975:HPRRUHDL},{5085975:NSJBENX9}”], patrz także [zotpressInText item=”{5085975:SVEGIS7Q},{5085975:6WMWKUT4}”].
Kluczową cechą tej architektury jest wzajemna komunikacja komponentów (integracja) jako wymiana komunikatów, a nie współdzielenie jednej bazy danych (wtedy realnie nadal byłby to monolit). Ta komunikacja to na powyższym diagramie szare linie z grotami. Integracje opisałem w artykule Integracja systemów ERP jako źródło przewagi rynkowej. Projektowanie REST API i scenariuszy. Dzisiaj skupie się tu na wyjaśnieniu jak komunikaty zastępują centralne współdzielone bazy danych.
Współpraca komponentów (obiektów) w aplikacji komponentowej lub zintegrowanym systemie systemów.
Podstawowym elementem komunikacji są komunikaty. Z uwagi na to, że organizacja to system komunikujących się między sobą ludzi, ludzi z komputerami i komputerów między sobą, pojęcia “dokument” i “komunikat” należy uznać za tożsame, gdyż komunikacja człowiek-człowiek, niczym się nie różni od komunikacji człowiek-komputer czy kompoter-komputer [zotpressInText item=”{5085975:DQ85BDLN}”].
Powyższy schemat to przykład współpracy kilku komponentów: każdy z nich wykonuje jakieś czynności, są one inicjowane otrzymanym komunikatem, wynik działania także jest przekazywany jako komunikat. Każdy z tych komponentów może przechowywać historie tych komunikatów (lokalne repozytorium komponentu). Takie komunikaty mogą zawierać różne treści, nie raz nadmiarowe z perspektywy jednego komponentu, ale zawsze spójne kontekstowo. Bardzo często w systemach występują komponenty, których celem jest kolekcjonowanie danych, a odbywa się to po prostu jako zbieranie określonych komunikatów (dokumentów).
Np. faktura to dokument/komunikat niosący dane o dokonanej transakcji. Jest on nośnikiem danych dla działu księgowości, dla klienta, na żądanie dla Urzędu Skarbowego, itp.. Mimo tego, że każdy z wymienionych korzysta tylko z części treści faktury, przekazywana jest zawsze cała faktura, bo to upraszcza cały system.
Kluczem jest zrozumienie tego, że komputery przetwarzają i wymieniają dane a ludzie przetwarzają i wymieniają informacje. Sztuką projektowania systemów informacyjnych jest dekompozycja problemu, projektowanie komunikatów (treści dokumentów) oraz zrozumienie i opisanie mechanizmów ich powstawiania i korzystania z nich. Potem pozostaje już tylko implementacja: zbudowanie systemu informatycznego (patrz: Architektura informacji, system informacyjny a system informatyczny w organizacji).
Powyższy diagram pokazuje także, że próba budowania architektury, w której kilka, kilkanaście wymienianych komunikatów miało by być zamienionych na jeden współdzielony stos wszystkich danych, będzie bardzo trudna do zbudowania i jeszcze trudniejsza do wprowadzania w niej zmian.
Podsumowując: każda organizacja i jej otoczenie to “system wymiany danych” a nie “system współdzielenia danych”. Dlatego świat od dawna odchodzi od monolitów na rzecz komunikujących sie komponentów (mikro-serwisy, mikro-aplikacje, komponenty). Budowanie wspólnego, centralnego modelu danych dla wielomodułowych systemów w zasadzie nigdy nie miało sensu ani szans powodzenia:
Dlaczego problemy pojawiają sie “dopiero później”, na początku było dobrze i klient był zadowolony
Paradoksalnie wyjaśnienie jest dość proste: u deweloperów nadal dominują metody oparte o monolityczne architektury. Głoszenie stosowania “obiektowych metod programowania” oznacza tylko tyle, że zastosowano tak zwany “obiektowo zorientowany język programowania”, co absolutnie nie oznacza, że architektura tego co powstanie będzie nowoczesna. Praktyka audytów pokazuje, że raczej będzie to skansen architektoniczny oparty o relacyjny model danych, wielopoziomowe dziedziczenie i najgorsze praktyki modelowania danych jakimi są anemiczny model dziedziny i płytkie płaskie klasy z ogromna liczbą operacji (w tym set/get dla każdego atrybutu klas reprezentujących tabele bazy danych, patrz artykuł: Ten straszny diagram klas).
Dlatego ten scenariusz często wygląda tak, że na początku powstaje oprogramowanie realizujące jedną określoną funkcję, to często zarodek monolitu. Wszystko ładnie działa, klient się cieszy, zawiera (przedłuża) umowę. Kolejne funkcjonalności to początek dramatu: rozbudowa monolitycznego modelu danych, migracje ze starego modelu do nowego, narastające problemy monolitycznej architektury: wszystko się sypie bo wszystko zależy od wszystkiego, i nie wiadomo jak, bo nie ma żadnej dokumentacji mechanizmu działania aplikacji, zaś kod od dawna nie nadaje się już czytania. Próba naprawy tego też zaczynam być gonieniem króliczka…. i jest spór.
