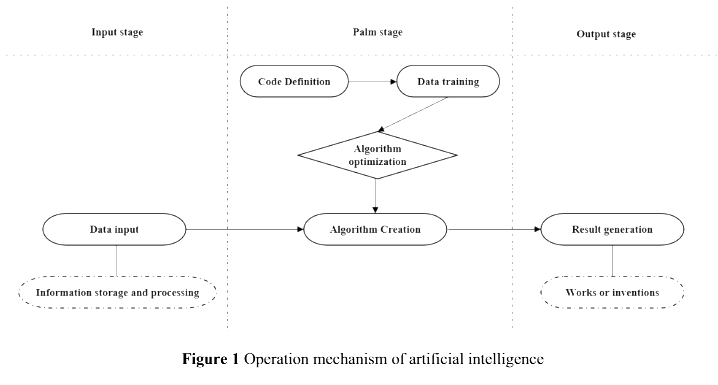
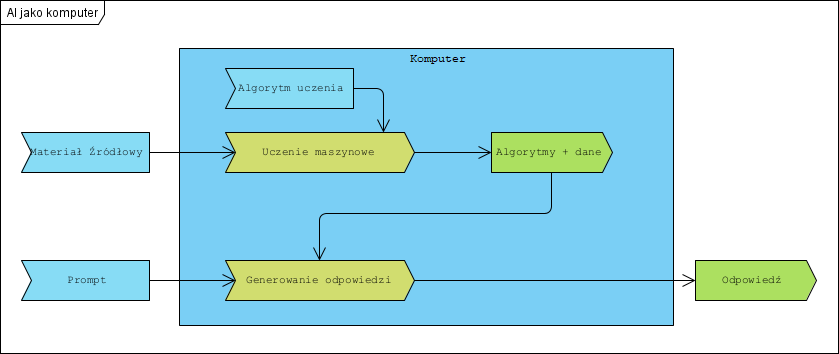
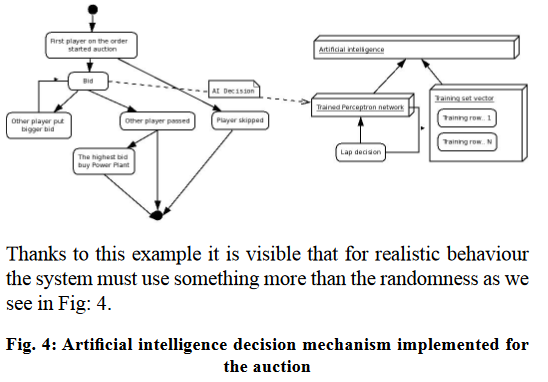
Wprowadzenie
Z zamiarem napisania osobnej publikacji o profilowaniu w UML noszę się od kilku lat. Mamy koniec grudnia, czyli więcej czasu dla siebie, więc nadszedł ten moment.
Notacja UML to prosty graficzny system notacyjny, co niestety powoduje, że modelowanie wielu ludziom wydaje się proste bo “to tylko prostokąciki i strzałki, każdy tak może i potrafi”. Niestety to jest jak pisanie: mamy nieco ponad 20 znaków alfabetu łacińskiego, język i gramatykę, a jednak napisanie czegoś wartościowego nadal jest jednak nie małym wyzwaniem. Nie zmienia to jednak faktu, że przeczytanie cudzego tekstu jest proste, o ile tylko nie jesteśmy analfabetą.
UML to język jak każdy inny. Od języka naturalnego różni go jego formalizm, co w konsekwencji daje obligatoryjną jednoznaczność, co jest podstawowym celem każdej formalizacji. Słownik Języka Polskiego PWN:
sformalizować: nadać czemuś charakter ścisły i wyrazić to za pomocą symboli matematycznych lub innego specjalnego języka
formalizacja: procedura prowadząca do przedstawienia danej teorii lub systemu w postaci sformalizowanej
Tak więc UML to ten “inny specjalny język” pozwalający formalizować modele systemów określonego typu. Opisałem to dokładnie w jednej z recenzowanych publikacji [zotpressInText item=”{5085975:TBT7B5D2}”]. Tu skupie się na samym Profilu w UML: czym jest oraz kiedy i jak go używać.
