Analityk jest w projekcie informatycznym jak architekt w projekcie budowlanym. W obszarze analiz biznesowych wykształciły się standardy: należą do nich definicje kluczowych pojęć opisujących procesy biznesowe oraz notacje stosowane do dokumentowania wyników tych analiz. Stosowanie własnych nietypowych metod, niestandardowych definicji pojęć i niestandardowych systemów notacyjnych, w obecnych czasach, prowadzi do sytuacji, w której inna firma (np. dostawca oprogramowania) ma problem ze zrozumieniem tego co otrzyma, to zaś skutkuje wieloma nieporozumieniami, a najczęściej prowadzi zarzucenia korzystania z takich dokumentów.
Książka powstała dla wszystkich zlecających analizy i wykonujących je. Opisuje metody prowadzenia analizy i dokumentowania systemów jakimi są firmy i organizacje. Opisałem w niej przykłady zastosowania narzędzi jakimi są standardy notacyjne takie jak notacje BPMN, UML, SBVR, BMM. Specyfikacje tych języków są dostępne bezpłatnie na stronie http://www.omg.org.
W książce przytoczono i skomentowano zanimizowane diagramy, modele procesów biznesowych i fragmenty modeli logiki oprogramowania, wykonane z użyciem wymienionych wyżej notacji. Są to modele, które opisują wszystkie etapy projektów, przeszły pozytywnie przez audyty w projektach, na ich podstawie wdrożono z sukcesami oprogramowane.
Osobom zlecającym analizy swoich firm, polecam tę książkę, by dowiedzieli się czego powinni się spodziewać od analityków, analitykom polecam ją jako zestaw przykładów stosowania opisanych tu standardów. Prawa kolumna serwisu zawiera okładkę mojej książki, kliknięcie prowadzi bezpośrednio na stronę wydawnictwa, gdzie można ją zamówić i otrzymać w ciągu kilku dni.
O autorze
Równolegle z uczestnictwem w projektach, w których moją rolą jest odkrywanie, analiza i modelowanie (dokumentowanie) systemów decyzyjnych i prawa rządzącego tymi systemami, prowadzę studia i prace naukowe z obszaru analizy i modelowania systemów zorientowanych na reguły.
Przedmiotem badań są systemy społeczne takie jak środowisko firmy, organizacji, urzędu ale także państwa czy grupy państw. Celem jest uogólnienie tych metod i stworzenie metodyki opisu systemu społecznego jako systemu złożonego z obiektów oraz praw rządzących zachowaniem tych obiektów oraz praw rządzących interakcjami między nimi. Metodyka ta pozwoliła by tworzyć modele mechanizmów opisujących reakcje takich systemu (ich zachowanie) a także ich badanie i rozwijanie. W systemach społecznych, w przeciwieństwie do natury, prawa ustalają ludzie będący zarazem elementami tych systemów. Zrozumienie tego pozwoliłoby na świadome kształtowanie zachowania tych systemów a przynajmniej wyjaśniało by ich zachowanie.
Dalsze moje prace skupiają się na badaniach ukierunkowanych na stworzenie metodyki pozwalającej uogólnić prace nad systemami opisanymi wyżej, co mam nadzieję przyniesie korzyści zarówno organizacjom w procesach ich analizy i rozwoju a dotyczy to także Państwa, które także jest taką organizacją. Badanymi obszarami się logika formalna, teoria i filozofia prawa, ogólna teoria systemów, epistemologia.
Dyskusja o treści książki
25 Październik 2016 r. Moja książka jest od dziś dostępna w księgarniach. Planuję napisać kolejną, raczej już w formie podręcznika. Ta z założenia miała stanowić lekką lekturę na bazie zaktualizowanych wpisów na tym blogu czyli moich doświadczeń, absolutnie nie miała być zastępnikiem specyfikacji notacji czy podręczników, raczej ich uzupełnieniem.
Dla mnie, autora książki, najcenniejsze są krytyczne uwagi, dlatego zachęcam do ich zgłaszania pod tym artykułem. Proszę jednak aby ewentualne błędy wskazać a nie tylko sygnalizować ich istnienie, dajcie mi szanse na poprawę i odpowiedź 🙂
Przyznaję, że świadomie negocjowałem z wydawnictwem minimalizowanie ingerencji korekty w styl pisania. Książka powstała na bazie treści mojego bloga, artykuły zostały zaktualizowane w obszarze notacyjnym jednak celowo zachowałem dość swobodny styl wyrażania myśli, mając nadzieję, że czytelnik czytając, nie będzie się czuł jak by czytał akademicki podręcznik. Czy to był dobry pomysł? Mam nadzieję, że uwagi czytelników potwierdzą lub zanegują ten pomysł dlatego zachęcam czytelników do dzielenia się opiniami na stronie wydawnictwa HELION: Oceń książkę.
Zrozum, zanim zaproponujesz rozwiązanie
Analiza biznesowa, przeprowadzana przez wykonawcę rozwiązań IT dla biznesu, nie polega na zwykłym spisaniu problemów zgłaszanych przez klienta. Zapis przebiegu spotkań, wypunktowanie najważniejszych wymagań stawianych przed oprogramowaniem i prezentacja ich klientowi w formie tabeli to jeszcze nie analiza biznesowa! Wykonawca oprogramowania otrzymuje w ten sposób jedynie wnioski dotyczące efektów wadliwego działania aktualnego systemu zarządzania, ale dalej nie ma pojęcia o przyczynach tego stanu rzeczy. Jak zatem może zaproponować zleceniodawcy lepsze rozwiązanie?
Powyższe to fragment wprowadzenia z czwartej okładki.
Od lat pytają mnie studenci i kursanci o literaturę opisująca praktykę i zawsze miałem problem… W końcu dałem się namówić (pisanie książki to mega pożeracz czasu). Mam nadzieję, że okaże się pomocna bo nie jest gruba.
Książkę adresuję nie tylko specjalistom, ale właśnie szczególnie do odbiorcom takich analiz i projektów…
Hanna Wesołowska, Analityk Biznesowy: Książka inspiruje, skłania do rewidowania swojego podejścia i korygowania popełnianych błędów. Pan Żeliński przygotował wyjątkowy zbiór felietonów. Bazuje on na treściach z bloga o analizie z najdłuższą historią w Polsce. Autor wychodzi od sytuacji bardzo często spotykanych na rynku, na których notorycznie wykłada się biznes i analitycy. Dalej omawia najczęściej wykorzystywane techniki analizy (przypadki użycia, procesy, modele pojęć, itd.) tłumacząc na przykładach ich właściwe i praktyczne zastosowanie. Pan Żeliński pokazuje swoją bogatą wiedzę i znajomość przeróżnych technik, notacji i podejść. Z tekstu płynie też niespotykane zrozumienie ich przeznaczenia i właściwego zastosowania. Prezentowane podejście doskonale sprawdza się w projektach informatyzowania działalności organizacji. Projekty takie angażują ogromne zasoby i pewnie większość specjalistów i budżetów. Spotykamy także inne typy projektów wymagających eksperymentów i dużej dozy kreatywności. Nie bazują one na stanie obecnym. Może to być innowacyjny produkt lub atrakcyjny, sprzedający interfejs z banalną logiką (zapis i odczyt prostych informacji z bardzo prostym przetwarzaniem). Moim zadaniem takie projekty mogą także zyskiwać z zastosowania nieco odmiennego podejścia. Jednakże i w nich nie powinno zabraknąć większości dobrych praktyk analizy prezentowanych w książce. Czytając artykuły Pana Żelińskiego napotyka się co chwilę nazwy stosowanych podejść czy notacji. Skłania to do poszukiwania, odkształcania się i poszerzania horyzontów. Gdyby nie te artykuły, myślę, że metody te nie rozprzestrzeniałyby się tak szybko i szeroko w Polsce. Ta książka to przede wszystkim inspiracja, nawołanie do przemyślenia tego co i jak robimy w analizie oraz źródło do stworzenia listy lektur obowiązkowych takich jak specyfikacje metod i języków modelowania. Jednak czytanie samej teorii nie gwarantuje jej właściwego zrozumienia i zastosowania. Książka Pana Żelińskiego wypełnia tę lukę – pokazuje praktyczne zastosowanie, częste wypaczenia oraz przypomina nieustannie o prawdziwym sensie i celu pracy analityka. Polecam! (Źródło: Analiza biznesowa. Praktyczne modelowanie organizacji)
Ta książka to przede wszystkim inspiracja, nawołanie do przemyślenia tego co i jak robimy w analizie oraz źródło do stworzenia listy lektur obowiązkowych takich jak specyfikacje metod i języków modelowania. Jednak czytanie samej teorii nie gwarantuje jej właściwego zrozumienia i zastosowania. Książka Pana Żelińskiego wypełnia tę lukę ? pokazuje praktyczne zastosowanie, częste wypaczenia i przypomina nieustannie o prawdziwym celu pracy analityka.