ZARZĄDZANIE PROJEKTEM WE WŁASNYM ZAKRESIE JEST KRYTYCZNE: Integratorzy systemów mogą być cennym elementem cyfrowej transformacji, ale nigdy nie powinni mieć całkowitej, niekontrolowanej władzy nad całym przedsięwzięciem
Dług technologiczny to coś o czym mało się pisze i mówi, a prawie każdy się z nim boryka. W dużym uproszczeniu to jak zmywanie naczyń: jeżeli robimy to regularnie po każdym posiłku, to zajmuje to góra kilkanaście minut a do wykonania wystarczy ściereczka. Jeżeli jednak uznamy, że zmyjemy naczynia dopiero jak „statki” w zlewozmywaku zasłonią okno kuchni :), to nie tylko jednorazowo stracimy znacznie więcej czasu, ale dodatkowo zafundujemy sobie walkę z zaschniętym tłuszczem i resztkami jedzenia, dlatego – co ciekawe – czas i wymagane „środki” potrzebne na rzadkie pozmywanie tej góry nagromadzonych naczyń, są zawsze większe niż suma nakładów pracy na częste drobne zmywanie. Zmywanie naczyń to nielubiana a konieczna czynność. Z technologią w firmach jest bardzo podobnie: postęp techniczny i ewolucyjne zmiany w firmach, są jak narastająca liczba brudnych naczyń: prędzej czy później będziemy musieli to uporządkować (nadrobić) – albo wyrzucić i kupić nowe. Jedno i drugie kosztuje sporo. Dotyczy to w jednakowym stopniu aktualizowania zakresów obowiązków, dokumentacji tego jak firma pracuje, analiz i projektowania, dokumentacji architektury IT jak i upgrade’ów oprogramowania.
W artykule pisałem głównie o technologii. Dług technologiczny, jak każdy dług – prędzej czy później – wymaga spłaty. Co się dzieje gdy nie spłacamy długów? Zaczyna się tak zwana spirala zadłużenia, która w wielu przypadkach kończy się krachem. W inżynierii jest tak samo: przychodzi moment, gdy dług przekroczy wartość zasobów zadłużonego. Innymi słowy koszt aktualizacji poziomu technologii do aktualnego wymaganego, może przewyższyć możliwości organizacji.
Dzisiaj powiemy co nieco o innym i gorszym długu: o długu informacyjnym (information depth).
Dług Informacyjny
Dług informacyjny, jako pojęcie, pochodzi z teorii transmisji danych:
Dług informacyjny, wprowadzony przez Martiniana, jest miarą dodatkowych symboli kodowych potrzebnych w dekoderze do zdekodowania wszystkich nieznanych symboli wiadomości.
[zotpressInText item=”{5085975:DPE2ND8L}”]
Innymi słowy poprawne odkodowanie przesłanych informacji wymaga kompletu brakujących danych w nadanym ciągu kodowym, musimy skompletować wszystkie zaległe i nieodebrane dane. Jak sie to ma inżynierii?
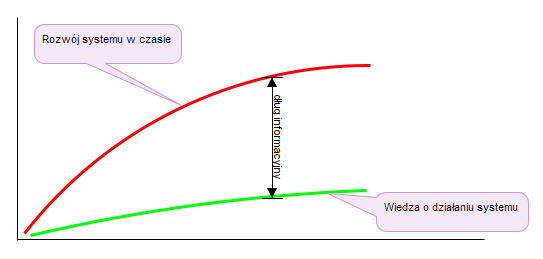
Długiem informacyjnym w organizacji i zarządzaniu nazywamy różnicę między posiadaną (czyli udokumentowaną) wiedzą o tym jak określony system działa, a tym jak on faktycznie działa. Najprostszą metodą zaciągania długu informacyjnego jest budowa i rozwijanie systemu bez równoległego dokumentowania podjętych decyzji na temat tego jak ma działać, a potem jak faktycznie działa. Tym systemem może być zarówno cała organizacja, jak i jakiś jej podsystem, np. informatyczny. Obrazowo wygląda to tak:
Rozwój systemu i wiedza o nim w czasie (opr. własne autora)
Jeżeli firma planuje wdrażanie zmian, w tym np. wdrożenie nowego systemu informatycznego, pojawia się problem niwelowania długu informacyjnego i jego koszt: musimy w krótkim czasie uzupełnić brakującą wiedzę. Nazywamy to często analizą biznesową, analizą przedwdrożeniową itp.:
Analiza Biznesowa jako uzupełnianie wiedzy o organizacji jako spłata długu informacyjnego (opr. własne autora)
Niestety bardzo często, po wykonaniu tej analizy i zakończeniu wdrożenia, w organizacji zaczyna się proces narastania długu informacyjnego. A bardzo często ten proces zaczyna się zaraz po zakończeniu tej kosztownej analizy i rozpoczęciu wdrożenia, bo dostawca systemu nie dokumentuje efektów swoich prac (a powinien).
