[[Analiza wymagań]] to temat rzeka, metody są różne ale nie będę pisał o znanych mi, tylko o pewnym podejściu “systemowym” zorientowanym na modele i wzorce projektowe. Ale po kolei.
Ile mamy poziomów szczegółowości wymagań
Poziom szczegółowości wymagań jest tematem wielu dyskusji, pisałem tu już nie raz na ten temat. Tym razem nie o tym, że zarządzanie tysiącami detali dużych pakietów oprogramowania jest niemożliwe (i nieracjonalne). Tym razem o tym, że stosowane wzorców, tu analitycznych i projektowych, pomaga. Najpierw kilka słów o poziomach szczegółowości, które stosuję:
- Najwyższy poziom abstrakcji to nazwanie celu biznesowego np. chcemy sprawnie wystawiać faktury VAT. Jedno zdanie, bez szczegółów. To najczęściej jest cel sponsora projektu, którym jest niejednokrotnie ktoś z zarządu.
- Kolejny etap to doprecyzowanie tego wymagania, w tym momencie powołujemy się albo na przepisy, które opisują to wymaganie wystarczająco szczegółowo (np. Ustawa o podatku VAT i Ustawa o rachunkowości). Jeżeli nie mamy na co się powołać poszerzamy ten opis sami. Tu mamy do czynienia z usługą systemu z perspektywy zamawiającego a z [[przypadkiem użycia]] z perspektywy oprogramowania.
- Jeżeli oprogramowanie miało by być wykonane na zamówienie, powstaje dodatkowo uszczegóławiający opis każdej usługi zawierający: dane wejściowe i oczekiwane dane wyjściowe, wzory formularzy do wprowadzania danych i wzór produktu (tu wzór faktury) oraz scenariusz użycia czyli oczekiwania zamawiającego co do sposobu pracy z przyszłym programem. Opis taki robi analityk-projektant a jako źródło informacji występuje ekspert dziedzinowy (często przyszły użytkownik).
I tu zaczyna się ciekawszy ciąg dalszy. [[Przypadki użycia]] to tak zwany [[opis czarnej skrzynki]], nic nie mówi o logice jaką chcemy odtworzyć, wbudować do nowego oprogramowania. Pojawia się ważne pytanie: jaką “wiedzę” ma mieć to oprogramowanie? Przypadki użycia kojarzy się z tak zwanymi Aktorami systemu. Są to określone role, które będą wykonywane przez użytkowników (np. Specjalista ds. Handlowych może pełnić rolę fakturzysty – aktorem jest Fakturzysta). Dopiero po zdefiniowaniu wiedzy jaką ma (ma mieć) Aktor, mamy podstawy definiować “wiedzę” jakiej oczekujemy do oprogramowania (to czego nie potrafi Aktor).
Czarna skrzynka (wyłącznie przypadki użycia) jako wymaganie jest bardzo ryzykownym narzędziem, bo nie definiuje tego jaką “wiedzę” ma mieć (odtwarzać) to oprogramowanie. Tu potrzebne jest określenie z czego będą powstawały oczekiwane produkty (co jest potrzebne do wystawiania faktury VAT, np. produkty i usługi zna fakturzysta czy ma je podpowiadać oprogramowanie).
Potrzebny jest więc opis logiki biznesowej, którą chcemy zaimplementować. Ten opis to sedno problemu pracy analityka.
I przyszła pora na “analizę”. Powszechnie nadużywane słowo analiza oznacza:
analiza [gr. análysis ?rozłożenie?, ?rozbiór?], rozłożenie pewnego obiektu na elementy składowe (części, cechy, relacje); może być zabiegiem fizycznym lub czynnością myślową; (za Encyklopedia PWN).
Słowo klucz: “elementy składowe”. W metodach pracy, które stosuję, powyższe jest podstawowym “narzędziem” pracy. Ale tu małe wyjaśnienie: niestety większość spotykanych dokumentów analitycznych, nie wiele ma wspolnego z analizą. Dlaczego? Skoro analiza to “rozłożenie na elementy składowe”, to czym jest zapis życzeń i oczekiwań wyartykułowany ustami pracowników jakiejś firmy czy organizacji na spotkaniach, w postaci tekstu, tabel lub nieformalnych obrazków ? Jest po prostu jakimś spisem ale na pewno nie analizą.