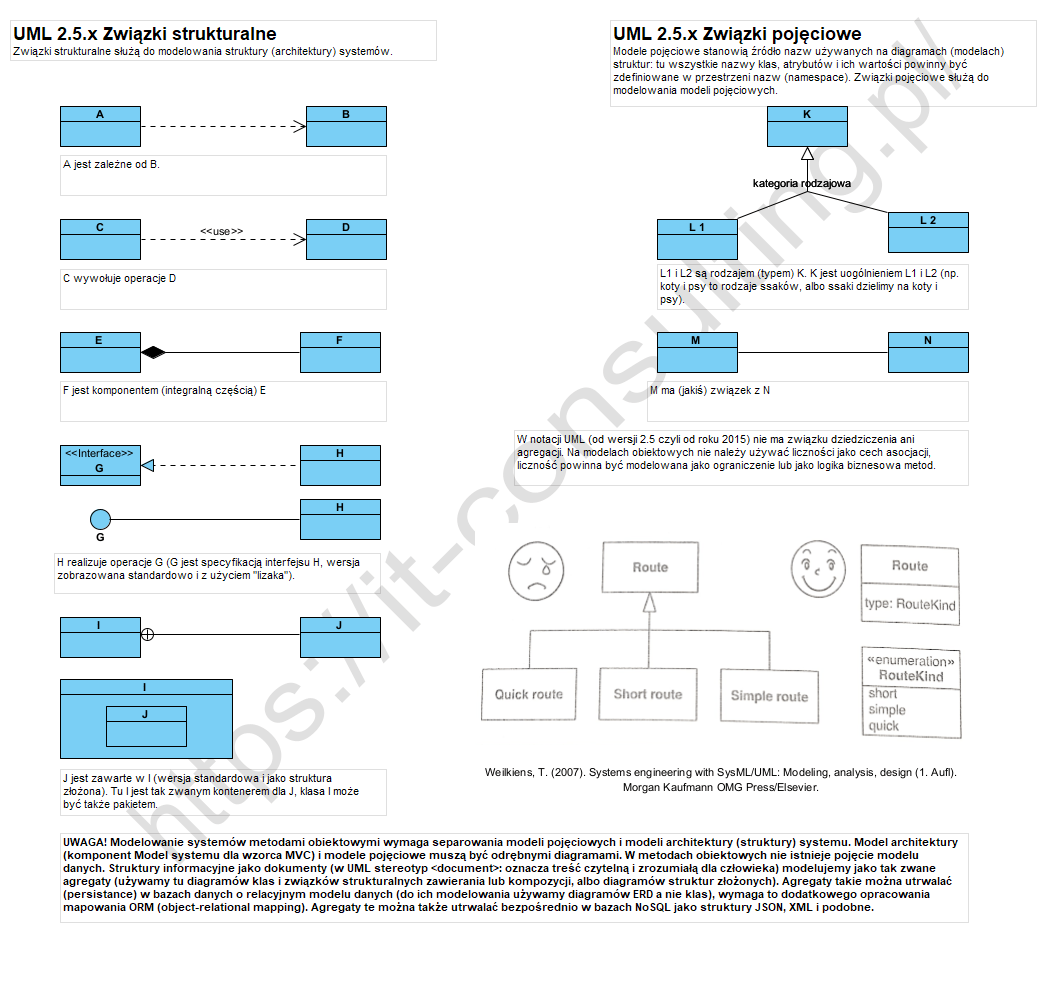
Tym razem o kilku powszechnie popełnianych błędach w korzystaniu z UML. Chodzi o pojęcia abstrakcji, metamodeli i zależności oraz o związki między elementami na diagramach. Kluczową, moim zdaniem, przyczyną tworzenia “złych” modeli obiektowych jest używanie notacji UML do tworzenia modeli strukturalnych, nie mających z obiektowym paradygmatem nic wspólnego. Druga to niezrozumienie pojęcia paradygmatu obiektowego. Ogromna ilość diagramów wykonanych z użyciem symboli notacji UML, z UML i paradygmatem obiektowym ma niewiele wspólnego.
Najpierw kilka definicji i pojęć.
Paradygmat programowania (ang. programming paradigm) ? wzorzec programowania komputerów przedkładany w danym okresie rozwoju informatyki ponad inne lub ceniony w pewnych okolicznościach lub zastosowaniach. (Źródło: Paradygmat programowania ? Wikipedia, wolna encyklopedia)
No to teraz obiektowy paradygmat:
Programowanie obiektowe (ang. object-oriented programming) ? paradygmat programowania, w którym programy definiuje się za pomocą obiektów ? elementów łączących stan (czyli dane, nazywane najczęściej polami) i zachowanie (czyli procedury, tu: metody). Obiektowy program komputerowy wyrażony jest jako zbiór takich obiektów, komunikujących się pomiędzy sobą w celu wykonywania zadań. Podejście to różni się od tradycyjnego programowania proceduralnego, gdzie dane i procedury nie są ze sobą bezpośrednio związane. (Źródło: Programowanie obiektowe ? Wikipedia, wolna encyklopedia)
albo:
Programowanie obiektowe lub inaczej programowanie zorientowane obiektowo (ang. object-oriented programing, OOP) to paradygmat programowania przy pomocy obiektów posiadających swoje właściwości jak pola (dane, informacje o obiekcie) oraz metody (zachowanie, działania jakie wykonuje obiekt). Programowanie obiektowe polega na definiowaniu obiektów oraz wywoływaniu ich metod, tak aby współdziałały wzajemnie ze sobą. (Źródło: Programowanie obiektowe ? Encyklopedia Zarządzania)
Słownik języka polskiego mówi:
współdziałać 1. ?działać wspólnie z kimś? 2. ?przyczyniać się do czegoś razem z innymi czynnikami? 3. ?o mechanizmach, narządach itp.: funkcjonować w powiązaniu z innymi?
wywołać ? wywoływać 1. ?wołaniem skłonić kogoś do wyjścia skądś? 2. ?przypomnieć sobie lub innym coś? 3. ?spowodować coś lub stać się przyczyną czegoś? 4. ?oznajmić coś publicznie? 5. ?oddziałać na kliszę, błonę lub papier fotograficzny środkami chemicznymi w celu uwidocznienia obrazu utajonego na materiale światłoczułym?
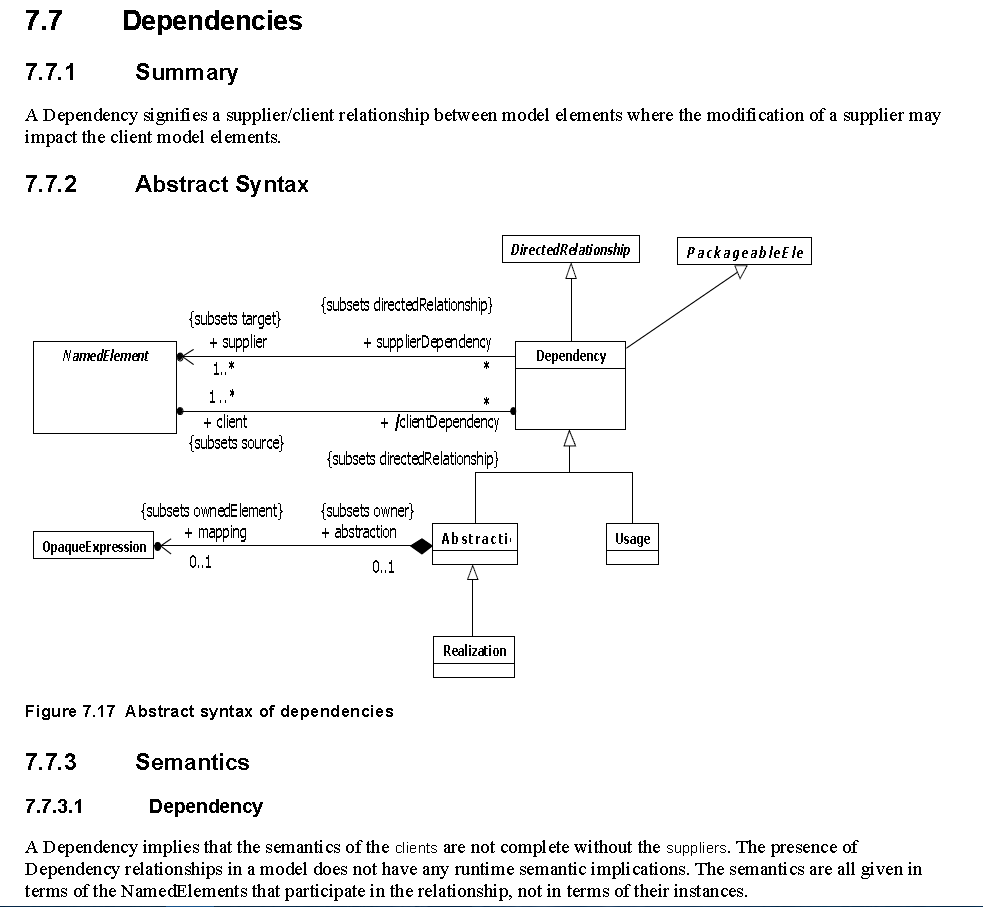
Tak więc stwierdzenie, że “obiekty z sobą współdziałają” oznacza, że “wywołują się” wzajemnie w celu spowodowania czegoś konkretnego. Innymi słowy obiekty tworzące program (system) są od siebie wzajemnie uzależnione. Dlatego podstawowym związkiem w procesie analizy i projektowania zorientowanego obiektowo jest wzajemna “zależność”, nazywana w oryginalnej specyfikacji UML związkiem “usługodawca-usługobiorca”.
Zależności
Związek ten należy utożsamiać z każdą wzajemną zależnością. Z uwagi na to, że mamy wiele typów zależności, wskazujemy konkretny typ z pomocą stereotypu (<<[nazwa_typu]>>).
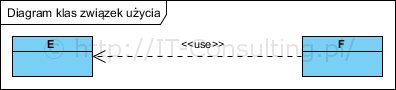
Najczęściej występujący typ zależności to związek użycia. Oznacza on, że jeden obiekt wywołuje umiejętności (operacje) innego czyli “używa go” do realizacja swojego zadania. Związek taki oznaczany stereotypem <<use>>:
F używa (jest zależny od) E (co do zasady tu F nie jest samodzielny “w tym co robi”).
Tak więc model oprogramowania w notacji UML z użyciem obiektowego paradygmatu powinien wyglądać mniej więcej tak:
Na diagramie użyto symboli klas (graficzna reprezentacja stereotypów) zaczerpniętych wzorca architektonicznego BCE.
Realizacja i kompozycja
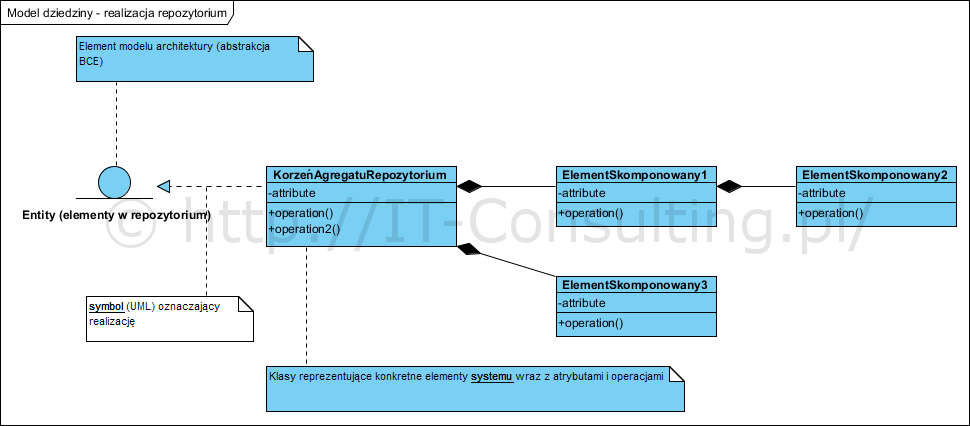
Dokumentowanie detali struktury elementów np. repozytorium, wymaga stworzenia kolejnego diagramu: modelu struktury obiektów reprezentujących np. złożoną strukturę obiektu niosącego informacje (np. z formularza).