Rysunek (a) pokazuje typowe dla inżynierii systemów inwestowanie w przyszłość (, polegające na projektowaniu (czyli także dokumentowaniu) poprzedzającym implementacje już na wczesnych etapach życia projektu, wtedy gdy mamy niższe skumulowane koszty. Większość przyszłych kosztów projektu zostanie poniesiona w wyniku decyzji o charakterze inżynierii systemów i będą to już relatywnie niskie koszty, gdyż “wiemy wszystko” by podejmować kolejne decyzje o rozwoju systemu. Jest to jeden z tradycyjnych argumentów za inwestycjami w inżynierię systemów na wczesnym etapie.
Rysunek (b) dodaje koncepcję długu informacyjnego, który jest jeszcze nie wygenerowaną informacją niezbędną do dostarczenia i potem utrzymania systemu. Wykres ten ilustruje trzy różne scenariusze redukcji długu informacyjnego. Istnieją efektywne koszty “odsetek” płacone przez projekty, które nie spłacają swojego długu informacyjnego wystarczająco wcześnie, a im wyższe ryzyko, tym większej “kary odsetkowej” należy się spodziewać. Scenariusz 3 na Rysunku (b) ilustruje przypadek szczególnie niepokojący dla tradycyjnych inżynierów systemów rozważających metody zwinne: Czy Manifest Agile oznacza, że projekt zakończy się z pozostałym długiem informacyjnym, pozostawiając nas z “działającym systemem”, ale długiem informacyjnym: “ciągłą “karą odsetkową” spowodowaną brakiem potrzebnych informacji?
Rysunek (c) ilustruje, że informacje dotyczące inżynierii systemów (np. wymagania, architektury projektowe, oceny ryzyka itp.) wypracowane i dokumentowane wystarczająco wcześnie w projekcie, to inwestycja zmniejszająca dług informacyjny wystarczająco wcześnie a nawet całkowicie.
Obserwowana jest obawa społeczności agile, że odgórne generowanie dokumentacji, które kojarzą z inżynierią systemów, może wiązać się z własnym ryzykiem: podważaniem “sprzedanej” idei agile, a także ryzyku polegającym na zbyt późnym odkryciu nieporozumień dotyczących potrzeb i oczekiwań interesariuszy, skuteczności podejść projektowych itp. Obie te obawy są uzasadnione i potrzebne są obiektywne środki, aby znaleźć właściwy środek – taki jest cel koncepcji długu informacyjnego. Zmusza nas to do podjęcia decyzji, jakie informacje są naprawdę wymagane w każdym kolejnym cyklu życia systemu [zotpressInText item=”{5085975:BQSPVYK2},{5085975:5GGEM7XV}”].
Podsumowanie
Dług informacyjny jest znacznie groźniejszy niż dług technologiczny. Same zaległości technologiczne jako takie można usunąć bez dużego ryzyka: jest to po prostu upgrade już posiadanej infrastruktury. Dług informacyjny jest znacznie bardziej niebezpieczny, bo to całkowity brak wiedzy o tym jak to zrobić bezpiecznie i co w ogóle zrobić (upgrade czy jednak wymiana systemu na nowy inny).
Dług informacyjny to nie tylko nieudokumentowany system. To nieudokumentowane procesy biznesowe, procedury, reguły biznesowe, to zasoby wiedzy o organizacji jedynie w „głowach pracowników”, te zaś są najczęściej niespójne, niekompletne i bardzo często sprzeczne.
W takiej sytuacji każda istotna decyzja wymaga ogromnego wysiłku (czas i pieniądze) by minimalizować ryzyko błędu z powodu niewiedzy. Jak wspomniano wyżej na przykładzie Lockheed Martin, od wielu lat ma miejsce rewizja sensu podejścia zwanego „agile”, które dając nie raz faktycznie szybkie pierwsze efekty, wpędza jednocześnie organizacje w ogromne koszty spłaty długu informacyjnego w przyszłości, z reguły wielokrotnie większe niż „szybkie oszczędności” uzyskane na początku.
Strategie MVP (Minimum Viable Product) czy Quick Wins (szybki sukces na początku) to sukcesy na pokaz, mszczą się długiem spłacanym z dużą nawiązką, najczęściej już po odejściu sowicie opłaconych konsultantów, którzy te strategie polecali.
Zanim napiszę dlaczego prawnik to świetny analityk biznesowy, opiszę problem jaki jest do rozwiązania. O prawniku będzie w drugiej części.
Od ponad 20 lat prowadzę analizy biznesowe, projektuję informatyczne systemy przetwarzania danych, zarządzające przepływem informacji. Obserwuję stały postęp narzędzi oraz rozwój metod prowadzenia analiz, ale także brak (ale nie w 100%) postępu w uzyskiwanych efektach [zotpressInText item=”{5085975:D7P3QCSP}”]:
Czemu tak sie dzieje? Metody realizowania projektów przez większość dostawców IT nie zmieniły sie od 30 lat: rozmowy, wywiady, kodowanie, kosztowne narzędzia (C++, Java). Od 20 lat wiemy, że napisanie programu w C++/Java to dwukrotnie większa pracochłonność w porównaniu do identycznego efektu uzyskanego językami skryptowymi [zotpressInText item=”{5085975:34FM6E6Z},{5085975:HJESQZTY}”]. Stała popularność C++/Java ma swoje źródło: większość dużych systemów w branży fin/tech powstała w latach 90-tych, nie są unowocześniane a jedynie uzupełniane są o kolejne funkcjonalności mimo, że nie jest tajemnicą jak dokonać migracji do nowszych techniologii i architektur [zotpressInText item=”{5085975:GLLQAIV8}”].