Żeby dokonać jakiejkolwiek analizy musimy sobie najpierw zdefiniować jakieś “elementy składowe”. Analiza zdania polega na wyodrębnieniu słów, kojarzeniu ich w związki itp. ale początkiem jest istniejący słownik i reguły gramatyczne. Analiza chemiczna to rozłożenie substancji na z góry znane pierwiastki (pomijam ich odkrywanie). Czym jest analiza biznesowa czy analiza wymagań?
Analiza procesów biznesowych wymaga zrozumienia tego co dzieje się w analizowanej firmie i rozłożenie tego na predefiniowane elementy składowe. W zasadzie mamy jeden: proces biznesowy. Jego definicja określa atomowy element takiej analizy. Jeżeli patrzymy więc diagram zawierający prostokąty i linie będące graficznym zapisem tego “co powiedziano”, nie jest to żaden wynik analizy ani model a jedynie obrazkowy zapis opowieści.
Dalej: projektowanie oprogramowania. Na czym polega analiza obiektowa i projektowanie? Po pierwsze znowu potrzebne są “elementy składowe” (przypominam, że ma być ich skończona liczba, mają zdefiniowane znaczenia, które się na siebie nie nakładają (nic nie może pasować do dwóch definicji jednocześnie) i pozwalają, z ustalona dokładnością, na zbudowanie analizowanej całości.
Przykład
Opiszę jak można prowadzić analizę i budować część wymagań o nazwie model dziedziny (model logiki biznesowej).
Zgodnie z powyższym należy zacząć od zdefiniowana sobie skończonej liczby klocków (ich typów). Np. LEGO, można z nich zbudować “wszystko” akceptując pewną granice w odtwarzaniu uszczegółów. Typów podstawowych klocków jest kilka a jednak można z nich zbudować dom, samolot czy kaczkę:

Analiza polega na tym, by realny dom lub kaczkę rozłożyć na skończona liczbę (z reguły nie wielką) prostych elementów składowych, których “słownikiem” jest posiadany zestaw LEGO. Wynikiem analizy jest “dokument” w postaci instrukcji “jak złożyć domek z LEGO”. Innymi słowy, mamy skończoną liczbę elementów “budulcowych” analiza polega na zrozumieniu problemu, rozłożeniu go na takie właśnie elementy.
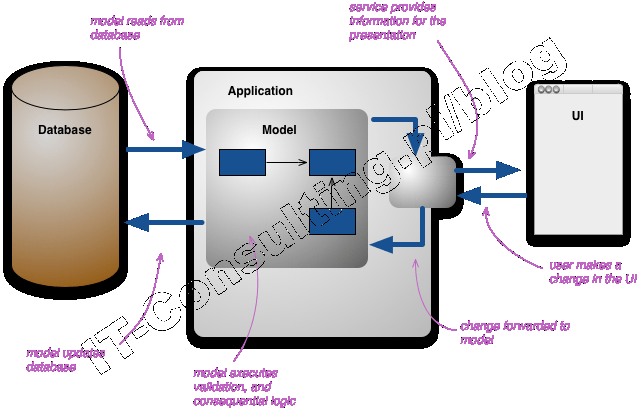
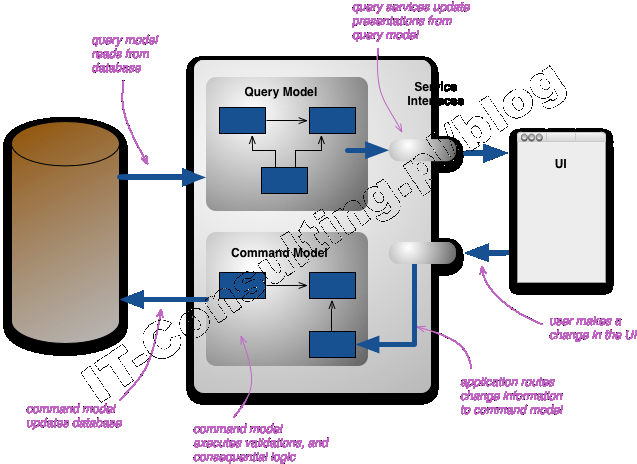
Osobiście jestem zwolennikiem stosowania [[wzorca projektowego MVC]] oraz stylu analizy i projektowania zwanego DDD (ang. [[Domain Driven Design]], projektowanie sterowane dziedziną systemu, artykuł o DDD). DDD to wzorce zarówno analityczne jak i projektowe. Te wzorce to właśnie takie atomowe “klocki”.