Profil w UML
W artykule Diagramy w notacji UML (2023) pisałem:
Klasa to podstawowy element modelowania w UML. Służy do modelowania struktur pojęciowych (namespace) lub struktur opisujacych architektury systemów na różnych poziomach abstrakcji. Klasa to nazwany element modelu, klasyfikator to definicja obiektów danej klasy (tak zwana definicja realna) czyli cechy obiektów tej klasy: atrybuty i operacje (rozdz. 9).
W artykule (2023) Model UML i stereotypy jako ikony napisałem:
W UML opracowano prosty system: wszystko jest prostokątem (klasą), znaczenie kształtu jest określane słownie, a słowo to jest wpisywane w prostokąt nad opisem w podwójnym łamanym nawiasie: ‘stereotyp’. Dla ułatwienia posługiwania się notacją, wybrane kluczowe nazwy (stereotypy) dostały swoje ikony np. aktor, przypadek użycia, komponent, interfejs itp..
Tu pada słowo stereotyp. Czym jest stereotyp? Czym jest profil?
Profil jest formą rozbudowy metamodelu, który może być użyty do rozszerzenia notacji UML. Podstawowe narzędzie rozszerzania to Stereotyp. [zotpressInText item=”{5085975:DCYU6XZJ}”]
Czytamy dalej tamże:
12.3.3.4 Stereotypy
Stereotyp definiuje rozszerzenie dla jednej lub więcej metaklas i umożliwia jej użycie jako określonej dodatkowej terminologii.
Formalnie profil w UML to osobny model/diagram. Jest to model pojęciowy: ontologia i taksonomia.
Profil w specyfikacji UML [zotpressInText item=”{5085975:DCYU6XZJ}”]:
12.3 Profil
12.3.1 Podsumowanie
Podrozdział Profile opisuje możliwości, które pozwalają na rozszerzenie metaklas w celu dostosowania ich do różnych celów. Obejmuje to możliwość dostosowania metamodelu UML do różnych platform (takich jak J2EE lub .NET) lub domen (takich jak architektura czasu rzeczywistego lub architektura zorientowana na usługi). Podrozdział Profiles jest zgodny z OMG Meta Object Facility (MOF).
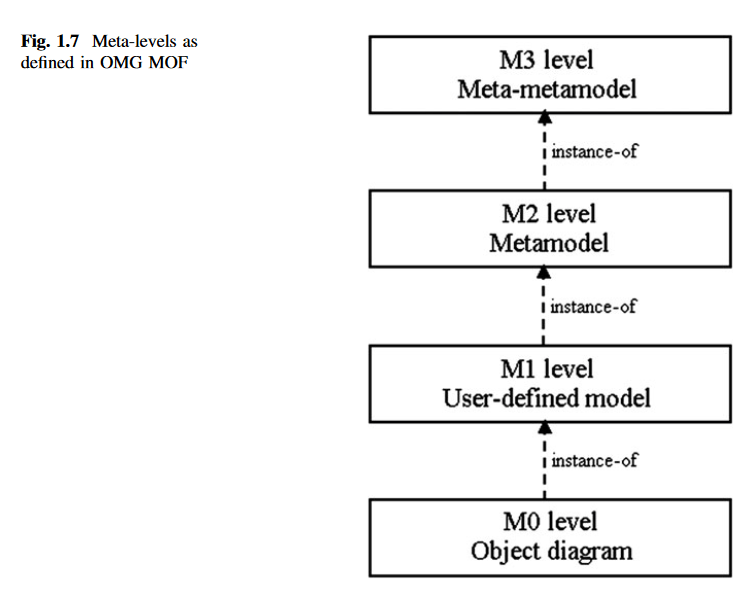
Profil to metamodel dla modelu i budujemy go jako dodatkową warstwę w warstwie M2. Poniżej podstawowe w MOF (Meta Object Facility) poziomy abstrakcji wg MOF:
Profil budujemy jako zestaw pojęć (diagram) połączonych związkami generalizacji i kompozycji. Generalizacja to związek mówiący, że coś jest typem czegoś np. pies jest typem ssaka. Kompozycja to związek mówiący, że coś jest cechą czegoś, np. ogon jest cechą psa bo “pies ma ogon”. Dlatego nie przypadkiem, nawet w języku polskim, stosujemy zamiennie słowo cecha i własność: własnością psa jest to, że ma ogon (= cechą psa jest to, że ma ogon).