Powody są dość prozaiczne: dopóki jest popyt, dostawcy technologii nie mają żadnego interesu w unowocześnianiu swoich produktów i sprzedają permanentny dług technologiczny [zotpressInText item=”{5085975:J24HY9A9}”].
Skąd się u wielu użytkowników technologii IT bierze dług technologiczny już w momencie podpisania umowy na wdrożenie? Stąd, że zlecono analizę przedwdrożeniową wymagań dostawcy technologii, a w jego interesie jest dostarczyć to co ma, a nie to czego potrzebuje klient.
Dlatego nadal mówi się i pisze, by nie powierzać dostawcom technologii prac nad analizami wymagań i zarządzania wdrożeniami:
ZARZĄDZANIE PROJEKTEM WE WŁASNYM ZAKRESIE JEST KRYTYCZNE: Integratorzy systemów mogą być cennym elementem cyfrowej transformacji, ale nigdy nie powinni mieć całkowitej, niekontrolowanej władzy nad całym przedsięwzięciem
Tak więc pozostaje zrobić to samemu, ale jak? Wiemy też na pewno, że nie jest dobrym pomysłem przeprowadzenie wewnętrznych warsztatów z pracownikami i samodzielne spisanie “wymagań”, gdyż tak powstają najbardziej niespójne i niekompletne opisy wymagań [zotpressInText item=”{5085975:LXK8VA68}”]. Więc jak?
Ideałem jest zaangażowanie zewnętrznego analityka projektanta, z zastrzeżeniem że nie może on być dostawcą systemu. Jest to metoda znana od lat, ale nadal rzadko stosowana z uwagi na to, że “mało kto tak robi”, oraz z powodu powszechnego przekonania, że “dostawca ma lepszego analityka i projektanta” (mimo, że teza taka nie ma żadnego uzasadnienia w faktach [zotpressInText item=”{5085975:D2Z2R2DG}”]). Powodem jest także to, że zaufanie do osób z zewnątrz w wielu firmach jest bardzo małe, co powoduje, że nie każdy zarząd decyduje się na taką współpracę.
Orientacja na artefakty
Jak już wspomniano wywiady z pracownikami dają jako produkt niespójny i niekompletny opis organizacji. Dlatego od wielu lat mówi się, że organizacje doskonale opisują artefakty jakie ona ona wytwarza i to na ich podstawie, a nie na podstawie wywiadów, należy prowadzić analizy i projektować systemy. Czym są te artefakty?
Artefakt to konkretny, możliwy do zidentyfikowania, samoopisujący się fragment informacji, który może być wykorzystany przez osobę prowadzącą działalność gospodarczą do jej prowadzenia. Czasami określamy artefakty jako dokumentację biznesową, a niektórzy ludzie biznesu wydają się preferować tę terminologię. Aby artefakty były przydatne do rzeczywistego prowadzenia biznesu, w przeciwieństwie do abstrakcyjnego modelu do analizy, muszą być rozpoznawalne; to znaczy, muszą zawierać informacje w jednym miejscu. Wszyscy słyszeliśmy zwykłe stwierdzenie frustracji: “Ale ja nie mam tu wszystkich potrzebnych informacji”. Wymagania dotyczące bycia wrażliwym na potrzeby biznesu i samoopisującym się są napędzane bardzo mocno z perspektywy poznawczej właściciela biznesu. Artefakty są traktowane jako jedyna jawna informacja zawarta w biznesie; to znaczy, że jest to zbiór zapisów biznesowych reprezentujących zawartość informacyjną biznesu.
[zotpressInText item=”{5085975:ZR3VT56F}”]
Innymi słowy: artefakty to dokumenty operacyjne i ich treść, przetwarzane i wytwarzane w toku funkcjonowania organizacji, oraz wszelkie ślady i skutki tego przetwarzania.
Podejście skoncentrowane na artefaktach biznesowych traktuje dane jako integralną część procesów biznesowych, a procesy biznesowe i ich operacje definiuje w kategoriach współdziałających kluczowych artefaktów biznesowych (BA, business artifact). Każdy typ BA jest charakteryzowany przez model informacyjny i model cyklu życia. Model informacyjny rejestruje wszystkie istotne z punktu widzenia biznesu informacje o instancji BA w miarę jej przemieszczania się w przedsiębiorstwie. Cykl życia określa wszystkie możliwe ewolucje instancji BA w czasie. Jako przykład BA, rozważmy bank CheckingAccount, który rejestruje wszystkie informacje o koncie od momentu jego otwarcia przez klienta do momentu jego ostatecznego zamknięcia i zarchiwizowania, z cyklem życia rejestrującym wszystkie istotne stany konta, możliwe przejścia, operacje, itp.