Korzystamy tu ze związku realizacja i związku kompozycja. Realizacja to związek pomiędzy specyfikacją a jej realizacją (projektem, implementacją, itp.), wskazuje zależność implementacji od jej modelu. C2 jest specyfikacją (opisem, dokumentacją) realizacji D2. Najczęściej związek ten jest stosowany pomiędzy specyfikacją interfejsu a jego implementacją a także generalnie pomiędzy abstrakcją a jej realizacją. Typowym przykładem użycia tego związku jest np. pokazanie na jednym diagramie abstrakcji bytu w repozytorium i realizacji jej struktury:
Na diagramie użyto także związku “całość-część”: linia zakończona wypełnionym rombem na jednym końcu. Romb wskazuje na “całość”: element nadrzędny drzewiastej struktury konstrukcji. Jest to specjalny związek oznaczający trwałe (konstrukcyjne) powiązanie pomiędzy detalami składającymi się na określoną całość. UWAGA! Nie ma on nic wspólnego z pojęciem “relacji” znanym z teorii relacyjnych baz danych!
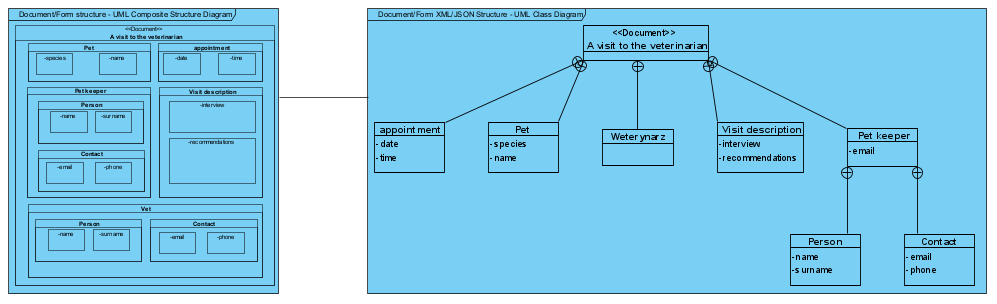
Z uwagi na to, że związek kompozycji stosowany jest do “rzeczy materialnych” (np. odwzorowywanie powyższego w postaci struktury klas w kodzie, OOP, pokazanie struktury materialnych konstrukcji, np. samochodu), na modelach oprogramowania, do modelowania struktury formularzy i komunikatów (dane) stosujemy związek zawierania (ang. member w oryg. UML):
Modelowanie struktury formularzy/komunikatów: po lewej diagram struktur złożonych UML, po prawej identyczna struktura jako klasyczny diagram klas i związki zawierania (modelowanie agregatów danych).
Generalizacja i asocjacja
Oprócz modeli struktur, powstają często modele pojęciowe. Są to odrębne diagramy. Ich celem jest dokumentowanie związków semantycznych i syntaktycznych pomiędzy kluczowymi pojęciami wykorzystywanymi w projekcie. Stanowią one nazwy obiektów i ich typy (atrybuty klas to także obiekty). Wykorzystywane są tu dwa rodzaje związków: generalizacja i asocjacja. Są to związki reprezentujące WYŁĄCZNIE logiczne powiązania pomiędzy pojęciami, nie modelują one struktur a ni implementacji!
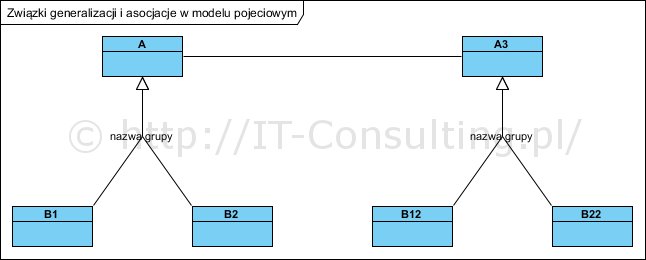
Jeżeli jakieś pojęcie ma swoje specjalizowane typy, lub z drugiej strony, grupa pojęć daje się uogólnić innym nadrzędnym pojęciem (generalizowanie), stosujemy związek generalizacji. Związek ten (korzystanie z niego) ma sens tylko gdy liczba typów to co najmniej dwa, co do zasady związek generalizacji służy do grupowania. Jeżeli pomiędzy pojęciami istnieje związek wynikający z dziedziny problemu (np. związek pomiędzy zwierzęciem a karmą dla niego) modelujemy go linią ciągłą łączącą powiązane tak pojęcia. Poniżej graficzny przykład użycia tych związków:
B1 i B2 to konkretne typy pojęcia A (typem jest także pojęcie). Analogicznie B12 i B22 to typy pojęcia A3. Pomiędzy pojęciami A i A3 istnieje związek logiczny (można go nazwać, wpisując te nazwę na linii). Typy mogą mieć więcej niż jeden kontekst dlatego mogą zostać pogrupowane a każda grupa otrzymuje nazwę “nazwa grupy” (oryg. Generalization Sets). Nie ma sensu związek generalizacji pomiędzy tylko jedną parą pojęć, bo oznacza wtedy po prostu tożsamość. Np. pojęcie “województwo” w Polsce ma obecnie szesnaście specjalizacji, mają one swoje nazwy, i to jest jedna grupa typów. Jednak województwa można podzielić także np. ze względu na wielkość na np. trzy grupy: małe województwo, średnie województwo i duże województwo, i to będzie druga i niezależna grupa typów.
Modele…
Wszystkie powyższe przykłady to diagramy klas notacji UML, jednak jak widać każdy ma zupełnie inne przeznaczenie (jest modelem czego innego). Nie omawiałem tu zupełnie diagramów klas modelujących kod programów. Zaznaczę jedynie, że są to kolejne modele dokumentowane z użyciem diagramów klas notacji UML, i omówione powyżej związki dziedziczenia i asocjacje na modelach pojęciowych mają tam zupełnie inne znaczenie.
Modele mogą być różne i dotyczyć różnych rzeczy (patrz Modele….). Tu chcę zwrócić uwagę na bardzo ważny aspekt: abstrakcyjne i rzeczywiste pojęcia w modelach (na diagramach). Dostrzegam ogromny bałagan nie tylko w dokumentach projektowych ale także i w literaturze, gdzie autorzy pokazują wiele różnych przykładów, które niestety są złe i pozbawione uzasadnienia.
Przede wszystkim modele dzielimy, jak już wspomniałem, na pojęciowe i te modelujące jakąś określoną rzeczywistość. Modele pojęciowe to modele pokazujące pojęcia oraz semantyczne i syntaktyczne związki miedzy nimi. Modele pojęciowe służą do udokumentowania dziedzinowej taksonomii co z jednej strony pozwala utrzymać pełną jednoznaczność dokumentacji a z drugiej, na etapie implementacji, pozwala podejmować decyzje o typach danych. Służą one np. do budowania słowników i etykietowania np. pól formularzy (pole Nazwa województwa, którego zawartość będzie wybierana ze słownika zawierającego szesnaście nazw). Na tych modelach pojawiają się w zasadzie wyłącznie pojęcia stanowiące abstrakcje i typy, nie są to modele żadnego kodu, dziedziny itp. Tu przypomnę, że model dziedziny systemu to model opisujący mechanizm jego (systemu, aplikacji) działania, reprezentowany jest przez literkę M we wzorcu MVC, poważnym błędem jest uznawanie tych modeli za modele danych.
Modele struktury to modele opisujące określone “konstrukcje”, głównie na dwóch poziomach abstrakcji: jako model i jako metamodel. Z reguły, w projektach związanych z oprogramowaniem, ta konstrukcja to właśnie Model Dziedziny czyli mechanizm działania, tak zwana logika biznesowa/dziedzinowa aplikacji.
Podsumowanie
Tak więc nie ma czegoś takiego jak “diagram klas dla projektu”. Mamy dla danego projektu: model pojęciowy, modele logiki systemu, modele struktury obiektów, modele implementacji. To wszystko są diagramy klas ale każdy z nich do model “czegoś innego”. Paradygmat obiektowy jasno mówi: obiekty współpracują, więc standardowym związkiem w modelach logiki działania są związki użycia a nie asocjacje ani związki dziedziczenia czy kompozycji. Diagramy te nie są żadnymi modelami danych między innymi dlatego, że z zasady paradygmat obiektowy ukrywa je (hermetyzacja), “na zewnątrz” dostępne są wyłącznie publiczne operacje obiektów. Utrwalanie obiektów (zapis wartości atrybutów np. w bazie danych) to zadanie do rozwiązania dopiero na etapie implementacji, polegające na zagwarantowaniu “zachowania” stanów obiektów na czas wyłączenia zasilania, by nie “uleciały” z pamięci komputera, który jest środowiskiem wykonania programu. Na etapie analizy obiektowej i modelowania logiki systemu nie modelujemy żadnych danych.