Poniżej profil standardowy UML:
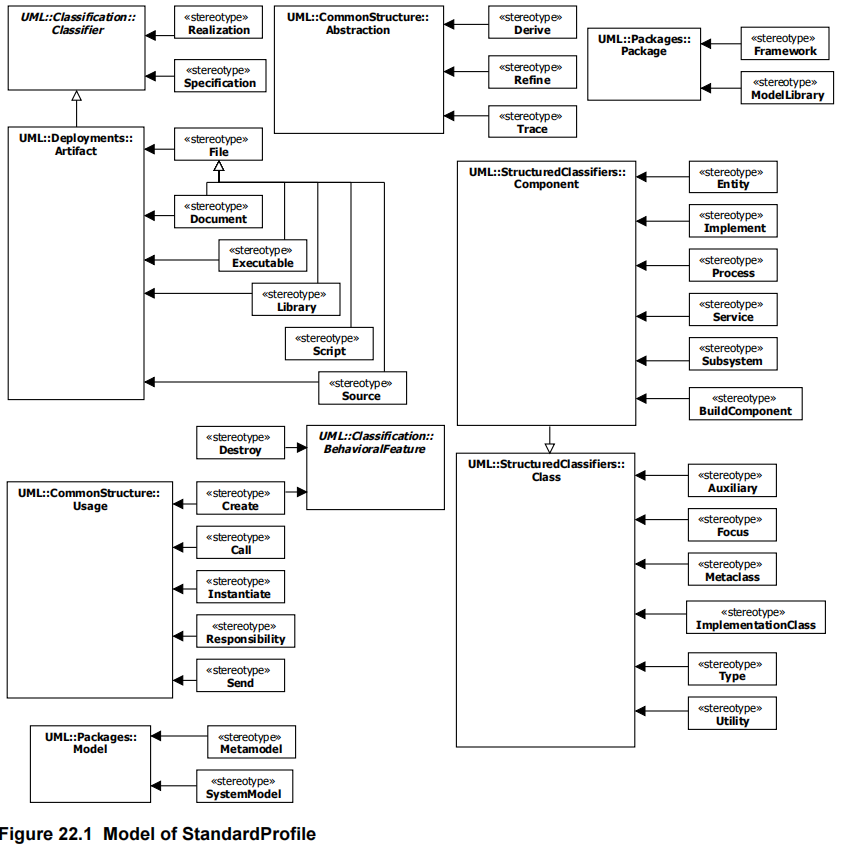
Jak widać w UML wszystko jest klasą. Bazowe pojęcia meta-metamodelu (oznaczone UML::… ), nie są z sobą połączone, to pojęcia stanowiące fundament notacji.