[zotpressInText item=”{5085975:Y5V4AZJN}”]
Metody analizy i projektowania oparte na artefaktach są także w literaturze opisywane jako evidence-based system engineering [zotpressInText item=”{5085975:MG2IRJC4}”].
Klasyczna metoda prowadzenia analizy nadal w cenie i nie raz już tu była opisana, a czy jest jakaś alternatywa? Tak! Jest światełko w tunelu!
Prawnik jako analityk
Tak! Od kilku lat eksperymentuję z Regulaminami (regulaminy sprzedaży, świadczenia usług, itp.) jako podstawowymi źródłami potrzeb biznesowych. I okazuje się, że bardzo często stanowią one prawie doskonałą specyfikację potrzeb, na podstawie której można nie raz zaprojektować nawet 80-90% całości systemu! Owszem bywają niespójne regulaminy, ale to się zdarza bardzo rzadko. Najczęściej opracowanie takiego regulaminu zleca się prawnikom, a Ci bardzo skrupulatnie analizują wszelkie obowiązki i ryzyka na każdym etapie realizacji obsługi klientów czy też realizacji zadań wewnętrznych (poza regulaminami obsługi klientów mamy też różne regulaminy wewnętrzne).
W efekcie zamiast pracować z niespójna i pełną sprzeczności (typowe efekty warsztatów i burz mózgów) listą życzeń pracowników organizacji, znaczenie efektywniej pracuje się z Regulaminem. Jeżeli ma powstać sklep internetowy będzie to np. Regulamin Sklepu Internetowego, jeżeli ma postać system CRM doskonały materiałem będzie wewnętrzny Regulamin Obsługi Klienta. Jeżeli ma powstać system zarządzania przepływem faktur kosztowych należy zacząć prace od opracowania Regulaminu Przepływu Faktur Kosztowych (tu raczej dział księgowości będzie wiódł prym).
Przyjęcie założenia, że na podstawie regulaminów można zaprojektować oprogramowanie jest sprawdzone, warunkiem jest: (1) zakres projektu to obszar opisany tymi regulaminami, (2) zakres projektu to obszar administracyjny (obsługa zapytań i zamówień to też ten obszar, nie przypadkiem zwany nie raz back-office), (3) regulaminy nie odnoszą się do (nie zawierają w treści) nazw i cech narzędzi i oprogramowania a jedynie do czynności, reguł ich wykonania i wzorów dokumentów. Ten ostatni warunek jest najważniejszy i niestety często nie jest spełniony, w toku analizy staje rekomendacją do zmiany.
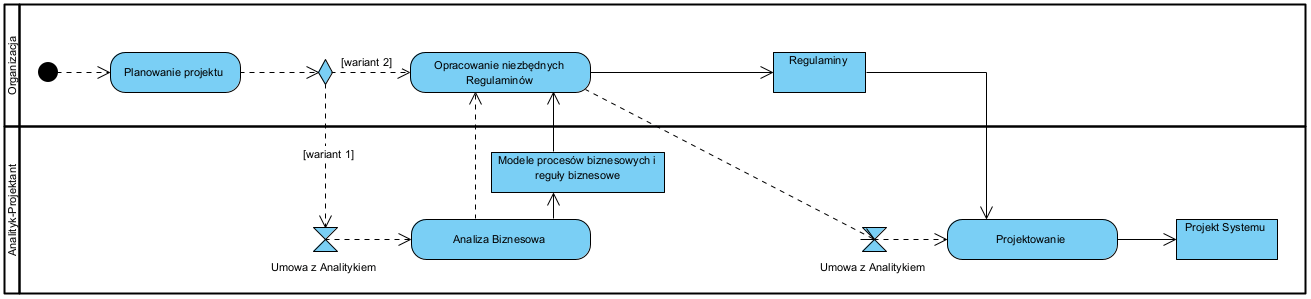
Dwa alternatywne warianty:
Dwa warianty scenariusza opracowania projektu systemu.
Wariant 1 to standardowe podejście: decyzja o projekcie i planowanie i analiza biznesowa. Na podstawie wyników analizy biznesowej i rekomendacji prawnicy (Organizacja analizowana) opracowują Regulamin (usługi, portalu itp.), całość stanowi sobą wymagania i projektowany jest docelowy system. Tu opracowanie Regulaminu polega na wykorzystaniu wyników analizy biznesowej.
Wariant 2 to rzadsze podejście, polegające na wykorzystaniu wcześniej wykonanej pracy nad opracowaniem Regulaminu. To sytuacja w której taki wypracowany Regulamin już istnieje, albo – do czego nie raz zachęcam moich klientów – Regulamin jest opracowany celowo jako element przygotowania materiałów do analizy. Dość często w organizacji jest dział prawny lub ma ona stałą obsługę prawną. Są to osoby znające firmę, i praktyka pokazuje, że mają duża wiedzę o swoim kliencie. Mają też tę zaletę nie są to emocjonalnie związani z firmą jej menedżerowie. Prosze nie zapominać, że pracownicy firmy zaangażowani w proces zbierania wymagań na przyszły system informatyczny są emocjonalnie związani ze swoim obecnym stanowiskiem i dotychczasowym stylem pracy, mają więc pewien konflikt interesu i nie zawsze są obiektywni. Czy to ich zła wola? Nie, to emocje które są ryzykiem projektu, a nie złą wolą tych ludzi.