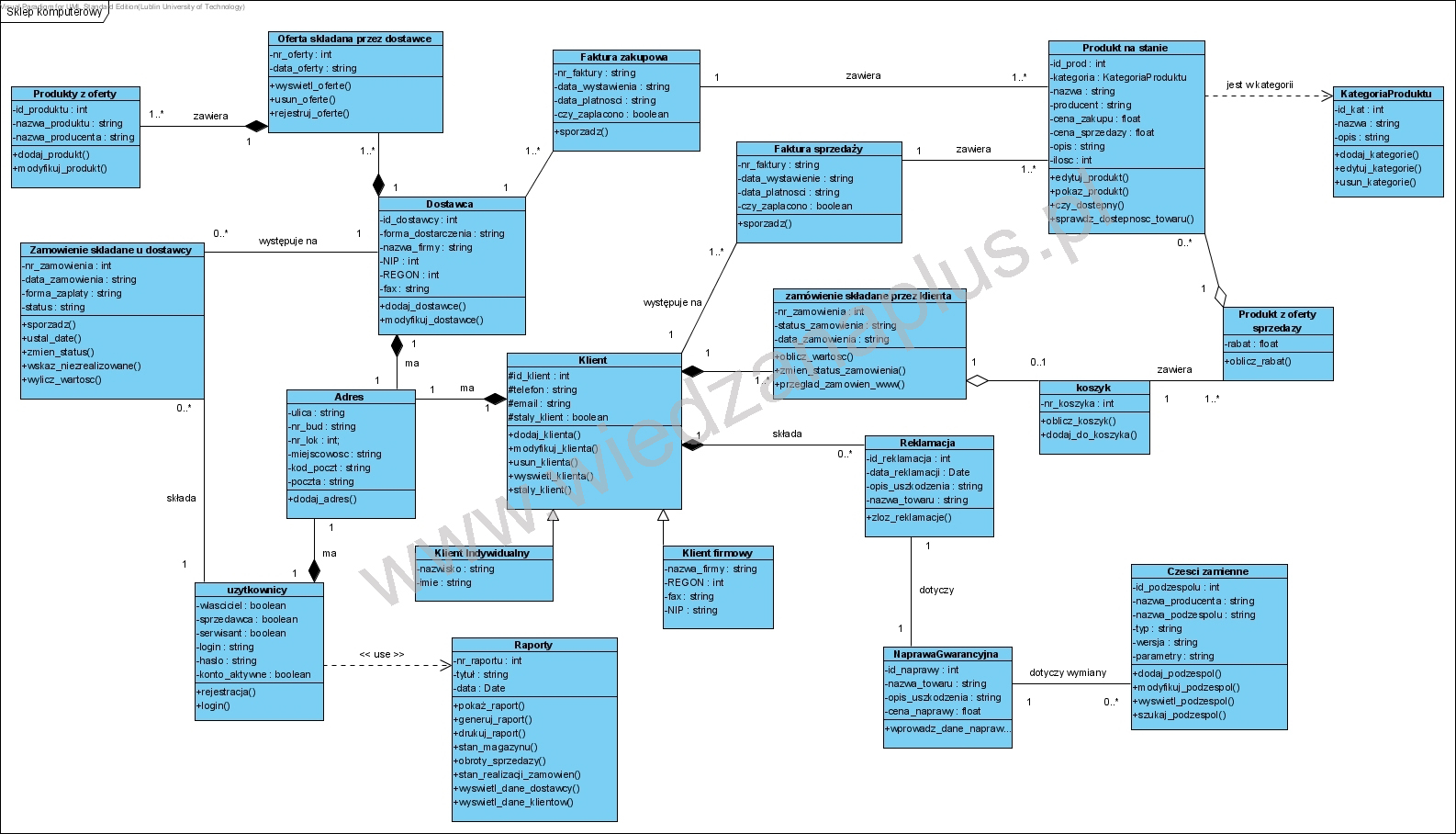
Poniższy przykład, jakich wiele w sieci, jest wzorcowym antyprzykładem.
Pierwsza zła cecha tego diagramu to częsty błąd nazywany popularnie “przeciążaniem obiektów”: tu obiekt Faktura ma operacje “sporządź”. Klasyczny błąd architektoniczny polegający na obciążaniu obiektu cudzą odpowiedzialnością. Jeżeli klasa Faktura reprezentuje np. faktury sprzedaży, to system mający w pamięci kolekcję setek faktur i każda z kodem (ma te operację) służącym do jej sporządzenia byłby masakrą zajętości pamięci. Dodam, że model taki nie ma nic wspólnego z rzeczywistością, bo faktury wystawia “ktoś” a nie “faktura”. Trzecia rzecz: faktura zakupu i faktura sprzedaży to niczym nie różniące się struktury, więc tworzenie takiego rozróżnienia jest pozbawione sensu. To błędy pojęciowe i ten diagram ma masę takich błędów. Druga wada: błędne użycie związku kompozycji: powyższy diagram należałoby interpretować jako strukturę o jednej zwartej konstrukcji, np. takiej jak samochód składający się z setek podzespołów ale stanowiący jednak jedną całość. Brak modelu pojęciowego i słownika powoduje wiele niejednoznaczności. Np. związek pomiędzy Klientem a reklamacją wskazuje, że Reklamacje są integralną częścią Klienta (tak jak koła i silnik są integralną częścią samochodu) co nawet w świetle potocznego rozumienia tych słów kłóci się ze zdrowym rozsądkiem.
Użycie związków pojęciowych (asocjacja) jest zupełnie niezrozumiałe w tym przypadku. Nazwa asocjacji “zawiera” nie ma kierunku a więc nie wiadomo co jest zawarte w czym. Związki zależności także są niejasne: jak interpretować np. zapis mówiący, ze obiekty klasy użytkownicy zależą od obiektów klasy Raporty? Jeżeli autor miał na myśli “użytkownik używa raportów” to popłynął w sferę “mowy potocznej”, to chyba najczęściej spotykany błąd polegający na tym, że autor diagramu nadal pisze specyfikację prozą, ale z użyciem symboli (tu UML) zamiast słów.
Mogę się jedynie domyślać, że autor diagramu “miał w głowie” model relacyjny związków encji i użył ikon z notacji UML w całkowicie innych znaczeniach niż ta notacja definiuje. Takie diagramy nie powinny powstawać, są one niestety dowodem na to, że programiści mówiący “te dokumenty z UML nic nie wyjaśniają i są nieprecyzyjne, i tak musimy sami powtórzyć te analizę” mają rację. Są także dowodem, że są to jednak projekty strukturalne a nie obiektowe, a użycie notacji UML polegało na skorzystaniu z zestawu ikon tak się to robi tworząc niesformalizowane schematy blokowe z użyciem np. programów do tworzenia prezentacji takich jak PowerPoint. Zapewne poza autorem tego diagram, nikt nie ma pojęcia o co w nim chodzi…. Jeżeli autor miał na celu udokumentowanie “modelu danych” to powinien użyć notacji ERD. A tak to mamy schemat blokowy, w którym ktoś użył UML jako biblioteki symboli wprowadzając czytelnika w błąd.
Niestety “sprawne” korzystanie z takich specyfikacji wymaga umiejętności czytania modeli pojęciowych (diagramów klas UML) opisujacych syntaktykę (syntax) jak wyżej (ich tworzenie też do łatwych nie należy…). Przytaczam to jako źródło tego o czym tu pisałem.
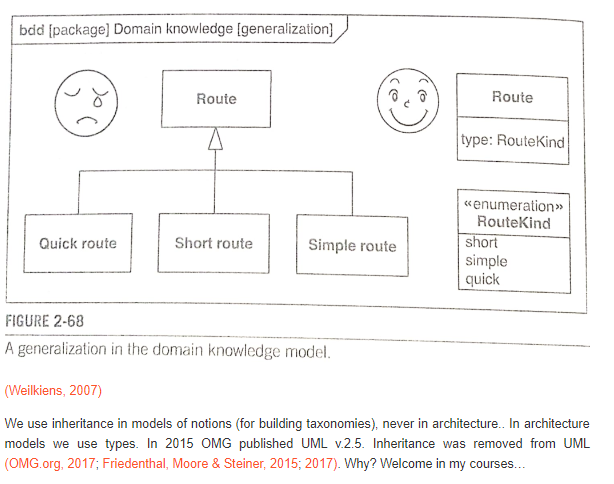
W UML “wszystko jest klasą”, związki między elementami diagramów także. Zostało to pokazane w specyfikacji UML v.2.5.:
W UML 2.5 praktycznie znika w końcu dziedziczenie i agregacja. Uff… poniżej podsumowanie na jednym diagramie.
Dodatek [2022-07-22]
…chciałbym zapytać o dziedziczenie w UML. Brałem ostatnio udział w kilku rozmowach o pracę. Moi rozmówcy często utrzymują, że w UML jest to dziedziczenie. Mało tego, wykorzystują to dziedziczenie na diagramach klas, w czymś co nazywają modelem dziedziny (oczywiście bez operacji klas). Zajrzałem do specyfikacji UML i jestem trochę zdezorientowany, ponieważ pojęcie dziedziczenie dość często występuje w tej dokumentacji, choćby w tym fragmencie.
W jakim znaczeniu jest tu użyte pojęcie dziedziczenia? Czy jest gdzieś w specyfikacji wprost informacja o usunięciu dziedziczenia z UMLa?
Porównując ze specyfikacją 2.4. nie ma, pojęcie dziedziczenia nadal jest obecne w językach programowania, a w specyfikacji 2.5.xx słowo “inheritance” pojawia sie tylko 4 razy, i dotyczy wyłącznie komentarzy związanych z uogólnieniami.
Cytowany związek Generalizacji jest związkiem pojęciowym a nie strukturalnym czegoś istniejącego (struktura modelowanego systemu). Formalnie w UML mamy związek Generalizacji, i jest to związek pojęciowy, ale nie ma w UML rozdziału “Dziedziczenie”. Inherit w j. angielskim to także “przejęcie cech po czymś” czyli związek generalizowania i specjalizowania. Generalziacja, jako związek ogólny-szczególny, pokazuje że szczególny przypadek, pojęcie i jego definicja, ma wszystkie cechy przypadku ogólniejszego, więc pies jako szczególny typ ssaka ma wszystkie cechy ssaka (chodzi o definicje tego czym jest ssak). Czyli: 1. ssak: kręgowiec, którego młode karmią się mlekiem matki, 2. pies: <ssak> który szczeka, więc:
pies: <kręgowiec, którego młode karmią się mlekiem matki>, który szczeka,
czyli pies (a konkretnie definicja psa) “dziedziczy” po ssaku (definicji ssaka) jego określone cechy, czyli oznacza to, że są one (cechy ssaka) np. dla psa i kota wspólne, a nie że, kot czy pies coś “dziedziczy” po ssaku :).
Dlatego w UML teraz jest napisane, że mamy generalizację jako związek między klasami, ale nigdzie nie ma związku “dziedziczenia” między klasami.
Tekst rozdz. 9.2.3.2. tłumaczymy tak, ze generalizacja oznacza, że generalizowana definicja (cechy czyli atrybuty i zachowania) są wspólne (dziedziczą) dla specjalizowanych elementów. W modelu pojęciowym (namespace) tak to działa. I teraz: model struktury czegokolwiek istniejącego nie ma abstrakcji (a generalizowane pojęcia to abstrakcje, pojęcie ssak to pojęcie abstrakcyjne). Opisując więc traktor jako pojazd czy dokumenty w księgowości jako dokuenty, nie ma nad nimi “uogólnień”, po których dziedziczą (sa to jednak pojęcia słownikowe). Po trawie nie biegają “ssaki” tylko psy, koty, lwy…
Znakomita większość znanych mi ludzi w IT nie odróżnia modelu pojęciowego od modelu struktury systemu, który zbudowany jest (każdy) z realnych elementów. W miejsce “starego” dziedziczenia w UML wprowadzono pojęcia: szablon (template) oraz rola (realnym czymś w samochodzie jest “silnik”, pojęcie “napęd” to nazwa funkcji/roli określonego komponentu, ale nie piszemy: “<silnik> dziedziczy po <napędzie>” tylko “<silnik> pełni rolę <napędu>” tak samo jak nie powiemy “<pies> dziedziczy po <zwierzę domowe>” tylko “<pies> pełni rolę <zwierzęcia domowego>”.