Na diagramach profilu można umieścić pojęcia bazowe abstrakcyjne. Łączymy jest ze stereotypami profilu standardowego linią skierowaną wg. wzoru:

Poniżej wybrane pojęcia Profilu w firmie tabelarycznej (fragment):
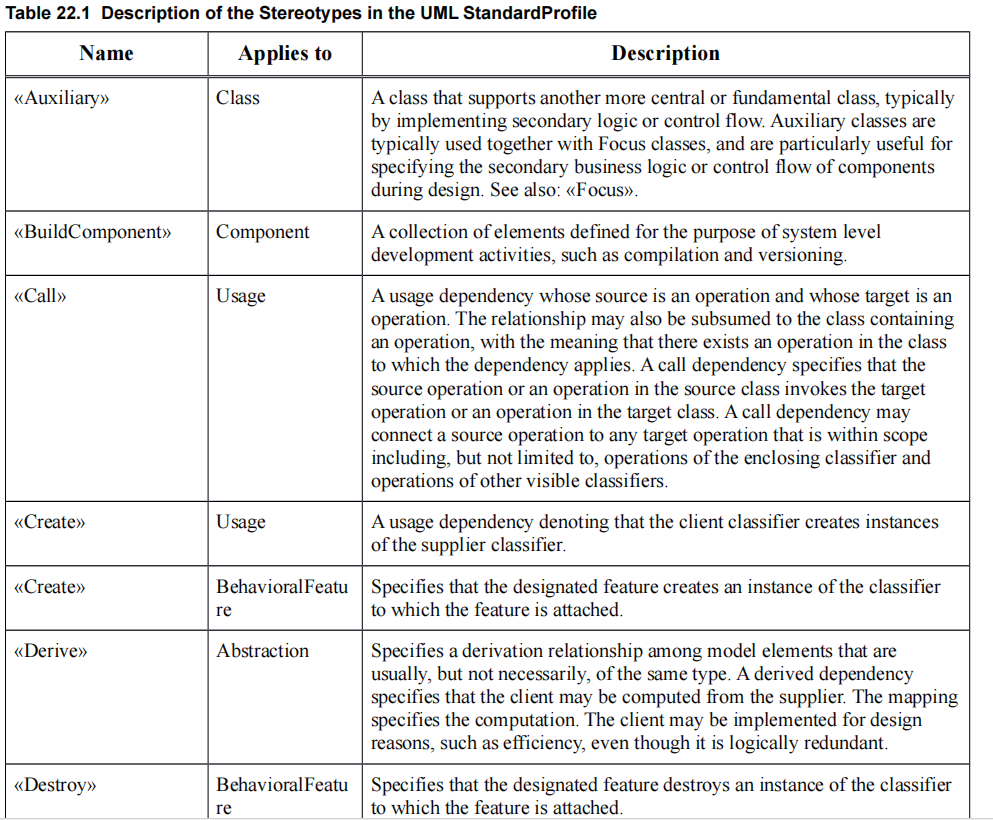
Jak to czytać? Popatrzmy na poniższy fragment:
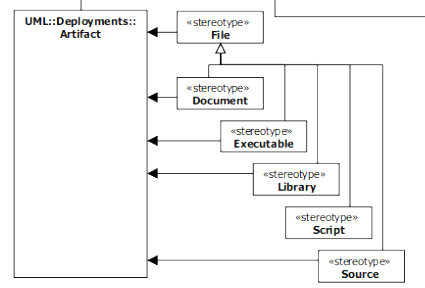
UML::Deployments::Artifact to abstrakcyjne pojęcie “Artifact” (artefakt, w języku angielskim i polskim, oznacza coś, co jest dziełem ludzkiego umysłu i ludzkiej pracy w odróżnieniu od wytworów natury). Rodzajem artefaktu jest File (plik). Wyróżniamy określone typy plików: Document, Executable, itd. Ważna uwaga: robiąc taką taksonomię, używamy na diagramach tylko liści tej struktury (przypominam, że nie jest to dziedziczenie i nie używamy tu abstrakcji).