Podsumowanie
Ścisła współpraca z działem prawnym firmy analizowanej potrafi przynieść duże korzyści. Bardzo często są to ludzie dobrze znający firmę, obyci w opracowywaniu zasad świadczenia usług, reguł postępowania. Regulaminy to dokumenty na dość wysokim poziomie formalizacji, co bardzo pomaga w pracy z nimi. Projektowanie na ich podstawie logiki biznesowej systemu informatycznego jest znacznie łatwiejsze niż na podstawie opisów przygotowanych przez tak zwany “biznes”.
Od kilku lat testuję tę metodę projektowania systemów, w ww. obszarach sprawdza się bardzo dobrze. W czasie prowadzenia zajęć laboratoryjnych ze studentami na kierunku Inżynieria Oprogramowania uczą się oni wychwytywania w Regulaminach sformułowań, które stanowią materiał na słownik pojęć i reguły biznesowe, na aktorów i nie raz nawet na moduły aplikacji. Są to metody oparte na ontologicznych analizach tekstowych [zotpressInText item=”{5085975:2JAV96GM}”]. W połączeniu z metodami opisu reguł biznesowych z użyciem tablic decyzyjnych, stanowią bardzo dobre narzędzie do pracy nad artefaktami jakimi są teksty biznesowe, a regulaminy do takich należą [zotpressInText item=”{5085975:K6WH5VWQ}”].
Przykładowe projekt i analiza na podstawie Regulaminu
Poniżej do pobrania dwa pliki pdf, opracowania wykonane w całości tylko na podstawie Regulaminu.”
[wpdm_package id=’37614′]
Drugi to wynik analizy Regulaminu i rekomendacje do poprawy jego jakości:
Ontologia jako narzędzie tworzenia “modeli świata”, jest bardzo dobrym narzędziem do projektowania danych, zorganizowanych – w łatwe do zarządzania w bazach NoSQL – dokumenty. Niedawno napisałem:
Czy opracowanie ontologii jest łatwe? Nie, nie jest. Czy zła ontologia szkodzi? Tak, potrafi doprowadzić do fiaska projektu informatycznego.
Po co to wszystko? Obecnie często mówimy o Big Data, czyli o masowo gromadzonych danych. Ich gromadzenie wymaga opracowania struktury ich gromadzenia i zarządzania nimi, bez tego powstanie “stos nieskatalogowanych dokumentów”. Proces gromadzenia danych jest stratny, więc dane te można zgromadzić raz, przepisanie ich do nowej struktury jest możliwe tylko gdy nowa struktura jest prostsza (przepisywanie do identycznej nie ma sensu) więc każda migracja to utrata informacji. Innymi słowy: architekt danych, podobnie jak saper, myli się tylko raz.
Ontologia
Przypomnijmy definicję:
ontologia: lista pojęć i kategorii z jakiegoś obszaru tematycznego, która pokazuje związki między nimi
Generalnie, zgodnie z zasadą wyłączonego środka, każde dwa pojęcia mozna połączyć w zdanie albo generalizacją albo predykatem. Kolejna zasada: w poprawnej ontologii, wstawienie w zdaniu, w miejsce pojęcia, jego typu (specjalizacja), zachowuje prawdziwość tego zdania. Trzecia: zdanie tworzą także jedno pojęcie i predykat. Przykłady odpowiednio:
jeżeli “ratler to rasa (typ) psa”
a także “mały pies to także pies”
oraz “pies szczeka na listonosza”
więc “ratler szczeka na listonosza”
także “mały pies szczeka na listonosza”
oraz “pies szczeka”
Wszystkie powyższe zdania to zdania prawdziwe i sensowne w języku polskim. Są to zdania prawdziwe w sensie “tak sią (generalnie) dzieje, że… “, są to fakty jeżeli zdanie jest relacją. Patrz:
W The Philosophy of Logical Atomism Russell pisze: Jeśli mówię „Pada”, to to, co ja mówię jest prawdziwe przy pewnych warunkach pogodowych a jest fałszywe przy innych. Warunki pogodowe, które czynią moje stwierdzenie prawdziwym (lub fałszywym w innym przypadku), są tym, co nazywam faktem” [zotpressInText item=”{5085975:52F4HLJ6}”]
Modelowanie
Wśród wielu znanych metod modelowania ontologii jest OntoUML [zotpressInText item=”{5085975:V8JX39Y2},{5085975:5K34YGSS}”]. Moim zdaniem ma pewne wady: autorzy wprowadzają pojęcie ‘event’ mające takie cechy jak początek i koniec (wartością tych atrybutów jest czas: timestamp). Uważam, że stwarza to pewien problem z klasyfikacją treści takiego komunikatu. Po drugie, jeżeli uznamy, że przestrzegamy zasady “nie lubimy pustych pól” (bazy danych nie zawierają pól/atrybutów bez wartości) to ‘event’ łamie tę zasadę, bo wartość zadeklarowanego pola “end event” będzie pusta do momenty zakończenia “zdarzenia”. Jednym z ciekawszych podejść do ontologii, jej modelowanie i integracją z modelami systemów (MDA, SysML, UML) opisali w swojej pracy Devedzic i inni [zotpressInText item=”{5085975:K6Z5L6JM},{5085975:K2PIVCKQ}”] z czego także tu korzystam.