Języki programowania pozwalają na tak zwane re-użycie kodu, czyli wyciąganie pewnych wspólnych cech ponad konkretne komponenty/klasy (abstrakcja) po to by tylko raz pisać kod komponentów mających wspólne cechy. Jednak projektując “model dziedziny” nie ma w niej abstrakcji, mając model dziedziny (mechanizm działania aplikacji) zamieniamy generalizacje i “dziedziczenia” pojęciowe na atrybuty i typy realnych rzeczy, tak to opisano książce o modelowaniu systemów już w 2007 roku:
Oczywiście programista może używać gdzie chce dziedziczenia (ma taką możliwość w każdym obiektowym języku programowania) ale to jedna z najgorszych praktyk, bo łamiących kluczową zasadę jaką jest hermetyzacja komponentów (“zakaz” współdzielenia czegokolwiek). To dlatego od wielu lat OOP (Object-oriented Programming, języki i programowanie obiektowe) i OOAD (Object-oriented Analysis and Design) to odrębne “dziedziny”.
Kolejne projekty IT zaliczają kolejne wpadki i wśród przyczyn prawie zawsze pojawia się utrata panowania nad złożonością projektu. Jednym z kluczowych elementów analizy, także systemowej, jest redukowanie złożoności. Robi się to budując modele i metamodele analizowanej rzeczywistości, a na wstępnych etapach projektowania abstrahuje się od szczegółów. Jak? Operując właśnie modelami i metamodelami. Od dawna noszę się z zamiarem napisania czegoś o zarządzaniu złożonością i spójnością dokumentów. W końcu “nawinął” się dokument, na którym moim zdaniem warto “poćwiczyć”. Jest to ciekawy dokument zatytułowany:
Metareguły i zasady budowy cyfrowych usług publicznych
We wstępie poznajemy cel i (chyba) misję projektu:
?Obywatel jest angażowany w najmniejszym możliwym stopniu w proces świadczenia usług publicznych, zaś usługi rozumiane są jako proces zaspokajania potrzeb obywateli.?
Często zamiast nowoczesnej usługi cyfrowej efektem prac jest ?zelektronizowana? procedura, która tym różni się od tradycyjnego sposobu załatwiania sprawy, że wniosek wypełniany jest przy pomocy komputera. Stosuje się różne standardy budowy usług cyfrowych, jak i ich rozwoju, co wpływa bezpośrednio na różnice w jakości, dostępności i użyteczności tych usług. Aby uniknąć takich negatywnych efektów, w wielu miejscach na świecie wdrożono wytyczne do budowy i utrzymania usług cyfrowych, gwarantujące ustandaryzowane podejście niezależnie od podmiotu wdrażającego usługę. Głównym beneficjentem takiego podejścia jest użytkownik końcowy.
Postawienie użytkownika?klienta administracji i jego potrzeb w centrum oznacza, że technologie informacyjne i komunikacyjne pomagają administracji w załatwieniu SPRAWY KLIENTA, a nie załatwieniu SPRAWY PRZEZ KLIENTA. Podejście to zakłada, że obywatel jest angażowany w najmniejszym możliwym stopniu w proces świadczenia usług publicznych, zaś usługi rozumiane są jako proces zaspokajania potrzeb obywateli. (Źródło: Metareguły i zasady budowy cyfrowych usług publicznych | Ministerstwo Cyfryzacji, plik metareguly_i_zasady_budowy_uslug_cyfrowych_ready)
Postanowiłem na przykładzie tego opracowania pokazać na czym polega redukowanie szczegółów w analizie. Dokument ten jest trudny do oceny i zrozumienia w przypadku czytania go wprost, z uwagi na to, że nie zawiera żadnych uogólnień, a mało który czytelnik jest w stanie zbudować sobie w myśli taki “prosty” model całości. W tytule pojawia dość trudne nie tylko dla laika, pojęcie “metareguły”. Czym one są? Najpierw kilka słow na temat tego czym są pojęcia z przedrostkiem meta-.
Meta- czyli co…
Zacznijmy od znaczenia przedrostka “meta-” (sł. j. polskiego PWN):
meta- ?pierwszy człon wyrazów złożonych wskazujący na wyższy stopień, następstwo lub zmienność czegoś?
W ramach OMG funkcjonuje specyfikacja “Meta-Object Facility“. Zawiera ona między innymi takie o to wyjaśnienie:
7.3 How Many Meta Layers?
One of the sources of confusion in the OMG suite of standards is the perceived rigidness of a ?Four layered metamodel architecture? that is referred to in various OMG specifications. Note that key modeling concepts are Classifier and Instance or Class and Object, and the ability to navigate from an instance to its metaobject (its classifier). This fundamental concept can be used to handle any number of layers (sometimes referred to as metalevels).
Wytłuściłem kluczowe elementy tego opisu. Podstawowymi pojęciami są “klasyfikator i instancja” lub znane z UML “klasa i obiekt” oraz “możliwość nawigacji (śladowanie) od instancji do jej metaobiektu” (czyli klasyfikatora tej instancji). Na stronach WIKI jest dość popularny w sieci przykład w postaci czterowarstwowego modelu:
Tych warstw nie nie zawsze jest (musi być) tyle, ale tu chodzi o zasadę. Każda sąsiadująca z sobą para warstw to (licząc od dolnej) obiekt (instancja) i jego klasyfikator (metaobiekt). Para obiekt-klasyfikator łączona jest związkiem <<instanceOf>> wskazującym na klasyfikator (czytamy: obiekt jest instancją klasyfikatora). Powyższy przykład zawiera także związki <<snapshot>> i proste asocjacje (np. classifier), które zaciemniają jego główny sens. Zawiera także moim zdaniem błąd: zależność pomiędzy rzeczywistymi bytami a ich abstrakcjami to <<Abstraction>> a nie <<instanceOf>>.
Przygotowałem więc, mam nadzieję, mniej abstrakcyjny przykład :):
Jak czytać ten diagram? Realny świat to Byty rzeczywiste, np. bierki do gry w szachy. Abstrakcja bytów rzeczywistych to zobrazowanie ich w postaci nazwanych prostokątów: diagram z tymi prostokątami to model konkretnej rzeczywistości ze zdjęcia. Każdy taki prostokąt to abstrakcja odpowiedniej bierki, czyli pozbycie się wszelkich szczegółów (materiał z jakiego są wykonane, kształt, itp.) nie potrzebnych do analizy np. reguł gry w szachy. Aby opisać w dokumentacji gry w szachy jej zasady, i uniknąć konieczności częstego używania nazw poszczególnych bierek, tam gdzie nie ma znaczenia to jak dana bierka może się poruszać po szachownicy, korzystamy z klasyfikatora: kolejnego uogólnienia jakim jest Bierka reprezentująca wszystkie dopuszczalne figury na szachownicy. Diagram z jednym prostokątem, klasyfikatorem, to metamodel.
Biorąc pod uwagę fakt, że bardziej złożone “rzeczywistości” mogły by wymagać bardzo dużej liczby obiektów (prostokątów) na modelu, z reguły stosuje się w dalszych etapach analiz metamodele a nie abstrakcje. Te służą raczej do tworzenia i testowania metamodeli. Tak więc jeżeli wśród obiektów na modelu można wyróżnić grupy o pewnych podobnych cechach, zastępuje się je jednym klasyfikatorem. Reprezentuje on wszystkie te obiekty. W tym przypadku jeden klasyfikator Bierka zastępuje na diagramie wszystkie “konkretne bierki”. Możemy też powiedzieć, że: obiekt Pion jest instancją klasy Bierka (podobnie Wieża itd.). Konkretne rzeczywista bierka np. Goniec, na konkretnej szachownicy konkretnego zestawu do gry w szachy, jest instancją obiektu Goniec z diagramu obiektów.
Tak więc model modelu to metamodel, czyli metametamodel rzeczywistości :). Czym więc będą metareguły? Niestety nie ma definicji w tym opracowaniu. Poszukajmy.
Metareguły charakteryzują stałość lub zmienność w czasie wcześniej odkrytych wzorców czy reguł (mogą to być reguły asocjacyjne, klasyfikujące, opisujące lub inne). (źr. Barbara Łopusiewicz (red.), Zarządzanie wiedzą w systemach informacyjnych. , Wydawnictwo Akademii Ekonomicznej, Wrocław 2004, ISBN: 83-7011-722-8 (34+16) (cytat, str. 216)).
Innymi słowy metareguły to reguły (tworzenia) reguł (tak jak metamodel to model modelu). Trochę dziwi mnie, że wprowadzono pojęcie “metareguły”. Pojęcie “polityki” było by moim zdaniem bliższe prawdy: “Polityka budowy cyfrowych usług publicznych”, ale to tylko dywagacje, nie chce tworzyć wątku “ja bym to zrobił inaczej” ;). Warto jednak podsumować, że meta reguła to wzorzec budowy reguł a nie “to czego one mają dotyczyć”… stąd moje zdziwienie użyciem pojęcia “metareguły” w kontekście dziedzinowym.
Ten wpis to jednak próba wzięcia otwartego udziału w tych konsultacjach. Celem moim jest złożenie ewentualnych uwag, zastrzeżeń i ich uzasadnienie.
Metareguły i zasady budowy cyfrowych usług publicznych
Kilka kluczowych pojęć w dokumencie:
1 Wstęp
We wstępie czytamy:
? zerwanie z dotychczasowym paradygmatem ucyfrowienia (informatyzacji) usług świadczonych dotąd drogą tradycyjną; usługa nie może być utożsamiana z formularzem, podaniem czy dokumentem, nawet elektronicznym, z możliwością przesłania przez internet (zarządzenie informacją, a nie jej nośnikiem),
Informacja to określony, nazwany zestaw danych. Zarządzanie informacją jest możliwe pod warunkiem, że zostanie utrwalona a jej struktura określona (zdefiniowana). Struktura danych stanowiących informację w postaci utrwalonej to nic innego jak formularz. Ustawodawca już jasno określił czym jest treść, nośnik a czym dokument. Innymi słowy: samo wyrażenie chęci skorzystania z Usługi wymaga wyartykułowania tego żądania i przekazania w jakiejś utrwalonej formie. Nie da się zażądać od Państwa czegoś nie mają możliwości wyrażenia tego żądania. Tak wiec nie wiem z czym chce zrywać autor dokumentu, ale usługa: musi mieć nazwę, opis tego czym jest i musi istnieć sposób zlecenia Państwu jej wykonania na rzecz obywatela chcącego skorzystać z tej usługi.