Document jest definiowany jako:
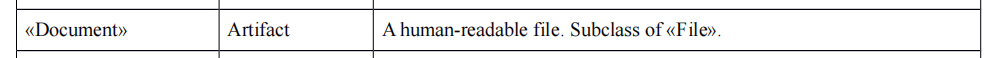
Specyfikacja notacji UML to w zasadzie bazowy (Root) profil plus kontekstowe modele (pozostałe rozdziały) zdefiniowane jako profile. Dlatego mówimy, że notacja UML jest samodokumentująca się (UML został udokumentowany w notacji UML). Poniżej rozdział 7.2.2. zawierający taki profil.
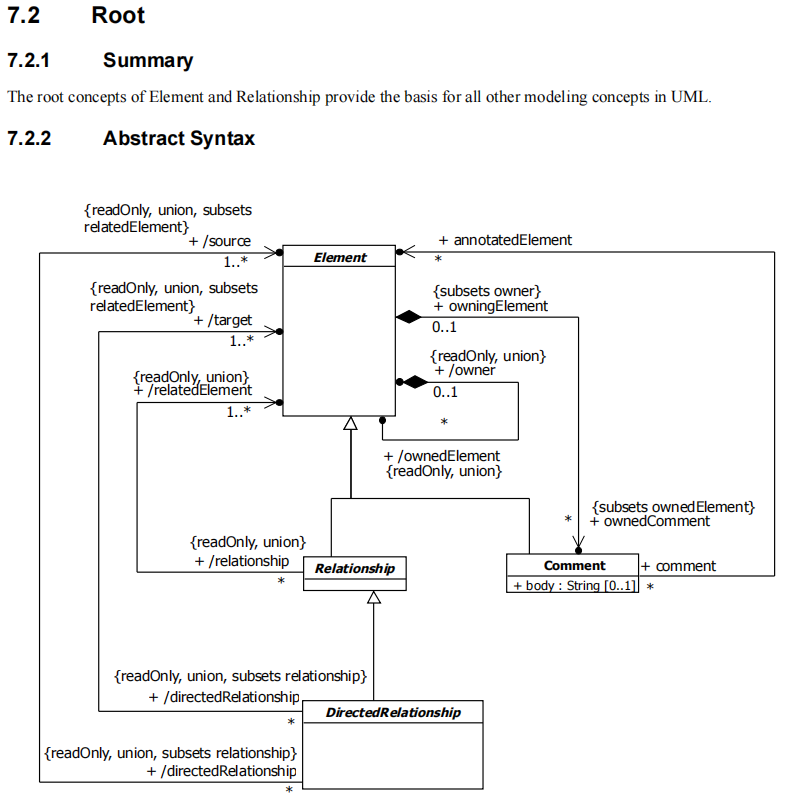
Diagram profilu, wyrażający także składnię, składa się z definiowanych elementów (prostokąt) oraz związków między nimi. Profil to jedyny diagram na którym jednocześnie stosujemy związki pojęciowe (generalizacja) i strukturalne (skierowane asocjacje, głównie kompozycja). Powyższy diagram czytamy:
- semantyka:
- diagramy UML budowane są bazowych elementów tych diagramów,
- specyficznym typem elementu diagramu są związki miedzy elementami bazowymi oraz komentarze,
- specyficznym typem związku jest związek skierowany,
- syntaktyka:
- bazowe elementy mogą być ze sobą łączone z pomocą związków, związek skierowany też jest takim związkiem,
- cechy (własności) elementów bazowych to także elementy bazowe,
- komentarz jest cechą (własnością) elementu bazowego, z którym został skojarzony.
Pozostałe detale tego diagramu pominąłem, gdyż nie są tu istotne i są stosowane opcjonalnie. W logice i lingwistyce pojęcia mogą być definiowane opisowo (definicja sprawozdawcza) lub poprzez cechy (definicja realna) [zotpressInText item=”{5085975:6LD24N2L}”]. UML to notacja, w której obiekty są definiowane z pomocą klas mających własności (cechy: atrybuty i zachowania), są to definicje realne (poprzez cechy).