W publikacji na temat klasyfikacji i jednoznaczności opisu [zotpressInText item=”{5085975:9KMR85JV}”] opisywałem metodę dzielenia informacji wg. kontekstu, jakim jest sklasyfikowanie treści jako opisu obiektu (ten trwa w czasie) oraz faktu (nie trwa w czasie). Zdanie “Dom ma cztery okna i czerwony dach” jest prawdziwe mimo upływu czasu, zawsze będzie wypowiadane w czasie teraźniejszym. Zdanie “w Dom uderzył piorun” jest prawdziwe ale zawsze będzie wypowiadane w czasie przeszłym. Obiekty trwają w czasie, ich stan może się zmieniać: “Po przemalowaniu (fakt) dom ma zielony dach” (i to trwa). Wszystko to co trwa w czasie, jest ograniczane faktami, w szczególności fakt powstania rzeczy (obiektu) i fakt jego “zniszczenia”, w międzyczasie mogą mieć miejsce fakty zmieniające stan rzeczy (obiektu, np. zmiana koloru).
Generalizując: obiekty trwają w czasie zaś fakty nie. Początek i koniec trwania obiektu to dwa kluczowe fakty z “jego życia” (cykl życia obiektu) a nie “event” mający początek i koniec. W “życiu” obiektu mogą wystąpić inne fakty. Cechy obiektu to jego własności (kolor, waga i wiele innych itp.), cechami faktów są moment w czasie (time stamp) oraz to jakiego obiektu (obiektów) dotyczyły.
Ontologia (SBVR, diagram faktów)
W systemach informacyjnych mamy do czynienia z gromadzeniem wiedzy o świecie oraz z gromadzeniem sprawozdań. Powyżej ontologia czyli pojęciowy model wycinka świata. Zdanie “pies szczeka na listonosza” a także “pies szczeka” to ogólna wiedza o psach. Zdanie “listonosz boi się psa” to ogólna wiedza o listonoszach. Sprawozdaniem było by tu zdanie: “mały pies, pudel, szczekał na listonosza od godzony 16:16 do godziny 16:18” (można by jeszcze podać adres).
Ontologia, jako językowy opis świata, to metamodel zdań opisujących pewną klasę obiektów i zdarzeń. Sprawozdanie mówiące, że konkretny pies, w określonym okresie czasu, szczekał na konkretnego listonosza (w konkretnym miejscu) to taka właśnie instancja (wystąpienie).
Projektowanie architektury danych
Jaką architekturę powinien mieć “dokument” będący treścią tego sprawozdania?
Poniżej trzy etapy analizy.
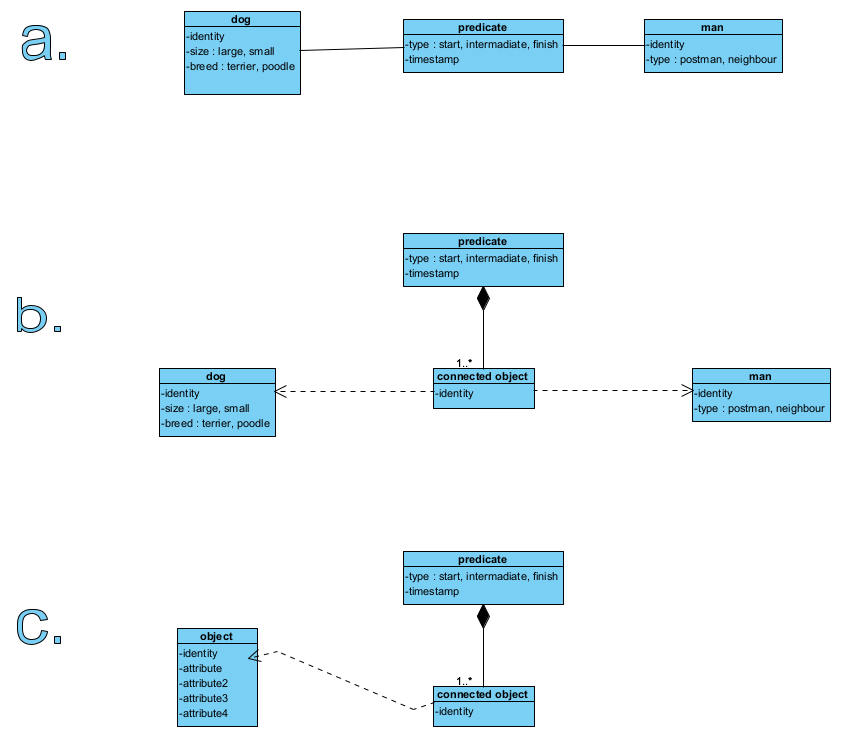
Modele wiedzy oparte na ontologii (diagramy klas, UML, opracowanie własne autora).