? proces świadczenia usługi odbywa się na poziomach back-office i middle-office, poziom front-office to inicjowanie usługi i uzyskiwanie korzyści (załatwienie sprawy). Proces świadczenia usługi przesuwany jest w stronę usługi typu A2A, zaś relacja A2C skupia się na potrzebach i korzyściach obywatela,
Powyższe jest więc potwierdzeniem tego co napisałem… Z perspektywy Obywatela pojęcia back-office i middle-office nie mają żadnego znaczenia (i skąd wiadomo, ze akurat dwa??). Za to ów “front-office” to nic innego jak “punkt kontaktu” a komunikacja z Obywatelem to niestety jakiś “formularz”. Proces (wy)świadczenia usługi jest (powinien być, zgodnie z treścią wstępu) całkowicie ukryty przed Obywatelem.
? otwarcie i integracja rejestrów publicznych przy zapewnieniu bezpieczeństwa danych obywateli.
Rejestry publiczne to “wnętrze systemu”, z perspektywy Obywatela “nie istnieją” bo jaką usługą (sprawą mającą wartość dla Obywatela) jest “dostęp do rejestru”? Jeżeli mam w kieszeni Dowód Osobisty, to czym tu jest dostęp do “Rejestru”?
2 Metareguły usług cyfrowych dla obywatela
Metareguły dotyczą sposobu funkcjonowania administracji publicznej w kontekście świadczenia usług w sferze cyfrowej. Są one kluczowe podczas budowy i świadczenia cyfrowych usług publicznych.
Traktuję to jako preambułę.
? Potrzeby i korzyści obywatela są w centrum ? na każdym etapie procesu świadczenia usługi punktem odniesienia jest potrzeba obywatela, miarą sukcesu jest korzyść uzyskana przez obywatela.
Rozumiem, że usługa to odpowiedź na potrzebę (jej zaspokojenie), produktem usługi jest “coś” z czego obywatel odnosi korzyść. Jednak korzyść obywatel nie powinna być przedmiotem zainteresowania Państwa bo z jakiego powodu? Jeżeli chcę dokument potwierdzający “coś” lub będący “decyzją administracyjną” to to, jaką korzyść ja odniosę zależy ode mnie i kontekstu. Np. wypis z katastru to produkt usługi, ale moja korzyść z jego posiadania (może chce sprzedać nieruchomość, a może się założyłem z kimś, że jest moja i chce to udowodnić). Wprowadzanie tu pojęcia “korzyść obywatela” jest moim zdaniem nadmiarowe.
? Usługi są świadczone w tle ? minimalizacja wymagań wobec klienta, ograniczenie etapów procesu administracyjnego do minimum, osobiste stawiennictwo wnioskodawcy jako wyjątek.
Jeżeli umawiamy się, że celem jest “załatwienie SPRAWY KLIENTA, a nie załatwienie SPRAWY PRZEZ KLIENTA” to powyższe jest jej łamaniem, “minimalizacja wymagań wobec klienta” powinna być raczej zastąpiona albo brakiem wymagań albo (co bardziej prawdopodobne) określonymi konkretnymi wymaganiami (a takie są zawsze, np. tytuł prawny do nieruchomości w przypadku żądania wypisu z księgi wieczystej).
? Administracja jest podstawowym źródłem danych ? pobieranie danych z rejestrów państwowych; zakaz wymagania od obywatela informacji będących już w posiadaniu administracji, możliwych do uzyskania automatycznie drogą elektroniczną bądź wynikających z procesu świadczenia usług.
To już mamy za sobą: urząd (Państwo) nie może żądać od obywatela danych, którymi juz dysponuje.
? Dokumenty skierowane do obywatela umieszczane są w repozytorium? w sytuacji, w której obywatel nie potrzebuje (nie zwraca się o wydanie) dokumentu kończącego świadczenie usługi (postępowanie administracyjne), ma możliwość pobrania go w dowolnym momencie.
To jest już implementacja, osobiście uważam, że na poziomie metareguł (metamodeli) nie operuje się implementacją (repozytorium), sugeruję pojęcie “archiwum” i “teczka sprawy”.
? Dostęp do informacji o stanie sprawy jest możliwy na każdym etapie ? system transakcyjny obsługujący usługę daje obywatelowi możliwość sprawdzenia statusu załatwianej sprawy i szacunkowego czasu do jej zakończenia, na kluczowych etapach sprawy użytkownik otrzymuje powiadomienia;
Tu jak wyżej… skoro obywatel “ma możliwość pobrania go [dokumentu] w dowolnym momencie” to chyba mamy tu zbędne powtórzenie treści.
? Usługi łączone są w pakiety ? powiązanie usług wynikających z danej potrzeby/zdarzenia życiowego (np. narodziny dziecka, becikowe, Rodzina 500+ – użytkownik ma możliwość załatwienia ich wszystkich w jednej transakcji).
To chyba ktoś popłynął. O jakiej “transakcji mowa” (znowu implementacja na poziomie metareguł). Usługi są autonomiczne i niezależne, jeżeli ktoś uzna, ze chce skorzystać z “kilku” (pakiet) to jest to kontekst klienta a nie systemu. Próba tworzenia nazwanych “pakietów” prowadzi do niewyobrażalnej liczby kombinacji (zakładam, że usług będzie nie kilka a znacznie więcej).
? Projektowanie uniwersalne ? responsywność, dostępność z różnych platform sprzętowych oraz dla osób niepełnosprawnych ? uwzględnienie wytycznych WCAG 2.0.
Znowu implementacja.
? Interfejs użytkownika ? zastosowanie wytycznych dotyczących wyglądu stron internetowych i aplikacji udostępniających e-usługi.
Znowu implementacja.
? Bezpieczeństwo i niezawodność ? zapewnienie bezpieczeństwa danych w warstwie technologicznej oraz pewności prawa w trakcie świadczenia usługi.
Tego nie rozumiem. Co ma Obywatel do “danych w warstwie technologicznej”, jak mam rozumieć pojęcie “pewności prawa w trakcie świadczenia usługi”?
? Otwartość na integracje ? dostarczenie API, które pozwoli wpiąć Twoją usługę do większego pakietu i/lub zintegrować ją z portalem GOV.PL
Integrację z czym skoro obywatel to “aktor” systemu? Czy chodzi o to, że państwo ma świadczyć usługi nie tylko Obywatelom ale także “zewnętrznym systemom”? Może warto to doprecyzować?
3 Zasady budowy cyfrowych usług publicznych
Tu pojawiają się elementy dla mnie niezrozumiałe, które skomentuję.
1. Sprawdź, czego potrzebują odbiorcy (projektowanie usług)
Odbiorcy, czyli rozumiem Obywatele/Klienci (słownik pojęć by się przydał). Tak się składa, że Urzędy działają na podstawie prawa więc nie bardzo wiem co tu jeszcze z nimi ustalać?
2. Minimalizuj obciążenia po stronie użytkownika (projektowanie usług)
To bardzo ogólnie sformułowane wymagania “pozafunkcjonalne”, jednak brak kryterium pozwalającego stwierdzić czy zostało wykonane, pozostaje oświadczenie “minimalizowaliśmy”.
3. Pamiętaj, że usługa jest procesem (projektowanie usług)
Jeżeli na początku czytamy, że “załatwianiu SPRAWY KLIENTA, a nie załatwieniu SPRAWY PRZEZ KLIENTA” to tu autor zaprzecza sam sobie.
4. Pozyskuj od klientów tylko niezbędne dane (projektowanie usług)
Jeżeli wcześniej napisano, że Państwo nie może żądać od Obywatela danych które juz posiada, to ten zapis jest chyba zbędny.
5. Projektuj uniwersalne usługi dla wszystkich odbiorców (projektowanie usług)
To także chyba oczywistość?
Podsumowanie
Niestety nie było moim celem komentowanie całości, byłyby to zbliżone do powyższych komentarze. Cały dokument wygląda troszkę jak atrapa “Manifestu Agile”. Dokument jest nieprecyzyjny i nie wiem jak wyglądało by korzystanie z niego. Warto zwrócić uwagi na potrzebę uporządkowania pojęć i domeny problemu:
Takie pojęcia jak korzyść obywatela czy potrzeba obywatela są nie tylko nieprecyzyjne ale i nadmiarowe w moich oczach. System świadczący obywatelowi usługi to, z perspektywy tego obywatela, “coś” co wyda z siebie coś na żądanie, które to żądanie należy poprawnie sformułować. I nic więcej.
Powyższe to szkielet takiego systemu. Co do zasady mamy tu metausługę mającą jako instancje konkretne usługi, metaklienta mającego dwie instancje: człowieka korzystającego z GUI oraz aplikacje korzystającą z API.
Konkluzja 1.: usługę świadczy Państwo więc nie widzę innej możliwości by złożenie podania miało sie odbyć inaczej niż przez GUI.
Konkluzja 2.: rejestrami są także Archiwa, więc śledzenia stanu spraw nie powinno być kłopotem.
Konkluzja 3.: skoro proces wewnętrzny ma być ukryty przez Obywatelem, to znaczy że nie bierze on w ogóle z nim udziału, czyli te System nie jest aplikacją “workflow” z perspektywy Obywatela.