Elementy składni
Warto pamiętać, że syntaktyka (składnia) notacji w OMG, UML także, jest budowana na wymaganiach (regułach) formułowanych jako:
5 Notational Conventions
5.1 Key words for Requirement Statements
The words SHALL, SHALL NOT, SHOULD, SHOULD NOT, MAY, NEED NOT, CAN and CANNOT in this
specification shall be interpreted according to Annex H of ISO/IEC Directives, Part 2, Rules for the structure and
drafting of International Standards, Sixth Edition 2011
Słowa zapisane kapitalikami to odpowiednio: POWINIEN, NIE POWINIEN, ZALECA SIĘ, NIE ZALECA SIĘ, MOŻE, NIE WYMAGA SIĘ, JEST MOŻLIWE i NIE JEST MOŻLIWE. Te słowa w języku angielskim są dość nieprecyzyjne dlatego powstały formalne zalecenia standaryzujące ograniczające słowa kluczowe wymagań (reguł) do:
- MUST This word, or the terms “REQUIRED” or “SHALL”, mean that the definition is an absolute requirement of the specification.
- MUST NOT This phrase, or the phrase “SHALL NOT”, mean that the definition is an absolute prohibition of the specification.
- SHOULD This word, or the adjective “RECOMMENDED”, mean that there may exist valid reasons in particular circumstances to ignore a particular item, but the full implications must be understood and carefully weighed before choosing a different course.
- SHOULD NOT This phrase, or the phrase “NOT RECOMMENDED” mean that there may exist valid reasons in particular circumstances when the particular behavior is acceptable or even useful, but the full implications should be understood and the case carefully weighed before implementing any behavior described with this label.
(patrz wpis: rfc2119 – Słowa kluczowe reguł)
Nie tylko UML
Powyższy profil standardowy można rozszerzać na użytek np. określonej dziedziny modelowanych systemów. Robimy to (dokumentujemy te rozszerzenia) z pomocą Diagramu Profilu. Z profilami w sposób “niejawny” spotykamy się w każdej notacji OMG.
Fragment dodatku specyfikacji notaci BPMN:
Annex C, Glossary (informative)

Co można zobrazować jako:
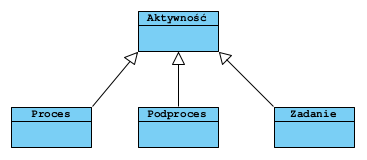
Pojęcie Activity to pojęcie abstrakcyjne w BPMN nie mające graficzne reprezentacji. Graficzną reprezentację mają jedynie Podproces (Sub-process) i Zasadnie (Task):

Przykład 1
Załóżmy, że modelujemy nowe oprogramowanie: Aplikacja Modelowana. Ma ona mieć jednego Użytkownika, będzie współpracowała z dwoma innymi aplikacjami:
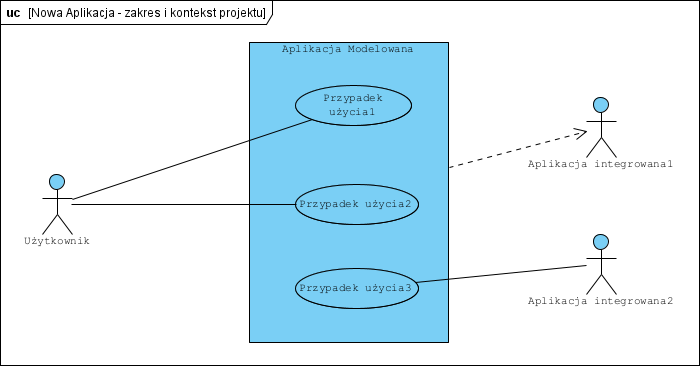
Aktor Użytkownik i aktor Aplikacja integrowana, to identyczne symbole na diagramie, co jest po prostu niejednoznaczne. Jak tę niejednoznaczność usunąć? Tworzymy diagram profilu:
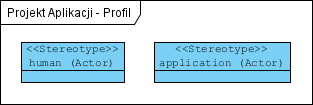
Wiele narzędzi CASE zastępuje nadrzędną “generalizację generalizacji” podawaniem nazwy klasy bazowej UML w nawiasie. Powyższy diagram, po zastosowaniu stereotypów zdefiniowanych w profilu, będzie wyglądał tak:
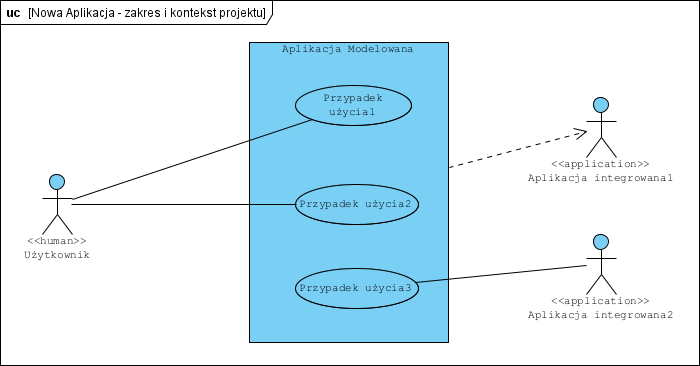
Więcej o tym przykładzie w artykule Dylematy z aktorami. Ważna uwaga: nowe pojęcia powinny być spójne, kompletne i niesprzeczne w ramach modelowanej dziedziny.
Przykład 2
Profile dla architektury HLD:
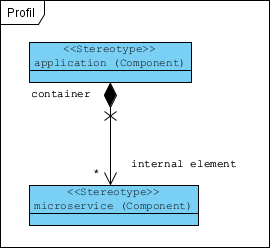
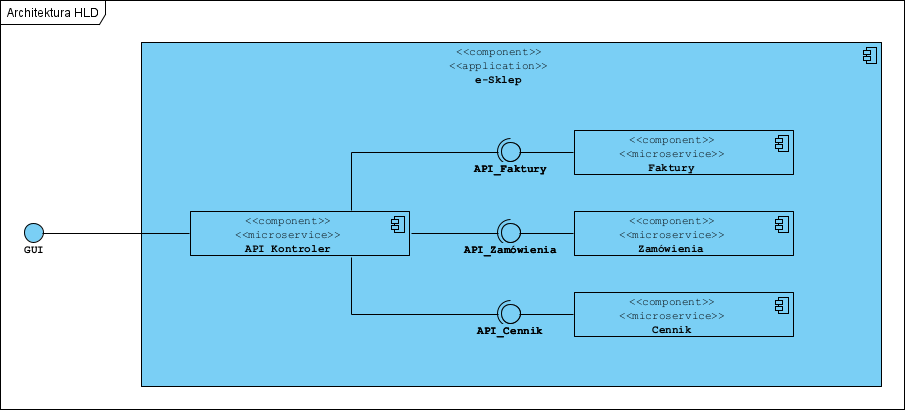
Model architektury zbudowany z użyciem tego profilu:
Podsumowanie
Stereotypów praktycznie nie używamy w modelach pojęciowych, które są z zasady formą profilu. Stereotypów używamy na modelach PIM określonych systemów dziedzinowych, oraz do definiowania tak zwanych frameworków dla modeli PSM (np. profil dla Java czy profil dla .NET):
The Profiles clause describes capabilities that allow metaclasses to be extended to adapt them for different purposes.
This includes the ability to tailor the UML metamodel for different platforms (such as J2EE or .NET) or domains (such
as real-time or Service Oriented Architecture). The Profiles clause is consistent with the OMG Meta Object Facility
(MOF).
Dlatego nie należy tworzyć “nierealnych” bytów takich jak np. krytykowany powszechnie “aktor czas” (patrz artykuł: Aktor czas).
Źródła
[zotpressInTextBib style=”apa” sort=”ASC”]