Ogólnie można powiedzieć, że predykaty (fakty zdaniotwórcze) dotyczą obiektów: zbieramy informacje (wiedzę) o tym, kiedy pies szczekał na ludzi, jaki pies i na jakich ludzi szczekał. To rysunek a. powyżej, możemy go nazwać koncepcją. Zapisanie takiej informacji wymaga zaprojektowania trzech repozytoriów: pies, człowiek, predykat. Powiązanie psa z człowiekiem jest zapisane jako atrybuty predykatu (rys. b.). To projekt architektury danych i logiki ich wiązania. Bardziej uniwersalny model pokazano na rys. c., wymagał by on uzupełnienia “bazą szablonów obiektów” (struktury agregatów opisujacych różne typy obiektów) z uwagi na to, że różne obiekty mogą mieć różne cechy. Tu pokazano je w uproszczeniu jako atrybuty, jednak realny projekt dziedzinowy były już bardziej precyzyjny i rozbudowany.
Powyższe można zapisać w bazie NoSQL, w w bazie grafowej obiekty były by węzłami a predykaty krawędziami. Detale obiektów mogą być agregatami w bazie dokumentowej.
Rola ontologii w projektach
Kluczową rolą i celem tworzenia ontologii jest wspólny słownik i zrozumienie pojęć. Ontologia pełni rolę centralnej współdzielonej przestrzeni pojęciowej (namespace) i wiedzy dziedzinowej (np. reguły biznesowe). Wszystkie systemy w organizacji (bardzo często od różnych producentów) mają – każdy swój – wewnętrzny i lokalnie spójny system pojęciowy (namespace). Jakakolwiek ich integracja (wymiana komunikatów między systemami) wymaga mapowania synonimów w komunikatach (nazwy pój, ich wartości, robi to adapter, bardzo często jest to implementowane jako szyna integracyjna ESB):.
Zarządzanie systemem pojęć
Podsumowanie
Uważam, że ontologie nie wymagają skomplikowanych metamodeli takich jak ww. OntoUML czy bardziej skomplikowanych, opartych na rozbudowanych taksonomiach i modelu UFO [zotpressInText item=”{5085975:743UXHMB}”].
Gromadzenie wiedzy to albo wiedza “generalna” opisująca świat (właściwa ontologia) albo sprawozdania (opisy), dla których ontologia jest metamodelem (ontologia tu, to metadane sprawozdań). Tak więc możemy powiedzieć, że gromadzenie wiedzy wymaga dziedzinowego (specyficznego dla dziedziny) modelu pojęciowego: ontologii. Na tej podstawie można zbudować model struktury danych. Pokazano, że obecnie najbardziej adekwatny do opisów byłby model dokumentowy, gdyż opisy obiektów będą skomplikowanymi agregatami o zmieniającej się w czasie strukturze, zależnej od typu obiektu, ale też odwzorowującej wiedzę o nim. Predykaty są znacznie prostsze i przechowywanie ich w postaci samych prostych metadanych wydaje się wystarczające. Całość tworzy sieć, w której węzły są obiektami a krawędzie faktami.
Biorąc pod uwagę ogromne ilości zbieranych danych oraz to, że “nie można sie pomylić”, modele SQL/RDBMS, z ich sztywnością i brakiem redundancji, wydają się nieadekwatne. Ontologie jako wiedza o istocie świata (np. w systemach sztucznej inteligencji) bardzo dobrze pasują do baz grafowych. Ogromne ilości danych sprawozdawczych doskonale pasują do baz dokumentowych. Wyzwaniem w projektach tego typu jest zbudowanie dziedzinowej ontologii, a potem zaprojektowanie agregatów (dokumentów) przechowujących dane sprawozdawcze. Przykładem takich agregatów są np. opisy zmieniających się produktów jako obiektów oraz faktury jako fakty dokonania transakcji ich sprzedaży (co, kto komu, za ile, kiedy). Zdanie “Jan sprzedał Krzysztofowi rower” to wiedza o tym, że pewien fakt (moment dokonania transakcji) połączył trzy obiekty: sprzedawcę, nabywcę, sprzedany produkt.
Dalsze prace
Dalsze prace prowadzone są w kierunku stworzenia ogólnej uniwersalnej metody analizy i projektowania systemów zarządzania informacją na bazie ontologii i struktur dokumentowych i wdrażanie ich w systemach zarzadzania informacją zarówno ERP jak AI.
Dodatek
Pojęcia klasy obiektów, klasyfikatora, wartości a także pojęcia reprezentującego obiekty, które mogę reprezentować wartość czego to zbiory, definicje elementów i elementy. Z elementów zbioru, za pomocą predykatów, mozna budować “zdania prawdziwe” czyli opisy. Poniżej ciekawa prezentacja o teorii zbiorów i rachunku predykatów. Bardzo ważna dla zrozumienia tego czym tak na prawde jest analiza pojęciowa.