Na zakończenie
W projektach, których celem jest z jednej strony porządkowanie opisu systemów od strony wymagań na nie, a z drugiej narzucenie pewnych rygorów na ich projektowanie, wygodną metodą jest użycie modeli kontekstowych (tu przypadki użycia) oraz tworzenie tak zwanych polityk, czyli zestawu reguł, zasad narzucających ograniczenia np. na architekturę, metody integracji itp. Do tego korzystanie na tym etapie z metamodeli skojarzonych z tymi politykami, powinno pomóc w utrzymaniu prostoty dokumentu. Obecna postać dokumentu stanowi pewne przemieszanie tych treści. Wstęp to w zasadzie rodzaj preambuły. Kolejny rozdział nazwał bym raczej wymaganiami biznesowymi a nie “metaregułami”, z powodu opisanego wyżej. Rozdział 3. to jakaś niedoprecyzowana forma przekazania dobrych praktyk i wzorców oraz, co wskazałem, także tych mniej dobrych. Bardzo zaskoczyła mnie “algorytmizacja” projektowania, która notabene kłóci się z zasadą: usługa a nie angażowanie obywatela w proces. Ten “algorytm” (czemu algorytm a nie proces?) angażuje obywatela w proces realizowania usługi w kilku miejscach.
Wokół metod zwinnych narasta wiele mitów, szczególnie tych o skuteczności w dużych projektach. Dzisiaj kolejne kilka słów o popularnym narzędziu jakim jest tak zwane “user story” czyli historyjka użytkownika, o ich ewolucji i o tym, że mogą być przydatne i kiedy.
Co prawda, jako źródło informacji wolę dokumenty, ale bywa, że tym źródłem informacji są jednak użytkownicy, bo dotyczy to projektowania np. nowych portali biznesowych. Tu niestety nie ma ani ustaw z wzorami dokumentów ani “dotychczasowego papierowego obiegu dokumentów”. Bardzo podobnie wyglądają start-up’y w obszarze operacyjnym. Podobnie wygląda analiza i projektowanie systemów wspierających obsługę klientów (CRM i podobne). Dlaczego? Bo tej sfery nie regulują ani przepisy ani żadne normy. Nie licząc elementów prawa cywilnego, są całkowicie uznaniowe.
User Story
Historyjki użytkownika, mają swój rodowód w EX (programowanie ekstremalne) i są z reguły definiowane tak:
In software development and product management, a user story is a description consisting of one or more sentences in the everyday or business language of the end user or user of a system that captures what a user does or needs to do as part of his or her job function (źr. ang. wiki).
Scott Ambler pisze:
User stories are one of the primary development artifacts for Scrum and Extreme Programming (XP) project teams. A user story is a very high-level definition of a requirement, containing just enough information so that the developers can produce a reasonable estimate of the effort to implement it. ?1?
Generalnie jest to opis w potocznym języku, ten – z uwagi na niejednoznaczność – jako wymaganie, stwarza problemy. Podejmowane są próby formalizowania tych historyjek. Pisze o tym autor bloga QAgile (podając przykłady, polecam cały artykuł):
W podejściu agile takim jak Scrum wymagania definiujemy na ogól w postaci User Story. Prosta forma, która ma adresować oczekiwania i potrzeby użytkowników często zespołom przysparza dużo problemów w implementacji.?2?
Swego czasu ja także pisałem o efektach stosowania tej metody z zbytnią ufnością w jej skuteczność:
Niedawno po raz kolejny widziałem negatywne skutki tego podejścia, tym razem był to wdrażany i zakończony porażką (projekt przerwano) obieg dokumentów, nie tylko kosztowych, więc postanowiłem do tamtego artykułu dodać coś jeszcze: wymagania zbierano tu z w postaci “user story”.[…]
Tak więc opisowe user story może być wymaganiem biznesowym, testem ale raczej nie specyfikacją tego co ma powstać. Bez analizy pozwalającej wyspecyfikować wymagania dziedzinowe (logikę wewnętrzną) nie mamy szans na sprawne stworzenie oprogramowania wykraczającego poza prosty zestaw kartotek i rejestrów.?3?
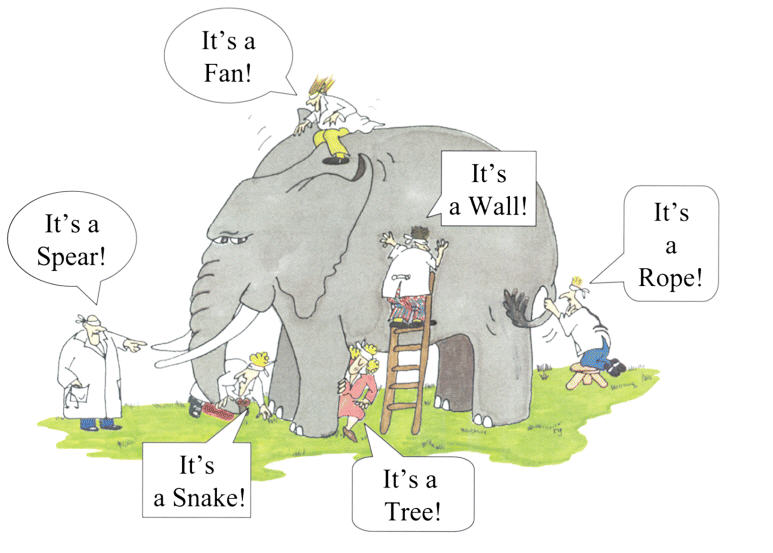
User story to opis z perspektywy użytkownika. Najlepszą chyba metaforą będzie tu znana anegdota z opisywaniem słonia:
Każdy z tych okrzyków to odrębne user story.
Wszelkie metody zakładające, że użytkownik wie czego chce i jest najlepszym źródłem “wymagań” bazują na zaufaniu dla tych opisów.
I tu wpadamy w efekt ?kręcenia filmu?. Najczęściej tak zwana analiza wygląda tak, że pracownicy analizowanej firmy, w toku warsztatów lub wywiadów, opowiadają z jakimi to sytuacjami mają do czynienia, co robią, kiedy i jak, opisując konkretne przypadki z jakimi mieli do czynienia i to, jak sobie z nimi poradzili. Do tego dochodzą przypadki, w których sobie słabo poradzili, przypadki tego jak sobie radzą z tym, że czegoś nie rozumieją, a to wszystko jest okraszone sposobami pracy wynikającymi nie raz z niewiedzy, nieznajomości prawa czy wewnętrznych regulacji. Na domiar złego, nie raz można się spotkać z przypadkami, w których opowiadający o swojej pracy wplata elementy pozwalające mu na działania niepożądane takie jak upraszczanie procedur lub wręcz łamanie prawa (np. swego czasu pewien urzędnik na moich oczach w trakcie warsztatów zgłosił jako wymaganie wobec systemu obiegu dokumentów, możliwość podpisania orzeczenia sędziego przeterminowanym podpisem elektronicznym!).?4?
Historyjki użytkownika mają sens, jednak nie jako “kompletny opis wymagań na aplikację” (wczoraj usłyszałem, że w pewnej dużej instytucji zebrano już ok. tysiąca (!) takich historyjek i proces ten nadal trwa). Mają jednak sens jako “sample” do analizy. Przekazywanie takich historyjek bezpośrednio developerowi jest ogromnym ryzykiem. Dlaczego? Historyjka, nawet w sformalizowanej formie, niesie tylko subiektywne “spojrzenie z zewnątrz”, a programista zaczyna domyślać się i gdybać, niejednokrotnie przekraczając dozwolone granice:
…?jako sprzedawca, dostaję od klientów zamówienia, na podstawie których muszę wystawiać faktury VAT?, do tego analityk doda, np. po analizie otrzymanej partii dokumentów, strukturę zamówienia i faktury VAT oraz ?algorytm? wyliczenia podatków. Jeżeli programista zaczyna ?lepiej wiedzieć? od zamawiającego, forsując np. prostszą implementację, to znaczy, że przekroczył swoje kompetencje, sam sobie ? jako developerowi ? robi krzywdę psując to oprogramowanie bo klient i tak prędzej czy później na tych uproszczeniach ?polegnie?.?3?
Bywa bardzo często, że programista bez żadnego oporu przyjmuje historyjkę: “ja jako sprzedawca, chcę umieścić na fakturze towar, którego nie ma jeszcze w magazynie, w celu zaliczenia sprzedaży w danym dniu” … (Komentarz zbędny…)
Czy to znaczy, że należy odejść całkowicie od tego narzędzia? Moim zdaniem nie. Wystarczy uznać , że “user story” to WYŁĄCZNIE opis z perspektywy użytkownika, swoiste “jedno spojrzenie z setek możliwych”.
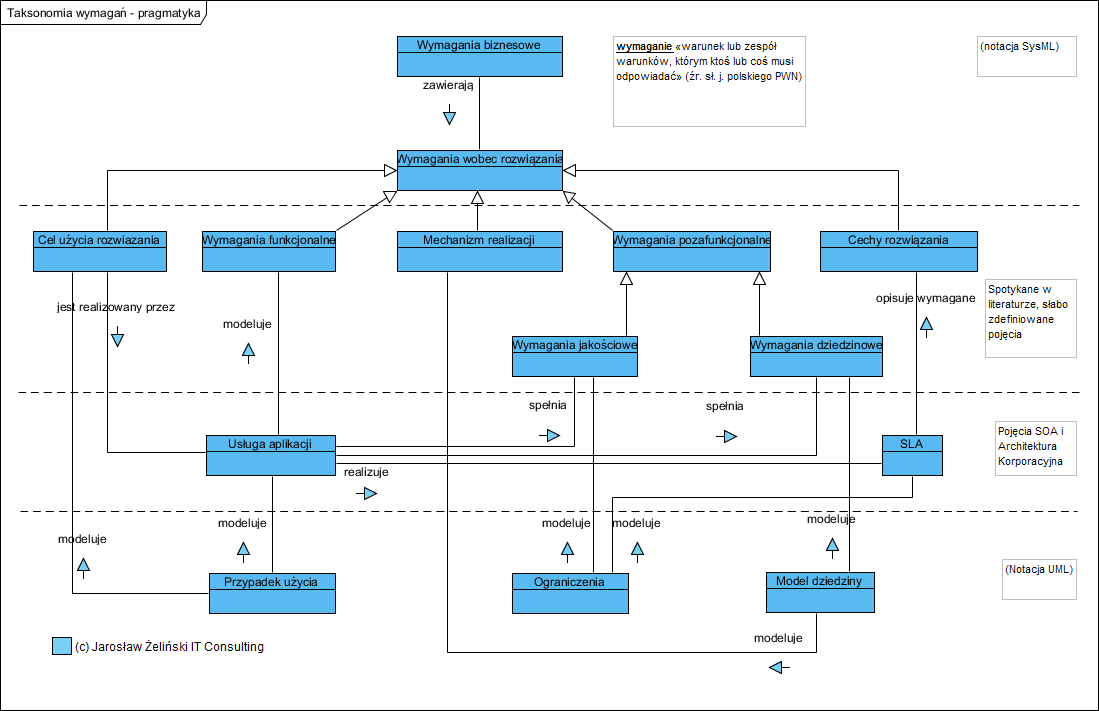
Swego czasu opisałem taksonomię pojęć stosowanych w analizie wymagań:
Taksonomia wymagań na system (źr. opracowanie własne Jarosław Żeliński)
U szczytu tej hierarchii mamy wymagania biznesowe. Są to w zasadzie owe historyjki użytkownika. To wyrażone językiem zamawiającego, oczekiwania w stosunku do oprogramowania. Rolą analityka jest takie przeanalizowanie i przetworzenie tych opisów, by doprowadzić do powstania sformalizowanego opisu (np. w postaci modeli UML: przypadki użycia, model dziedziny, ograniczenia, inne) czyli do postaci specyfikacji usług aplikacji i logiki (mechanizmu) działania tej aplikacji.