Na etapie analizy, “rozkładamy” analizowaną firmę (jej część) na elementarne składniki. W DDD są to pojedyncze encje i ich agregaty, typy (value-object), usługi, fabryki, repozytoria. Analiza polega na opisaniu (rozłożeniu jej ) całej logiki oprogramowania z pomocą tych kilku standardowych “klocków”. Model taki dla developera staje się projektem, a te klocki wzorcami projektowymi.
Poniżej “zabawowy” przykład takiej analizy.

Aktorem jest użytkownik. Potrzebny mu jest “system” który da mu przedmiot wykonany z klocków LEGO (domek). System całkowicie izoluje Aktora od swojego wnętrza z pomocą Recepcji (View w modelu MVC). Wewnątrz mamy zestaw klocków (encje, agregaty), delikwenta wiedzącego jak wykonać domek (usługa) oraz fabrykę klocków (na bazie wzorców tworzymy ich tyle ile potrzebujemy, ile zażąda usługodawca).
Aby zachować wytworzone klocki a także wyniki prac czy półprodukty, musimy mieć pudełko na klocki: repozytorium. Nad całością czuwa Kontroler, ekipa ludzi zajmująca się wszystkimi “poza specjalistycznymi” (poza-dziedzinowymi) zadaniami. Z racji tego, że takie pojęcia jak wydajność, zasoby, bezpieczeństwo itp. są uniwersalne, taka ekipa back office (skrzynka na zabawki, recepcja, kontroler) może zostać wynajęta niemalże dla każdej firmy bez względu na branże (to się nazywa framework). Specyficzna jest tylko dziedzina, tu typ klocków.
Tak więc analiza wymagań na oprogramowanie to lista wymaganych usług. Wymagania na dedykowane oprogramowanie zaś to nie jest spisanie i sortowanie oczekiwań. Analiza to rozłożenie problemu (firma klienta) na klocki zgodne z uznaną (używaną) metodyką i wzorcami. DDD (opis wzorców projektowych DDD) to właśnie jeden z takich zestawów klocków.
Wynikiem analizy jest model (a nie tylko obrazek) opisujący jak działa analizowana firma, zbudowany z klocków, tu opisanych w DDD.
Dla developera taki model jest projektem logicznym ([[Platform Independent Model w nomenklaturze OMG/MDA]]). W efekcie analityk nie tylko zrozumiał i udokumentował problem, analityk zaprojektował logikę biznesową oprogramowania, możliwą do bezpośredniej implementacji przez developera (przy założeniu, że stosuje metody obiektowe i zna użyte wzorce). Taki efekt dają metody obiektowe i pragmatyki np. DDD. Za to właśnie bardzo lubię obiektowy paradygmat i DDD: “obiektowość” zrównuje wynik analizy z projektem, DDD daje nam zestaw klocków: słownik pojęć, zrozumiały dla “biznesu” i dla developera. DDD to zestaw wzorców pozwalający na dogłębne zrozumienie analizowanego problemu i będące zarazem projektem jego implementacji.
Kim więc jest dobry analityk?
Jest to ktoś, kto potrafi analizowaną organizację “rozłożyć na elementy składowe”. Tymi elementami są wzorce projektowe, elementy stosowanej notacji. Wynik analizy to nie “rysunek”, to model w postaci schematu blokowego (diagramu), na którym każdy element ma ściśle określone znacznie, konstrukcję i zasady wzajemnego łączenia i oddziaływania.
Analiza Biznesowa to rozłożenie analizowanego “przedmiotu” na skończony zestaw elementów, który z określoną dokładnością zachowuje się tak, jak analizowana organizacja. Jeżeli te elementy składowe mają także swoje odwzorowanie w kodzie programu, to wynik analizy staje się projektem tego oprogramowania.
Więc poziomy szczegółowości wymagań to:
- cele biznesowe (produkty procesów biznesowych)
- opis usług żądanych od oprogramowania (tu także formatki papierowe/ekranowe, przypadki użycia oprogramowania)
- opis (projekt) wewnętrznej logiki biznesowej (wewnętrzne elementy składowe i scenariusze ich współdziałania)
P.S.
Artykuł ma charakter “badawczy”, wszelkie uwagi mile widziane.