Kolekcjonowanie wymagań biznesowych w postaci np. user story, ma sens jako zbieranie “sampli”, przykładowych sytuacji. Na ich podstawie, w toku analizy, można tworzyć modele i testować te historyjki (stają się scenariuszami testowymi). Tu polecam między innymi blog i książki Scotta Amblera:
In this episode, Scott Ambler helps us to understand the power of using models and how to use models in an agile environment.?5?
Wspominałem nie raz o nim i o jego książkach na tym blogu:
Co prawda książka ma 12 lat i trzeba brać na to lekka poprawkę, jednak jest to wartościowa, nafaszerowana diagramami UML, książka traktująca o tym, że zwinność nie oznacza bałaganu i pospolitego ruszenia. Scott Ambler to kolejny autorytet w inżynierii oprogramowania. I mimo, że nikogo nie ma sensu małpować, na pewno warto się uczyć? ?6?
Ostatnio popularność zdobywa podejście sformalizowane do historyjek użytkownika, bazujące na koncepcji Scott’a Amblera (modelowanie) i Rona Jeffries’a, zwolennika porządkowania, nie tylko treści wywiadów ;). Tu posłużę się ilustracjami z artykułu na stronie Visual Paradigm.
User story is one of the most important tool for agile development. They are often used for identifying the features of a system under developed. User stories are well compatible with the other agile software development techniques and methods, such as scrum and extreme programming. […]
Concept of 3C’s
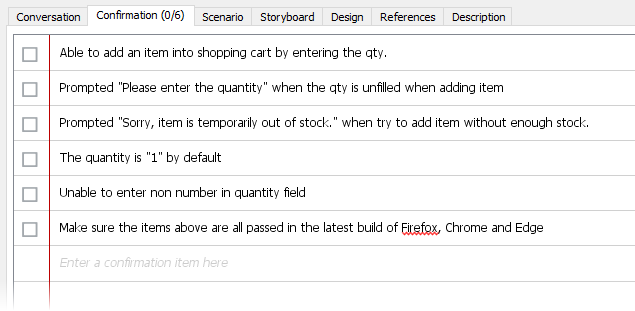
The 3C’s refer to the three critical aspects of good user stories. The concept was suggested by Ron Jeffries, the co-inventor of the user stories practice. Nowadays, when we talk about user stories, we usually are referring to the kind of user stories that are composed of these three aspects: Card – User stories are written as cards. […] Conversation – Requirements are found and re-fined through a continuous conversations between customers and development team throughout the whole software project. […] Confirmation – or also known as Acceptance criteria of the user story. […]?7?
W dużym skrócie: historyjki dzielimy na jednostkowe elementarne (niepodzielne) opisy w postaci “kart”, zawierających opis tego czego zamawiający oczekuje od aplikacji, zapis uwag (konwersacja) dotyczących kolejnych dyskusji z zamawiającym na temat danej historyjki to historia ustaleń, opis oczekiwanego uzyskanego efektu czynności opisanych w danej historyjce potwierdzenie uzyskania oczekiwanego efektu. Idąc zaś za wskazówkami Amblera, implementację poprzedzamy pracą nad koncepcją implementacji posługując się modelami na dość wysokim poziomie abstrakcji.
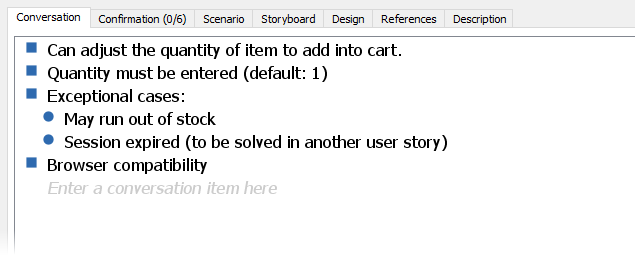
Karta historyjki to prosty zapis utrzymany w konwencji “ja jako <<aktor>>, chcę <<nazwa czynności>> w celu <<oczekiwany efekt>>. Osobiście w projektach dopuszczam bardziej “luźną” formę takiej historyjki, jednak pilnuje co do zasady, by dotyczyła wyłącznie jednego “uzyskanego efektu końcowego”. Każda karta ma unikalne oznaczenie, jest bowiem używana jako jedno zadanie, w backlogu i sprintach (kanban). W dokumentacji (wspomniane narzędzie VP) user story wygląda to tak:
Historyjki mają swój cykl życia i dobrą praktyką jest rejestrowanie wszelkich kolejnych uzgodnień w toku pracy:
Tak zapisujemy “słowotok” zamawiającego na temat jego wizji realizacji danej usługi aplikacyjnej. Analogicznie zapisujemy opis oczekiwanego efektu końcowego:
Do tego momentu mamy “klasyczne” zwinne prowadzenie projektu z jego wadami opisanymi powyżej.
Wymagania powinny być “spójne, kompletne i niesprzeczne”
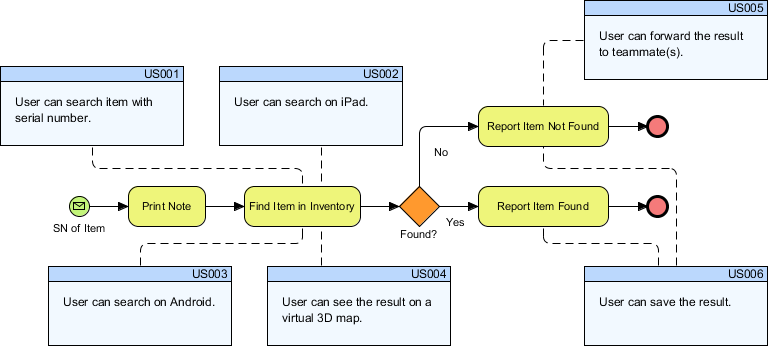
Jak to osiągnąć? Analityk zaczyna zbierać te historyjki i zaczyna składać z nich kompletny proces biznesowy. Stanowi on weryfikator, czy całość (zestaw takich historyjek) stanowi jakąś spójną, kompletną i niesprzeczną logikę biznesową w skali całej firmy. Zmorą projektów są wymagania odkrywane w toku wdrożenia, dlatego warto poświęcić czas na weryfikację pomysłu na całość systemu i zweryfikować spójność i kompletność tej całości z pomocą utworzenia modelu każdego całego procesu:
Warto modelować proces gdyż wtedy widać, że nie zawsze prawdą jest, że jedna (każda) historyjka jest odrębnym przypadkiem użycia. Przypadki użycia wyprowadza się z elementarnych aktywności jeden do jednego, co z uzasadnieniem opisywałem w artykule Transformacja…. Model procesu biznesowego daje kontekst, pozwala lepiej zrozumieć “sens” całości. Czy powyższy model procesu (notacja BPMN) z naniesionymi historyjkami, nie przypomina Wam wyników badania słonia? Tu słoń został przez analityka odkryty: to proces biznesowy (jego model w notacji BPMN). Przypadkami użycia będą elementarne aktywności w procesie. Więcej na temat zwinnego prowadzenia projektu z użyciem user story można znaleźć w tutorialu Agile handbook.
Na zakończenie…
(źr. Martin Fowler, Analysis Patterns, 1997)
We are called ?analysts? for a reason! We don?t merely hear stories and convert them into ?requirements?. Our integrated value lies in going above and beyond the story and expanding beyond engendering deliverables. We coalesce critical thinking and intellectual curiosity to transform stories into abstracts and to propose the needs as well as what the problem really is.?1?
[2022-12-03] Niedawno znalazłem te prezentację, polecam:
Każdy analityk to nie tylko pisarz ;), to także, a nawet przede wszystkim, projektant. To także ktoś, kto dba o prawa (powinien!) swoich klientów. Dlatego gorąco polecam każdemu, kto w projektach tworzy dokumenty, lub jest odpowiedzialny za ich tworzenie, tę lekturę. W szczególności rozdziały I do V, opisujące istotę praw autorskich i pokrewnych, prawa pokrewne i ochronę baz danych.
Często słyszę, że to domena prawników, otóż nie. Domeną prawnika jest pilnowanie zgodności dokumentów z szeroko-pojętym prawem cywilnym (autorskim owszem także), ocena ryzyka podpisania danej umowy itp. Jednak niestety prawnicy (z bardzo rzadkimi wyjątkami) nie rozumieją tego czym jest baza danych, projekt architektury oprogramowania, model logiki biznesowej, notacje UML czy BPMN, kod programu (ten postrzegają wyłącznie jako dzieło literackie, co jest tylko częścią prawdy). Nałożenie na to wszystko ochrony know-how naszych klientów (ustawa o zwalczaniu nieuczciwej konkurencji) powoduje, że problem przestaje być trywialny. Do tego należy dodać ogromna ilość nadużyć firm wdrażających oprogramowanie i dedykowane i gotowe (zawłaszczanie praw i przejmowanie know-how).
W szóstym wydaniu opracowania przedstawiono całość problematyki prawa autorskiego. Książka może więc stanowić przewodnik po polskim i międzynarodowym prawie autorskim. Cenne dla czytelników jest omówienie bardzo istotnych w praktyce kwestii związanych z właściwym redagowaniem umów z zakresu prawa autorskiego. Autorzy wiele uwagi poświęcają też stosowaniu prawa autorskiego w internecie, a także: pojęciu utworu w prawie Unii Europejskiej, dyrektywie o dziełach osieroconych, zagadnieniu wolnego dostępu. (Źródło: Prawo autorskie i prawa pokrewne – Janusz Barta, Ryszard Markiewicz).